 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanation of Reinforcement Learning Model in Dynamic Multi-Agent System
Aug 04, 2020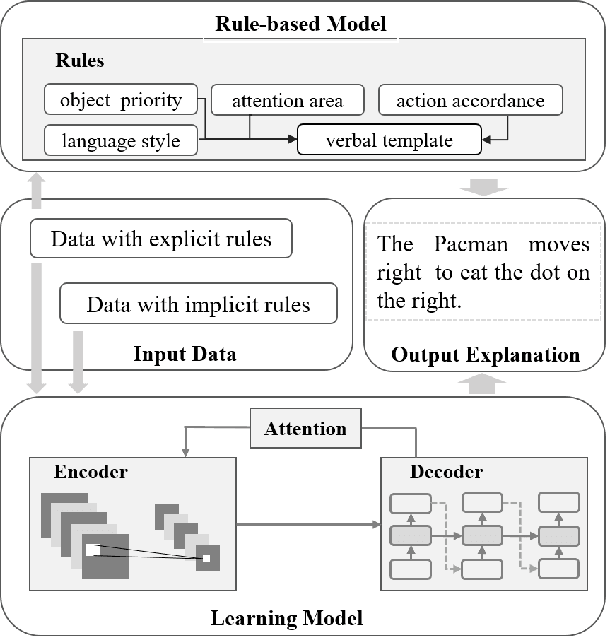

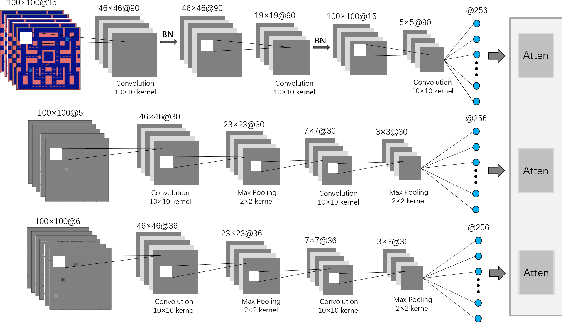
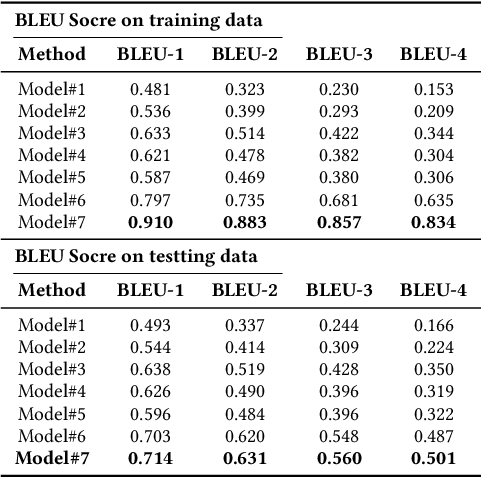
Recently, there has been increasing interest in transparency and interpretability in Deep Reinforcement Learning (DRL) systems. Verbal explanations, as the most natural way of communication in our daily life, deserve more attention, since they allow users to gain a better understanding of the system which ultimately could lead to a high level of trust and smooth collaboration. This paper reports a novel work in generating verbal explanations for DRL behaviors agent. A rule-based model is designed to construct explanations using a series of rules which are predefined with prior knowledge. A learning model is then proposed to expand the implicit logic of generating verbal explanation to general situations by employing rule-based explanations as training data. The learning model is shown to have better flexibility and generalizability than the static rule-based model. The performance of both models is evaluated quantitatively through objective metrics. The results show that verbal explanation generated by both models improve subjective satisfaction of users towards the interpretability of DRL systems. Additionally, seven variants of the learning model are designed to illustrate the contribution of input channels, attention mechanism, and proposed encoder in improving the quality of verbal explanation.
Transparency and Explanation in Deep Reinforcement Learning Neural Networks
Sep 17, 2018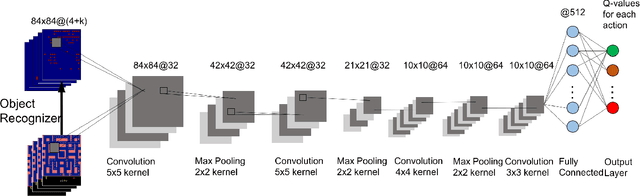


Autonomous AI systems will be entering human society in the near future to provide services and work alongside humans. For those systems to be accepted and trusted, the users should be able to understand the reasoning process of the system, i.e. the system should be transparent. System transparency enables humans to form coherent explanations of the system's decisions and actions. Transparency is important not only for user trust, but also for software debugging and certification. In recent years, Deep Neural Networks have made great advances in multiple application areas. However, deep neural networks are opaque. In this paper, we report on work in transparency in Deep Reinforcement Learning Networks (DRLN). Such networks have been extremely successful in accurately learning action control in image input domains, such as Atari games. In this paper, we propose a novel and general method that (a) incorporates explicit object recognition processing into deep reinforcement learning models, (b) forms the basis for the development of "object saliency maps", to provide visualization of internal states of DRLNs, thus enabling the formation of explanations and (c) can be incorporated in any existing deep reinforcement learning framework. We present computational results and human experiments to evaluate our approach.