 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning from Small Datasets
Nov 02, 2021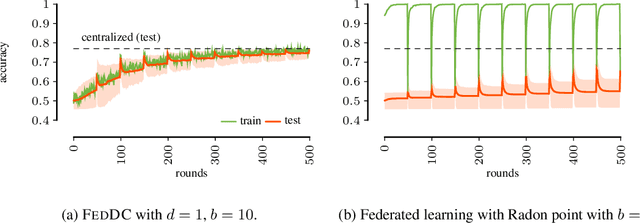

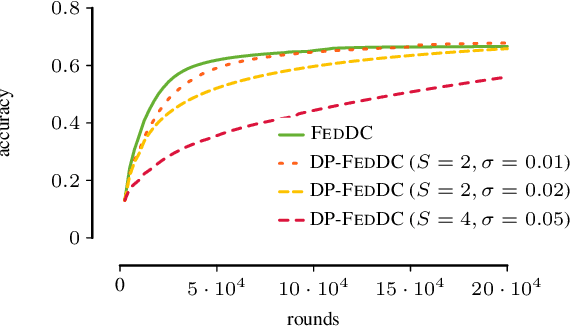

Federated learning allows multiple parties to collaboratively train a joint model without sharing local data. This enables applications of machine learning in settings of inherently distributed, undisclosable data such as in the medical domain. In practice, joint training is usually achieved by aggregating local models, for which local training objectives have to be in expectation similar to the joint (global) objective. Often, however, local datasets are so small that local objectives differ greatly from the global objective, resulting in federated learning to fail. We propose a novel approach that intertwines model aggregations with permutations of local models. The permutations expose each local model to a daisy chain of local datasets resulting in more efficient training in data-sparse domains. This enables training on extremely small local datasets, such as patient data across hospitals, while retaining the training efficiency and privacy benefits of federated learning.
TsmoBN: Interventional Generalization for Unseen Clients in Federated Learning
Oct 19, 2021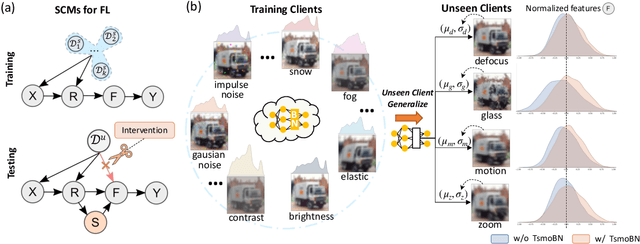
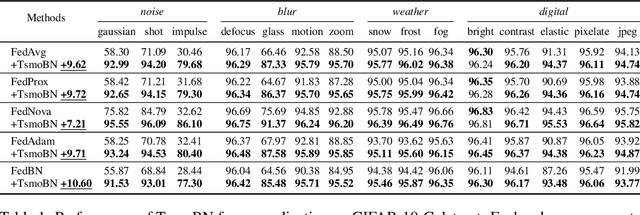
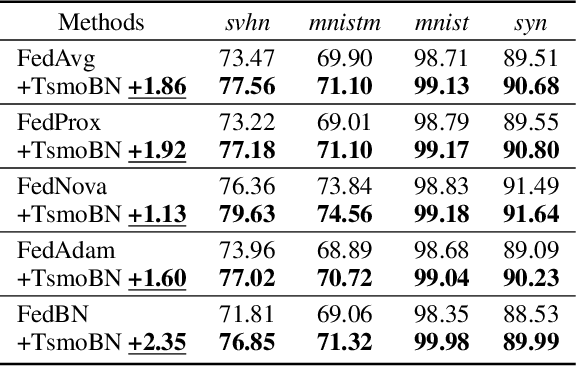
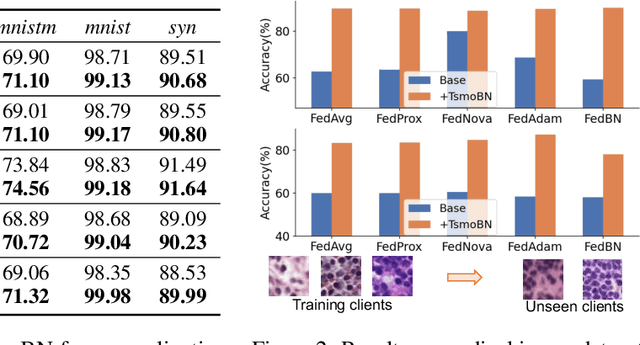
Generalizing federated learning (FL) models to unseen clients with non-iid data is a crucial topic, yet unsolved so far. In this work, we propose to tackle this problem from a novel causal perspective. Specifically, we form a training structural causal model (SCM) to explain the challenges of model generalization in a distributed learning paradigm. Based on this, we present a simple yet effective method using test-specific and momentum tracked batch normalization (TsmoBN) to generalize FL models to testing clients. We give a causal analysis by formulating another testing SCM and demonstrate that the key factor in TsmoBN is the test-specific statistics (i.e., mean and variance) of features. Such statistics can be seen as a surrogate variable for causal intervention. In addition, by considering generalization bounds in FL, we show that our TsmoBN method can reduce divergence between training and testing feature distributions, which achieves a lower generalization gap than standard model testing. Our extensive experimental evaluations demonstrate significant improvements for unseen client generalization on three datasets with various types of feature distributions and numbers of clients. It is worth noting that our proposed approach can be flexibly applied to different state-of-the-art federated learning algorithms and is orthogonal to existing domain generalization methods.
Novelty Detection in Sequential Data by Informed Clustering and Modeling
Mar 05, 2021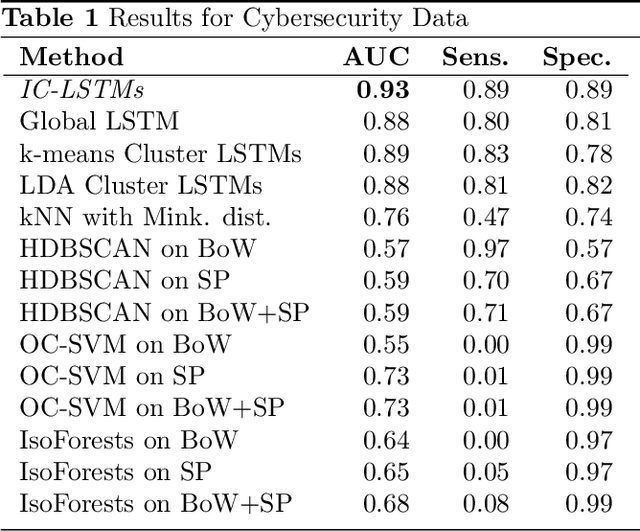
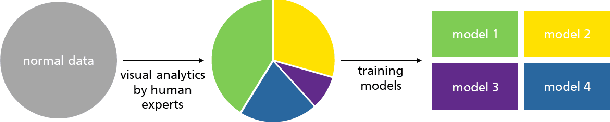
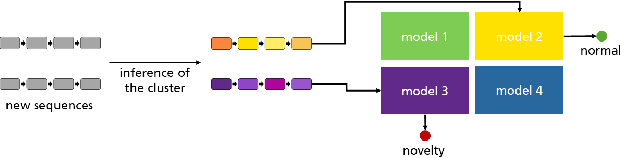
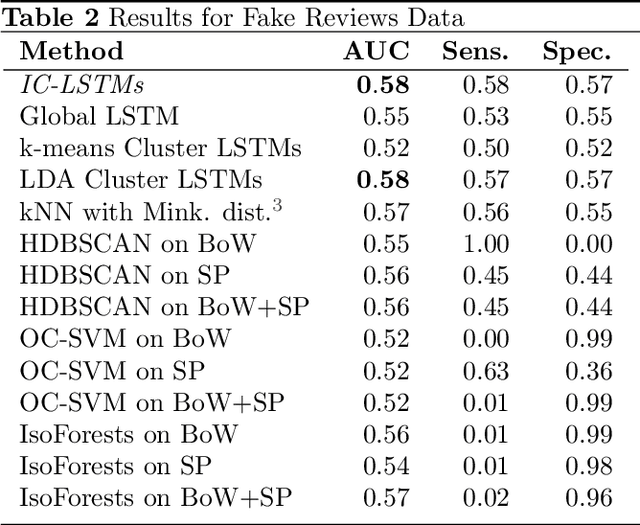
Novelty detection in discrete sequences is a challenging task, since deviations from the process generating the normal data are often small or intentionally hidden. Novelties can be detected by modeling normal sequences and measuring the deviations of a new sequence from the model predictions. However, in many applications data is generated by several distinct processes so that models trained on all the data tend to over-generalize and novelties remain undetected. We propose to approach this challenge through decomposition: by clustering the data we break down the problem, obtaining simpler modeling task in each cluster which can be modeled more accurately. However, this comes at a trade-off, since the amount of training data per cluster is reduced. This is a particular problem for discrete sequences where state-of-the-art models are data-hungry. The success of this approach thus depends on the quality of the clustering, i.e., whether the individual learning problems are sufficiently simpler than the joint problem. While clustering discrete sequences automatically is a challenging and domain-specific task, it is often easy for human domain experts, given the right tools. In this paper, we adapt a state-of-the-art visual analytics tool for discrete sequence clustering to obtain informed clusters from domain experts and use LSTMs to model each cluster individually. Our extensive empirical evaluation indicates that this informed clustering outperforms automatic ones and that our approach outperforms state-of-the-art novelty detection methods for discrete sequences in three real-world application scenarios. In particular, decomposition outperforms a global model despite less training data on each individual cluster.
FedBN: Federated Learning on Non-IID Features via Local Batch Normalization
Feb 15, 2021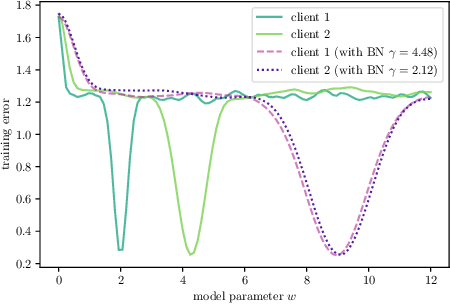
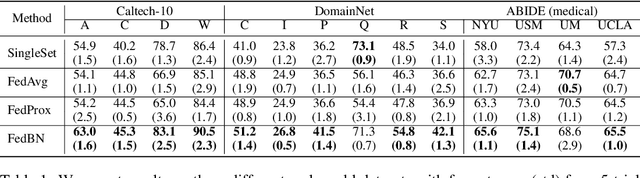
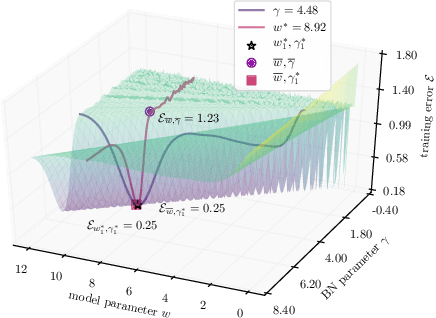

The emerging paradigm of federated learning (FL) strives to enable collaborative training of deep models on the network edge without centrally aggregating raw data and hence improving data privacy. In most cases, the assumption of independent and identically distributed samples across local clients does not hold for federated learning setups. Under this setting, neural network training performance may vary significantly according to the data distribution and even hurt training convergence. Most of the previous work has focused on a difference in the distribution of labels or client shifts. Unlike those settings, we address an important problem of FL, e.g., different scanners/sensors in medical imaging, different scenery distribution in autonomous driving (highway vs. city), where local clients store examples with different distributions compared to other clients, which we denote as feature shift non-iid. In this work, we propose an effective method that uses local batch normalization to alleviate the feature shift before averaging models. The resulting scheme, called FedBN, outperforms both classical FedAvg, as well as the state-of-the-art for non-iid data (FedProx) on our extensive experiments. These empirical results are supported by a convergence analysis that shows in a simplified setting that FedBN has a faster convergence rate than FedAvg. Code is available at https://github.com/med-air/FedBN.
Resource-Constrained On-Device Learning by Dynamic Averaging
Sep 25, 2020
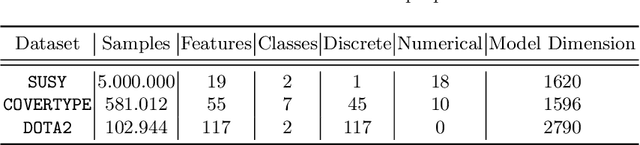
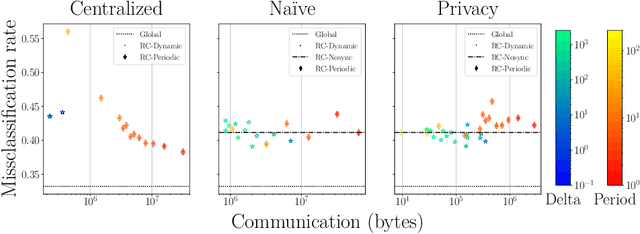
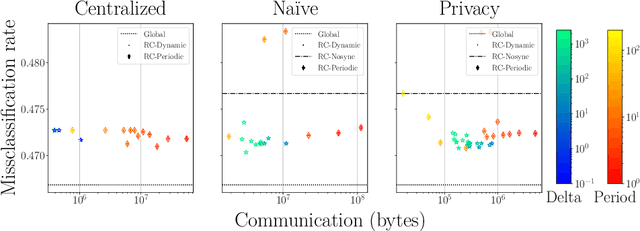
The communication between data-generating devices is partially responsible for a growing portion of the world's power consumption. Thus reducing communication is vital, both, from an economical and an ecological perspective. For machine learning, on-device learning avoids sending raw data, which can reduce communication substantially. Furthermore, not centralizing the data protects privacy-sensitive data. However, most learning algorithms require hardware with high computation power and thus high energy consumption. In contrast, ultra-low-power processors, like FPGAs or micro-controllers, allow for energy-efficient learning of local models. Combined with communication-efficient distributed learning strategies, this reduces the overall energy consumption and enables applications that were yet impossible due to limited energy on local devices. The major challenge is then, that the low-power processors typically only have integer processing capabilities. This paper investigates an approach to communication-efficient on-device learning of integer exponential families that can be executed on low-power processors, is privacy-preserving, and effectively minimizes communication. The empirical evaluation shows that the approach can reach a model quality comparable to a centrally learned regular model with an order of magnitude less communication. Comparing the overall energy consumption, this reduces the required energy for solving the machine learning task by a significant amount.
Feature-Robustness, Flatness and Generalization Error for Deep Neural Networks
Jan 07, 2020

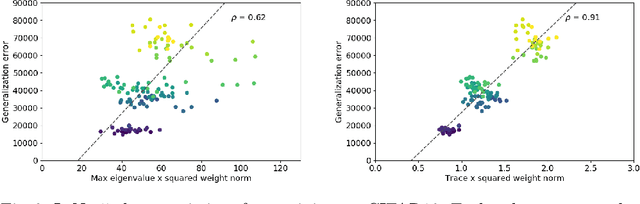
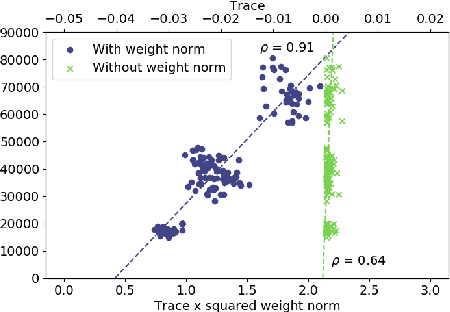
The performance of deep neural networks is often attributed to their automated, task-related feature construction. It remains an open question, though, why this leads to solutions with good generalization, even in cases where the number of parameters is larger than the number of samples. Back in the 90s, Hochreiter and Schmidhuber observed that flatness of the loss surface around a local minimum correlates with low generalization error. For several flatness measures, this correlation has been empirically validated. However, it has recently been shown that existing measures of flatness cannot theoretically be related to generalization: if a network uses ReLU activations, the network function can be reparameterized without changing its output in such a way that flatness is changed almost arbitrarily. This paper proposes a natural modification of existing flatness measures that results in invariance to reparameterization. The proposed measures imply a robustness of the network to changes in the input and the hidden layers. Connecting this feature robustness to generalization leads to a generalized definition of the representativeness of data. With this, the generalization error of a model trained on representative data can be bounded by its feature robustness which depends on our novel flatness measure.
A Reparameterization-Invariant Flatness Measure for Deep Neural Networks
Nov 29, 2019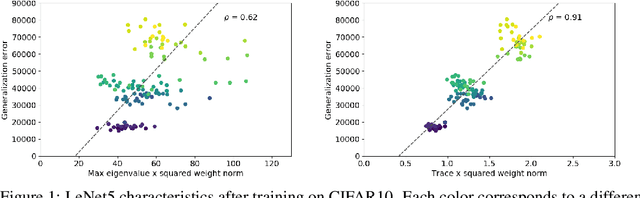

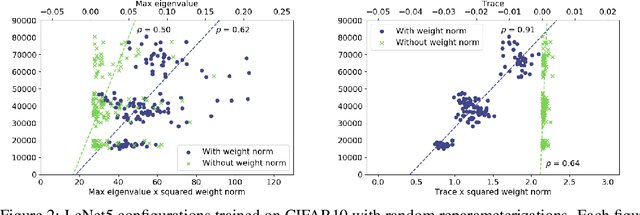
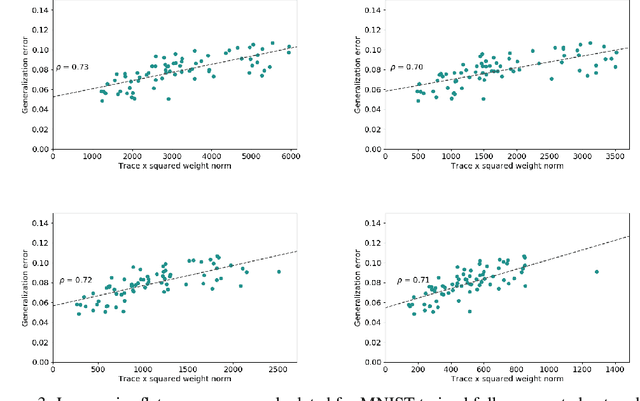
The performance of deep neural networks is often attributed to their automated, task-related feature construction. It remains an open question, though, why this leads to solutions with good generalization, even in cases where the number of parameters is larger than the number of samples. Back in the 90s, Hochreiter and Schmidhuber observed that flatness of the loss surface around a local minimum correlates with low generalization error. For several flatness measures, this correlation has been empirically validated. However, it has recently been shown that existing measures of flatness cannot theoretically be related to generalization due to a lack of invariance with respect to reparameterizations. We propose a natural modification of existing flatness measures that results in invariance to reparameterization.
Communication-Efficient Distributed Online Learning with Kernels
Nov 28, 2019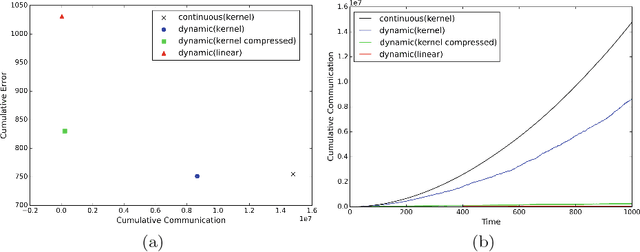
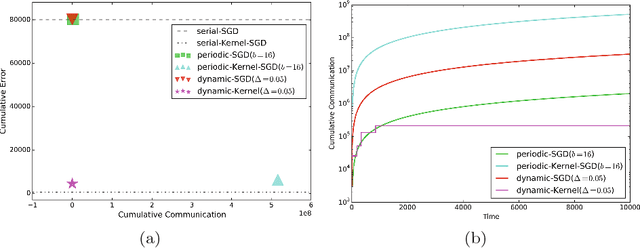
We propose an efficient distributed online learning protocol for low-latency real-time services. It extends a previously presented protocol to kernelized online learners that represent their models by a support vector expansion. While such learners often achieve higher predictive performance than their linear counterparts, communicating the support vector expansions becomes inefficient for large numbers of support vectors. The proposed extension allows for a larger class of online learning algorithms---including those alleviating the problem above through model compression. In addition, we characterize the quality of the proposed protocol by introducing a novel criterion that requires the communication to be bounded by the loss suffered.
Adaptive Communication Bounds for Distributed Online Learning
Nov 28, 2019We consider distributed online learning protocols that control the exchange of information between local learners in a round-based learning scenario. The learning performance of such a protocol is intuitively optimal if approximately the same loss is incurred as in a hypothetical serial setting. If a protocol accomplishes this, it is inherently impossible to achieve a strong communication bound at the same time. In the worst case, every input is essential for the learning performance, even for the serial setting, and thus needs to be exchanged between the local learners. However, it is reasonable to demand a bound that scales well with the hardness of the serialized prediction problem, as measured by the loss received by a serial online learning algorithm. We provide formal criteria based on this intuition and show that they hold for a simplified version of a previously published protocol.
Information-Theoretic Perspective of Federated Learning
Nov 15, 2019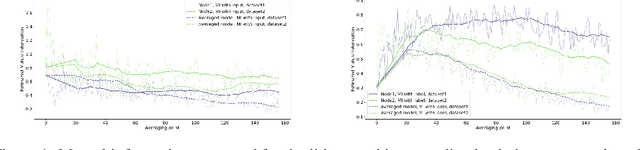
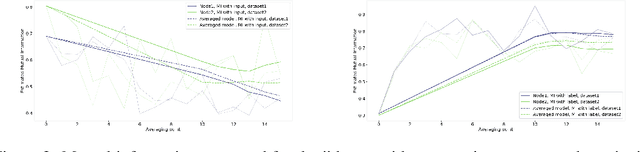
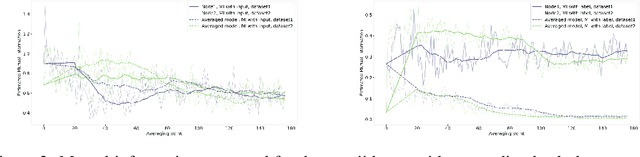
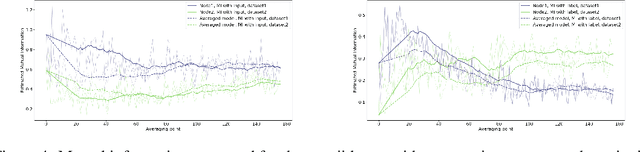
An approach to distributed machine learning is to train models on local datasets and aggregate these models into a single, stronger model. A popular instance of this form of parallelization is federated learning, where the nodes periodically send their local models to a coordinator that aggregates them and redistributes the aggregation back to continue training with it. The most frequently used form of aggregation is averaging the model parameters, e.g., the weights of a neural network. However, due to the non-convexity of the loss surface of neural networks, averaging can lead to detrimental effects and it remains an open question under which conditions averaging is beneficial. In this paper, we study this problem from the perspective of information theory: We measure the mutual information between representation and inputs as well as representation and labels in local models and compare it to the respective information contained in the representation of the averaged model. Our empirical results confirm previous observations about the practical usefulness of averaging for neural networks, even if local dataset distributions vary strongly. Furthermore, we obtain more insights about the impact of the aggregation frequency on the information flow and thus on the success of distributed learning. These insights will be helpful both in improving the current synchronization process and in further understanding the effects of model aggregation.