 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
DiscoScore: Evaluating Text Generation with BERT and Discourse Coherence
Jan 28, 2022
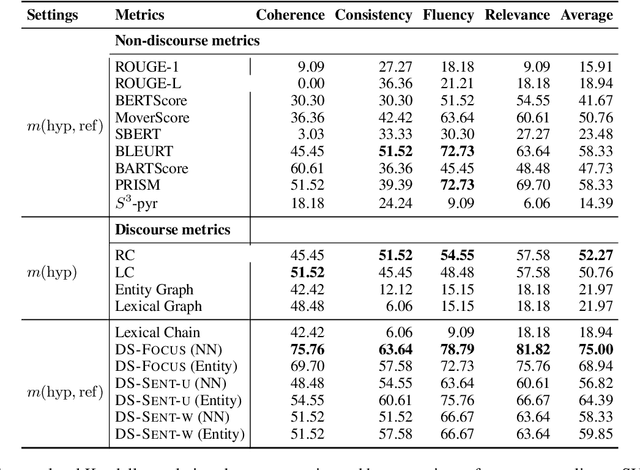
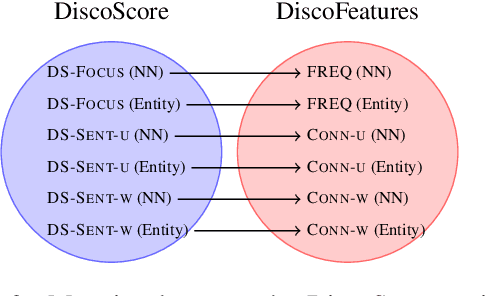
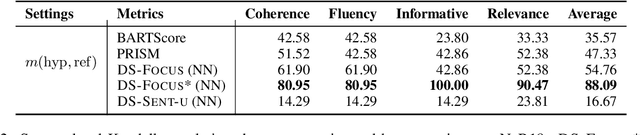
Recently, there has been a growing interest in designing text generation systems from a discourse coherence perspective, e.g., modeling the interdependence between sentences. Still, recent BERT-based evaluation metrics cannot recognize coherence and fail to punish incoherent elements in system outputs. In this work, we introduce DiscoScore, a parametrized discourse metric, which uses BERT to model discourse coherence from different perspectives, driven by Centering theory. Our experiments encompass 16 non-discourse and discourse metrics, including DiscoScore and popular coherence models, evaluated on summarization and document-level machine translation (MT). We find that (i) the majority of BERT-based metrics correlate much worse with human rated coherence than early discourse metrics, invented a decade ago; (ii) the recent state-of-the-art BARTScore is weak when operated at system level -- which is particularly problematic as systems are typically compared in this manner. DiscoScore, in contrast, achieves strong system-level correlation with human ratings, not only in coherence but also in factual consistency and other aspects, and surpasses BARTScore by over 10 correlation points on average. Further, aiming to understand DiscoScore, we provide justifications to the importance of discourse coherence for evaluation metrics, and explain the superiority of one variant over another. Our code is available at \url{https://github.com/AIPHES/DiscoScore}.
Impact of Target Word and Context on End-to-End Metonymy Detection
Dec 06, 2021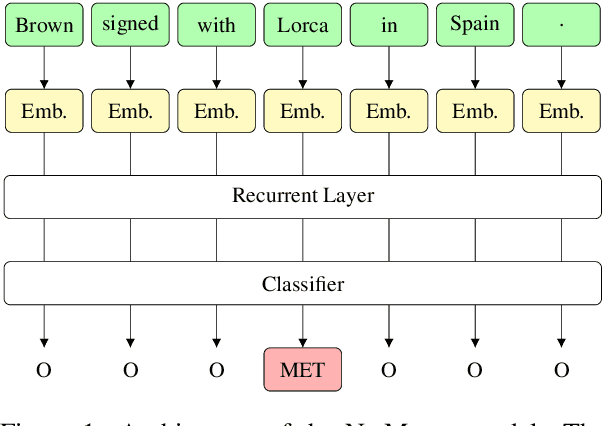
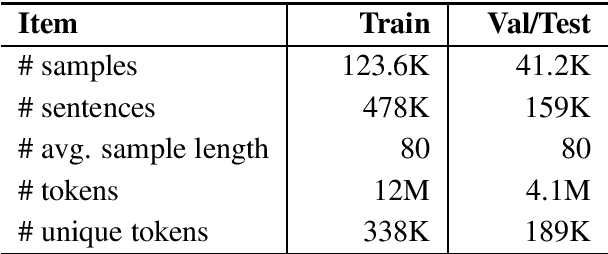
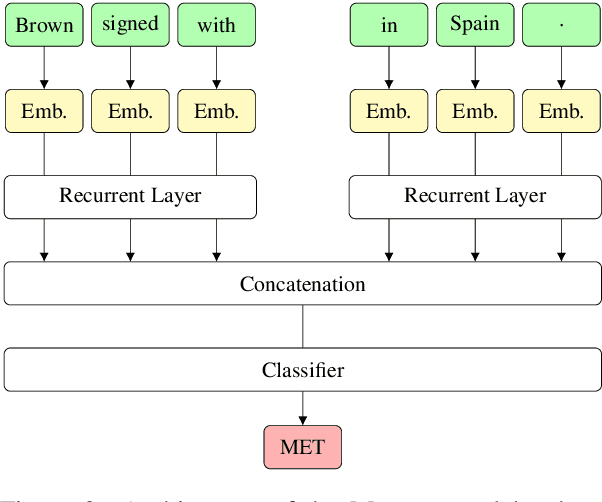
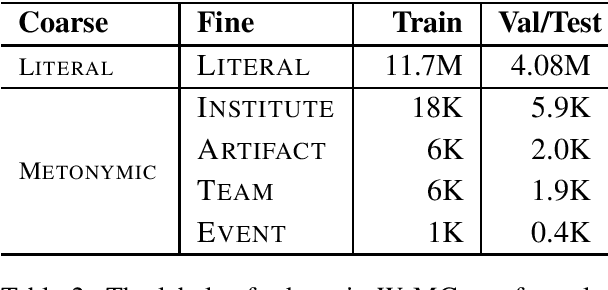
Metonymy is a figure of speech in which an entity is referred to by another related entity. The task of metonymy detection aims to distinguish metonymic tokens from literal ones. Until now, metonymy detection methods attempt to disambiguate only a single noun phrase in a sentence, typically location names or organization names. In this paper, we disambiguate every word in a sentence by reformulating metonymy detection as a sequence labeling task. We also investigate the impact of target word and context on metonymy detection. We show that the target word is less useful for detecting metonymy in our dataset. On the other hand, the entity types that are associated with domain-specific words in their context are easier to solve. This shows that the context words are much more relevant for detecting metonymy.
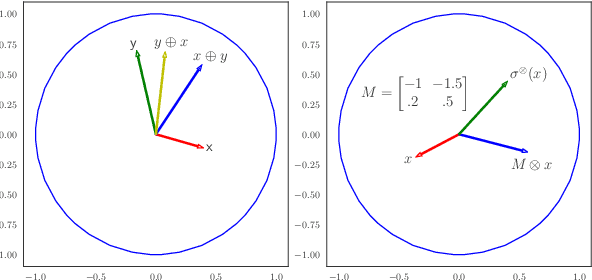
Vector-valued Distance and Gyrocalculus on the Space of Symmetric Positive Definite Matrices
Oct 26, 2021
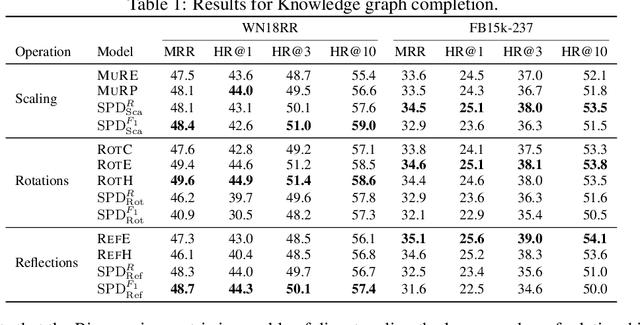
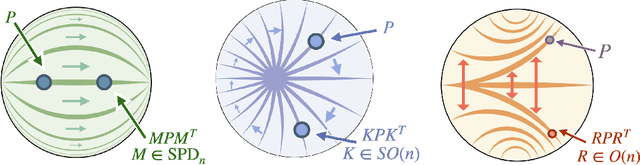
We propose the use of the vector-valued distance to compute distances and extract geometric information from the manifold of symmetric positive definite matrices (SPD), and develop gyrovector calculus, constructing analogs of vector space operations in this curved space. We implement these operations and showcase their versatility in the tasks of knowledge graph completion, item recommendation, and question answering. In experiments, the SPD models outperform their equivalents in Euclidean and hyperbolic space. The vector-valued distance allows us to visualize embeddings, showing that the models learn to disentangle representations of positive samples from negative ones.
Augmenting the User-Item Graph with Textual Similarity Models
Sep 20, 2021

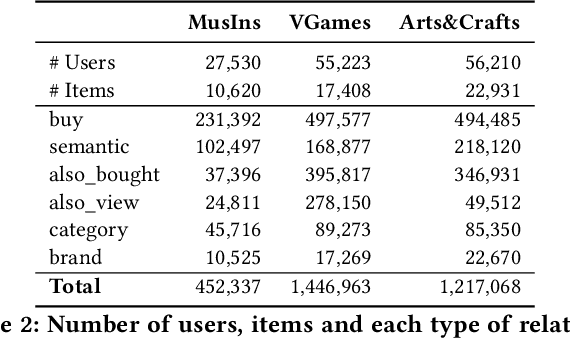
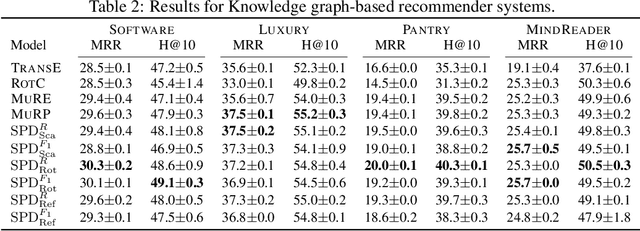
This paper introduces a simple and effective form of data augmentation for recommender systems. A paraphrase similarity model is applied to widely available textual data, such as reviews and product descriptions, yielding new semantic relations that are added to the user-item graph. This increases the density of the graph without needing further labeled data. The data augmentation is evaluated on a variety of recommendation algorithms, using Euclidean, hyperbolic, and complex spaces, and over three categories of Amazon product reviews with differing characteristics. Results show that the data augmentation technique provides significant improvements to all types of models, with the most pronounced gains for knowledge graph-based recommenders, particularly in cold-start settings, leading to state-of-the-art performance.
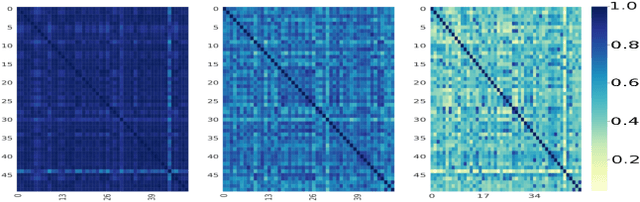
Symmetric Spaces for Graph Embeddings: A Finsler-Riemannian Approach
Jun 09, 2021
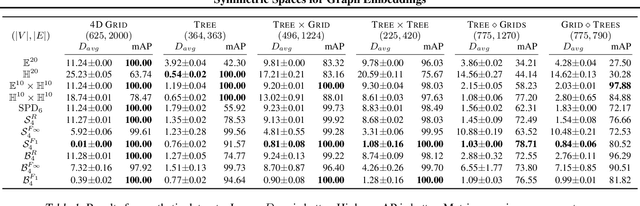
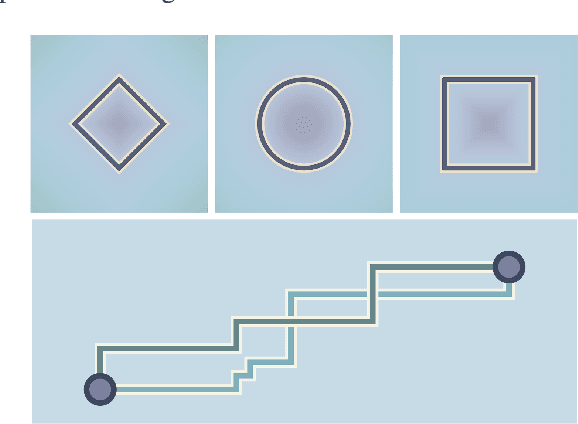
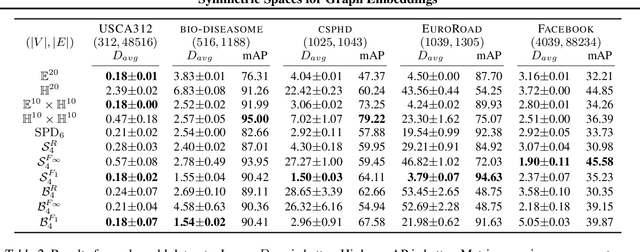
Learning faithful graph representations as sets of vertex embeddings has become a fundamental intermediary step in a wide range of machine learning applications. We propose the systematic use of symmetric spaces in representation learning, a class encompassing many of the previously used embedding targets. This enables us to introduce a new method, the use of Finsler metrics integrated in a Riemannian optimization scheme, that better adapts to dissimilar structures in the graph. We develop a tool to analyze the embeddings and infer structural properties of the data sets. For implementation, we choose Siegel spaces, a versatile family of symmetric spaces. Our approach outperforms competitive baselines for graph reconstruction tasks on various synthetic and real-world datasets. We further demonstrate its applicability on two downstream tasks, recommender systems and node classification.
A Fully Hyperbolic Neural Model for Hierarchical Multi-Class Classification
Oct 05, 2020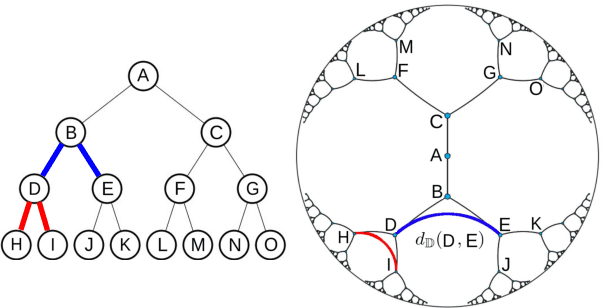

Label inventories for fine-grained entity typing have grown in size and complexity. Nonetheless, they exhibit a hierarchical structure. Hyperbolic spaces offer a mathematically appealing approach for learning hierarchical representations of symbolic data. However, it is not clear how to integrate hyperbolic components into downstream tasks. This is the first work that proposes a fully hyperbolic model for multi-class multi-label classification, which performs all operations in hyperbolic space. We evaluate the proposed model on two challenging datasets and compare to different baselines that operate under Euclidean assumptions. Our hyperbolic model infers the latent hierarchy from the class distribution, captures implicit hyponymic relations in the inventory, and shows performance on par with state-of-the-art methods on fine-grained classification with remarkable reduction of the parameter size. A thorough analysis sheds light on the impact of each component in the final prediction and showcases its ease of integration with Euclidean layers.
Adapting Deep Learning Methods for Mental Health Prediction on Social Media
Mar 17, 2020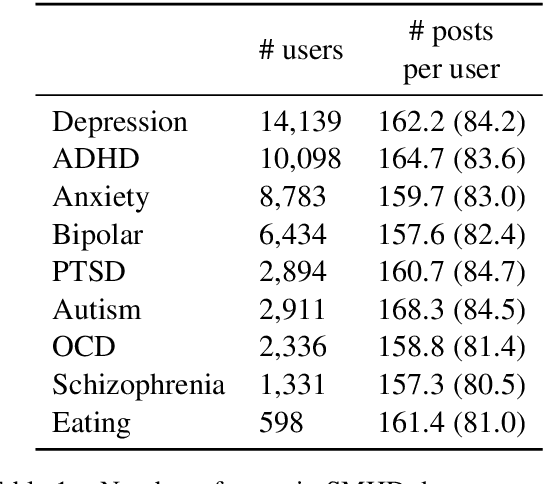
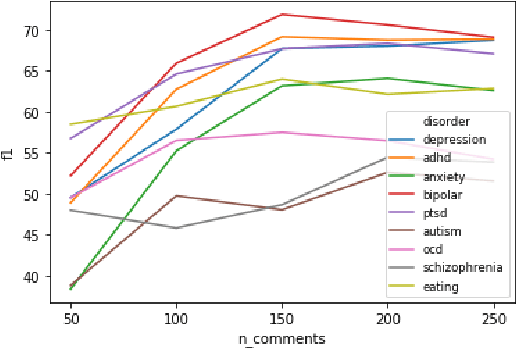


Mental health poses a significant challenge for an individual's well-being. Text analysis of rich resources, like social media, can contribute to deeper understanding of illnesses and provide means for their early detection. We tackle a challenge of detecting social media users' mental status through deep learning-based models, moving away from traditional approaches to the task. In a binary classification task on predicting if a user suffers from one of nine different disorders, a hierarchical attention network outperforms previously set benchmarks for four of the disorders. Furthermore, we explore the limitations of our model and analyze phrases relevant for classification by inspecting the model's word-level attention weights.
* W-NUT at EMNLP 2019
On the Importance of Subword Information for Morphological Tasks in Truly Low-Resource Languages
Sep 26, 2019
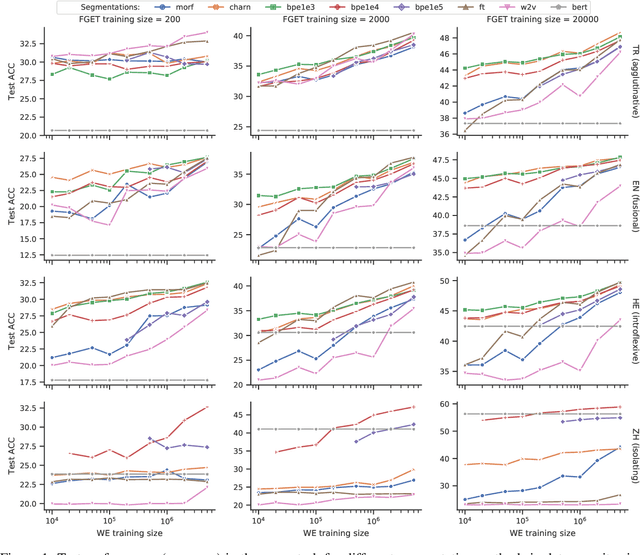
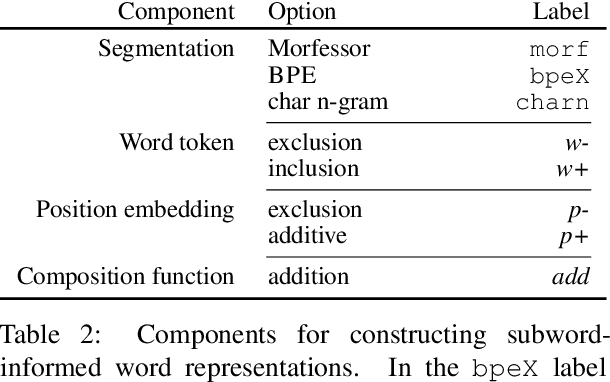
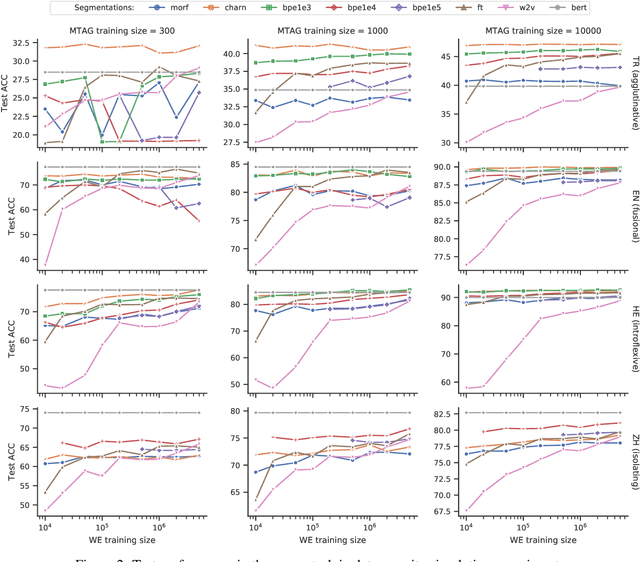
Recent work has validated the importance of subword information for word representation learning. Since subwords increase parameter sharing ability in neural models, their value should be even more pronounced in low-data regimes. In this work, we therefore provide a comprehensive analysis focused on the usefulness of subwords for word representation learning in truly low-resource scenarios and for three representative morphological tasks: fine-grained entity typing, morphological tagging, and named entity recognition. We conduct a systematic study that spans several dimensions of comparison: 1) type of data scarcity which can stem from the lack of task-specific training data, or even from the lack of unannotated data required to train word embeddings, or both; 2) language type by working with a sample of 16 typologically diverse languages including some truly low-resource ones (e.g. Rusyn, Buryat, and Zulu); 3) the choice of the subword-informed word representation method. Our main results show that subword-informed models are universally useful across all language types, with large gains over subword-agnostic embeddings. They also suggest that the effective use of subwords largely depends on the language (type) and the task at hand, as well as on the amount of available data for training the embeddings and task-based models, where having sufficient in-task data is a more critical requirement.
Using Automatically Extracted Minimum Spans to Disentangle Coreference Evaluation from Boundary Detection
Jun 16, 2019

The common practice in coreference resolution is to identify and evaluate the maximum span of mentions. The use of maximum spans tangles coreference evaluation with the challenges of mention boundary detection like prepositional phrase attachment. To address this problem, minimum spans are manually annotated in smaller corpora. However, this additional annotation is costly and therefore, this solution does not scale to large corpora. In this paper, we propose the MINA algorithm for automatically extracting minimum spans to benefit from minimum span evaluation in all corpora. We show that the extracted minimum spans by MINA are consistent with those that are manually annotated by experts. Our experiments show that using minimum spans is in particular important in cross-dataset coreference evaluation, in which detected mention boundaries are noisier due to domain shift. We will integrate MINA into https://github.com/ns-moosavi/coval for reporting standard coreference scores based on both maximum and automatically detected minimum spans.