 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Acceleration of the Sinkhorn and Greenkhorn Algorithms for Optimal Transport
Jun 09, 2019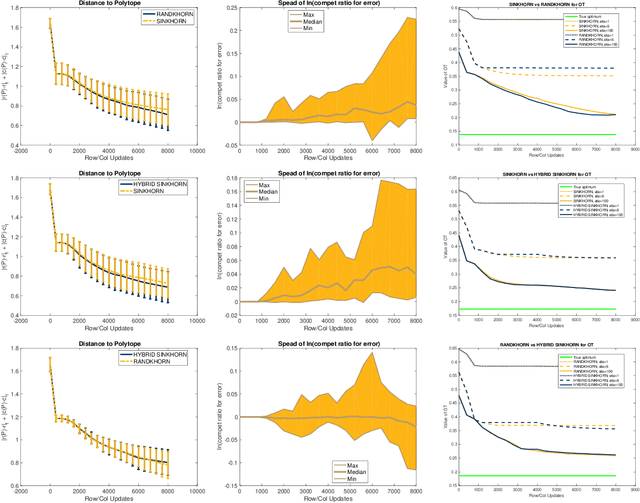
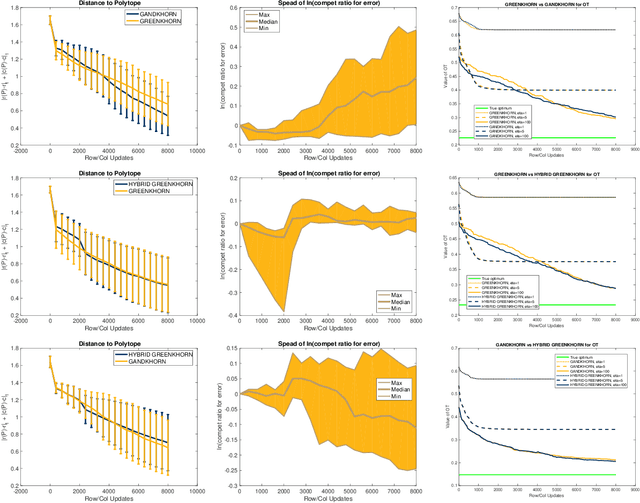
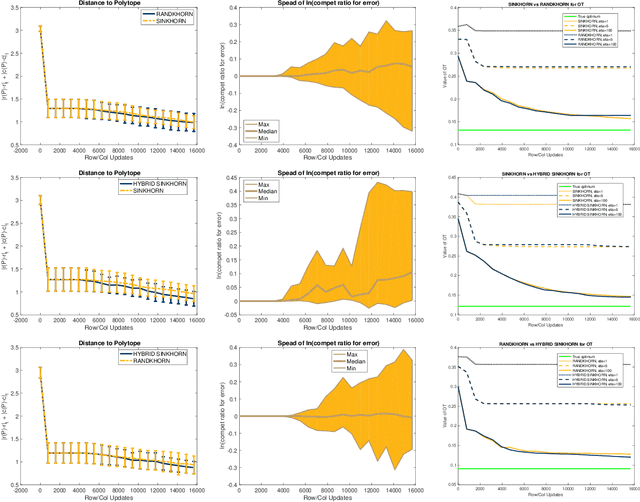
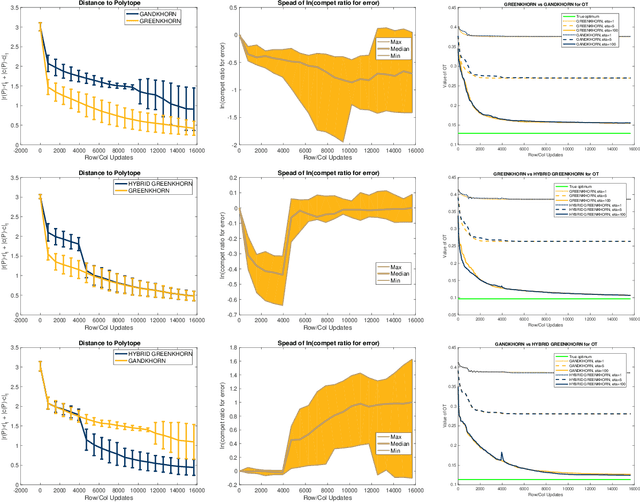
We propose and analyze a novel approach to accelerate the Sinkhorn and Greenkhorn algorithms for solving the entropic regularized optimal transport (OT) problems. Focusing on the discrete setting where the probability distributions have at most $n$ atoms, and letting $\varepsilon \in \left(0, 1\right)$ denote the tolerance, we introduce accelerated algorithms that have complexity bounds of $\widetilde{\mathcal{O}}\left(n^{5/2}/\varepsilon^{3/2}\right)$. This improves on the known complexity bound of $\widetilde{\mathcal{O}} \left(n^{2}/\varepsilon^2\right)$ for the Sinkhorn and Greenkhorn algorithms. We also present two hybrid algorithms that use the new accelerated algorithms to initialize the Sinkhorn and Greenkhorn algorithms, and we establish complexity bounds of $\widetilde{\mathcal{O}}\left(n^{7/3}/\varepsilon\right)$ for these hybrid algorithms. We provide an extensive experimental comparison on both synthetic and real datasets to explore the relative advantages of the new algorithms.
ML-LOO: Detecting Adversarial Examples with Feature Attribution
Jun 08, 2019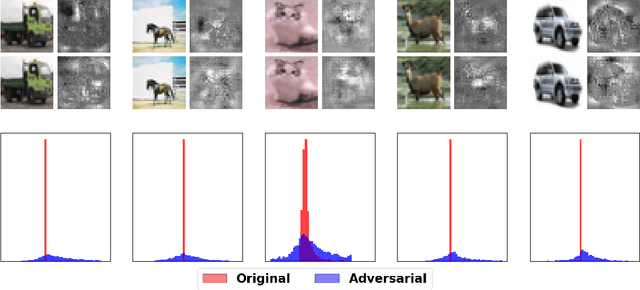
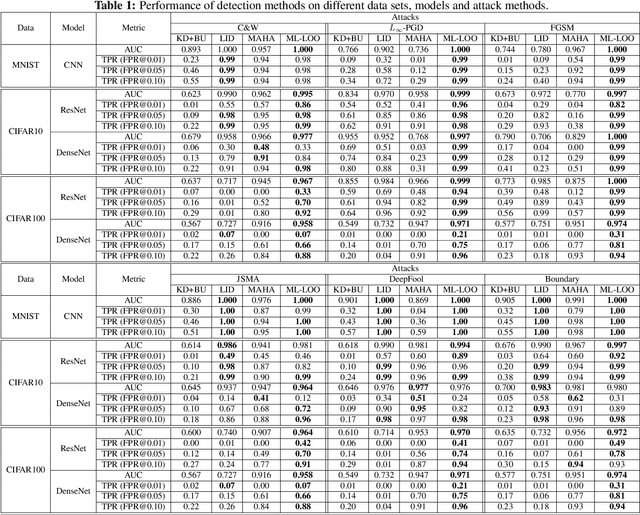
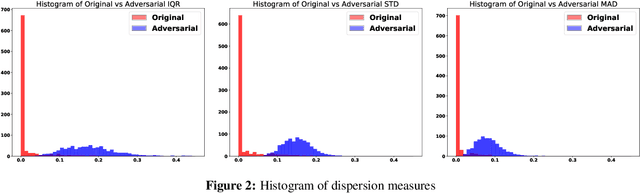
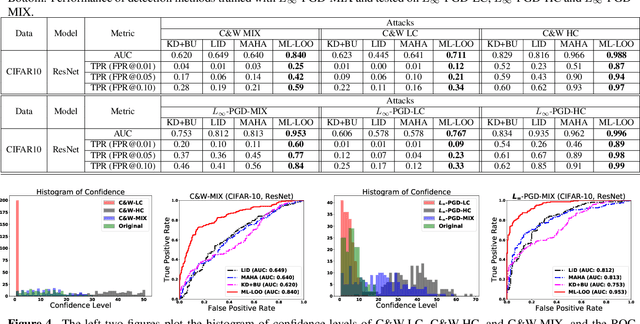
Deep neural networks obtain state-of-the-art performance on a series of tasks. However, they are easily fooled by adding a small adversarial perturbation to input. The perturbation is often human imperceptible on image data. We observe a significant difference in feature attributions of adversarially crafted examples from those of original ones. Based on this observation, we introduce a new framework to detect adversarial examples through thresholding a scale estimate of feature attribution scores. Furthermore, we extend our method to include multi-layer feature attributions in order to tackle the attacks with mixed confidence levels. Through vast experiments, our method achieves superior performances in distinguishing adversarial examples from popular attack methods on a variety of real data sets among state-of-the-art detection methods. In particular, our method is able to detect adversarial examples of mixed confidence levels, and transfer between different attacking methods.
Generalized Momentum-Based Methods: A Hamiltonian Perspective
Jun 02, 2019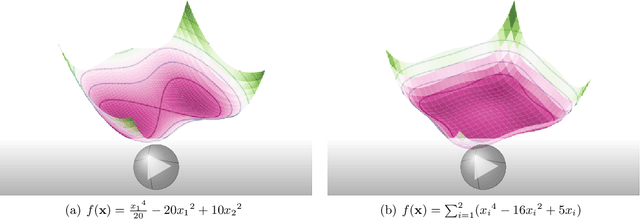
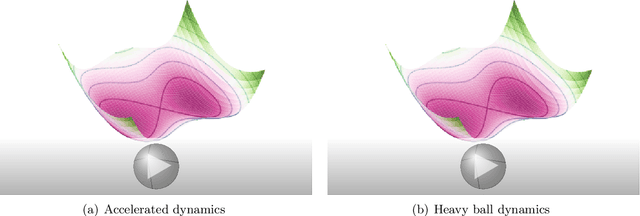
We take a Hamiltonian-based perspective to generalize Nesterov's accelerated gradient descent and Polyak's heavy ball method to a broad class of momentum methods in the setting of (possibly) constrained minimization in Banach spaces. Our perspective leads to a generic and unifying non-asymptotic analysis of convergence of these methods in both the function value (in the setting of convex optimization) and in the norm of the gradient (in the setting of unconstrained, possibly nonconvex, optimization). The convergence analysis is intuitive and based on the conserved quantities of the time-dependent Hamiltonian that we introduce and that produces generalized momentum methods as its equations of motion.
On Gradient Descent Ascent for Nonconvex-Concave Minimax Problems
Jun 02, 2019
We consider nonconvex-concave minimax problems, $\min_{x} \max_{y\in\mathcal{Y}} f(x, y)$, where $f$ is nonconvex in $x$ but concave in $y$. The standard algorithm for solving this problem is the celebrated gradient descent ascent (GDA) algorithm, which has been widely used in machine learning, control theory and economics. However, despite the solid theory for the convex-concave setting, GDA can converge to limit cycles or even diverge in a general setting. In this paper, we present a nonasymptotic analysis of GDA for solving nonconvex-concave minimax problems, showing that GDA can find a stationary point of the function $\Phi(\cdot) :=\max_{y\in\mathcal{Y} }f(\cdot, y)$ efficiently. To the best our knowledge, this is the first theoretical guarantee for GDA in this setting, shedding light on its practical performance in many real applications.
Langevin Monte Carlo without Smoothness
May 30, 2019Langevin Monte Carlo (LMC) is an iterative algorithm used to generate samples from a distribution that is known only up to a normalizing constant. The nonasymptotic dependence of its mixing time on the dimension and target accuracy is understood only in the setting of smooth (gradient-Lipschitz) log-densities, a serious limitation for applications in machine learning. In this paper, we remove this limitation, providing polynomial-time convergence guarantees for a variant of LMC in the setting of nonsmooth log-concave distributions. At a high level, our results follow by leveraging the implicit smoothing of the log-density that comes from a small Gaussian perturbation that we add to the iterates of the algorithm and controlling the bias and variance that are induced by this perturbation.
Posterior Distribution for the Number of Clusters in Dirichlet Process Mixture Models
May 23, 2019Dirichlet process mixture models (DPMM) play a central role in Bayesian nonparametrics, with applications throughout statistics and machine learning. DPMMs are generally used in clustering problems where the number of clusters is not known in advance, and the posterior distribution is treated as providing inference for this number. Recently, however, it has been shown that the DPMM is inconsistent in inferring the true number of components in certain cases. This is an asymptotic result, and it would be desirable to understand whether it holds with finite samples, and to more fully understand the full posterior. In this work, we provide a rigorous study for the posterior distribution of the number of clusters in DPMM under different prior distributions on the parameters and constraints on the distributions of the data. We provide novel lower bounds on the ratios of probabilities between $s+1$ clusters and $s$ clusters when the prior distributions on parameters are chosen to be Gaussian or uniform distributions.
Accelerated Primal-Dual Coordinate Descent for Computational Optimal Transport
May 23, 2019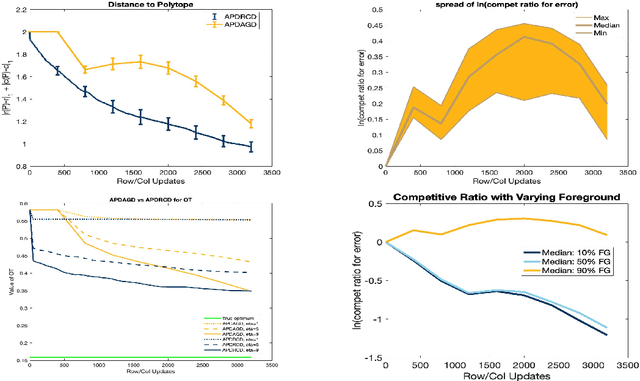
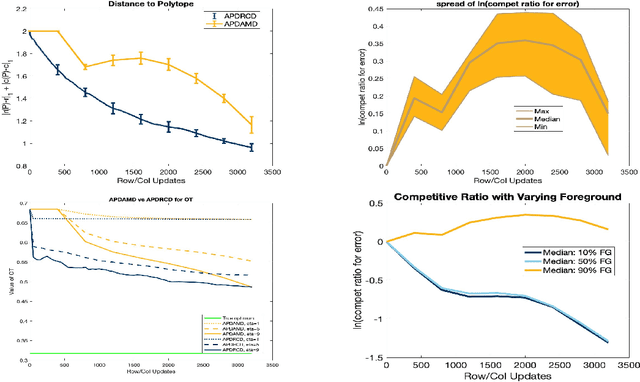
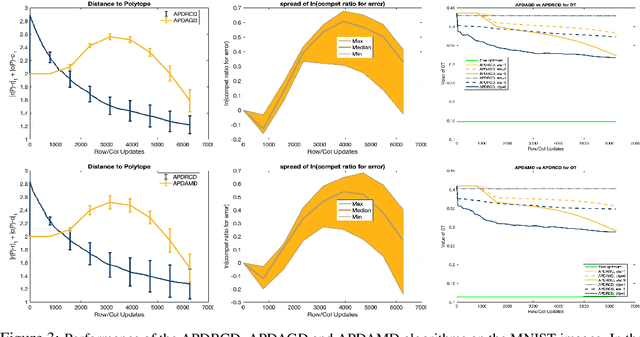
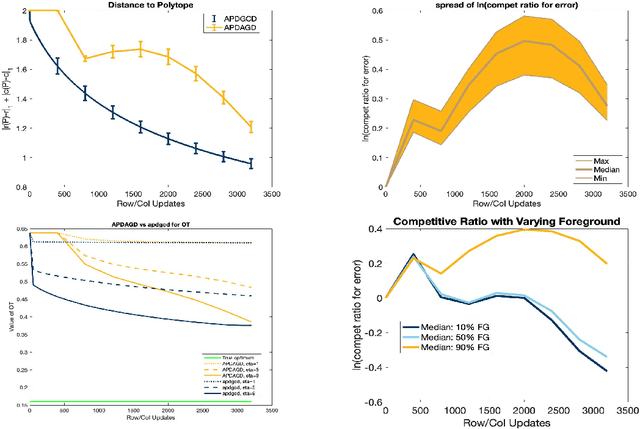
We propose and analyze a novel accelerated primal-dual coordinate descent framework for computing the optimal transport (OT) distance between two discrete probability distributions. First, we introduce the accelerated primal-dual randomized coordinate descent (APDRCD) algorithm for computing OT. Then we provide a complexity upper bound $\widetilde{\mathcal{O}}(\frac{n^{5/2}}{\varepsilon})$ for the APDRCD method for approximating OT distance, where $n$ stands for the number of atoms of these probability measures and $\varepsilon > 0$ is the desired accuracy. This upper bound matches the best known complexities of adaptive primal-dual accelerated gradient descent (APDAGD) and adaptive primal-dual accelerate mirror descent (APDAMD) algorithms while it is better than those of Sinkhorn and Greenkhorn algorithms, which are of the order $\widetilde{\mathcal{O}}(\frac{n^{2}}{\varepsilon^2})$, in terms of the desired accuracy $\varepsilon > 0$. Furthermore, we propose a greedy version of APDRCD algorithm that we refer to as the accelerated primal-dual greedy coordinate descent (APDGCD) algorithm and demonstrate that it has a better practical performance than the APDRCD algorithm. Extensive experimental studies demonstrate the favorable performance of the APDRCD and APDGCD algorithms over state-of-the-art primal-dual algorithms for OT in the literature.
A Dynamical Systems Perspective on Nesterov Acceleration
May 17, 2019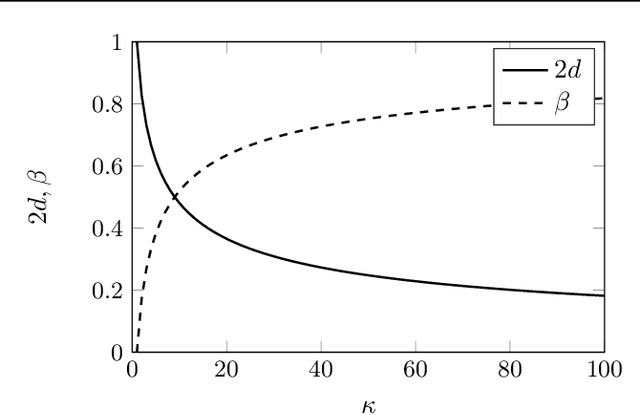
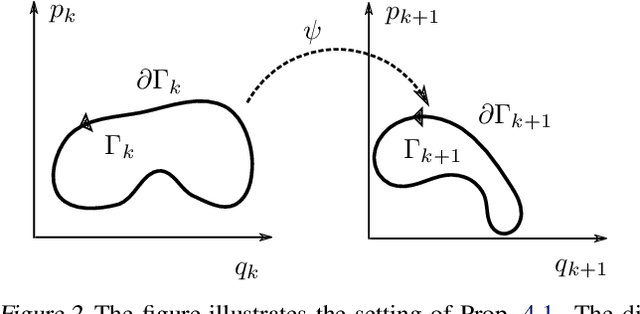
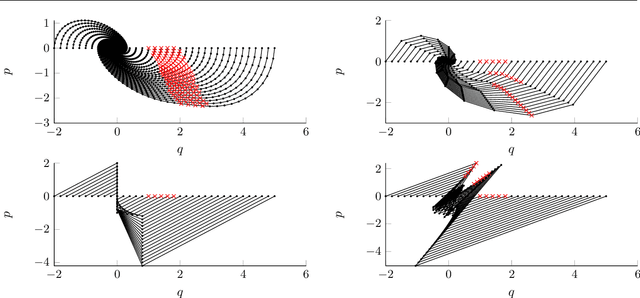
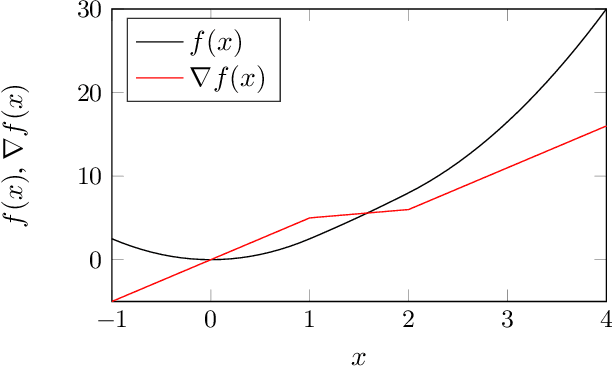
We present a dynamical system framework for understanding Nesterov's accelerated gradient method. In contrast to earlier work, our derivation does not rely on a vanishing step size argument. We show that Nesterov acceleration arises from discretizing an ordinary differential equation with a semi-implicit Euler integration scheme. We analyze both the underlying differential equation as well as the discretization to obtain insights into the phenomenon of acceleration. The analysis suggests that a curvature-dependent damping term lies at the heart of the phenomenon. We further establish connections between the discretized and the continuous-time dynamics.
On the Adaptivity of Stochastic Gradient-Based Optimization
May 16, 2019Stochastic-gradient-based optimization has been a core enabling methodology in applications to large-scale problems in machine learning and related areas. Despite the progress, the gap between theory and practice remains significant, with theoreticians pursuing mathematical optimality at a cost of obtaining specialized procedures in different regimes (e.g., modulus of strong convexity, magnitude of target accuracy, signal-to-noise ratio), and with practitioners not readily able to know which regime is appropriate to their problem, and seeking broadly applicable algorithms that are reasonably close to optimality. To bridge these perspectives it is necessary to study algorithms that are adaptive to different regimes. We present the stochastically controlled stochastic gradient (SCSG) method for composite convex finite-sum optimization problems and show that SCSG is adaptive to both strong convexity and target accuracy. The adaptivity is achieved by batch variance reduction with adaptive batch sizes and a novel technique, which we referred to as \emph{geometrization}, which sets the length of each epoch as a geometric random variable. The algorithm achieves strictly better theoretical complexity than other existing adaptive algorithms, while the tuning parameters of the algorithm only depend on the smoothness parameter of the objective.
A joint model of unpaired data from scRNA-seq and spatial transcriptomics for imputing missing gene expression measurements
May 06, 2019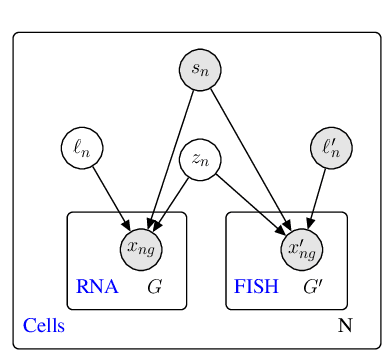
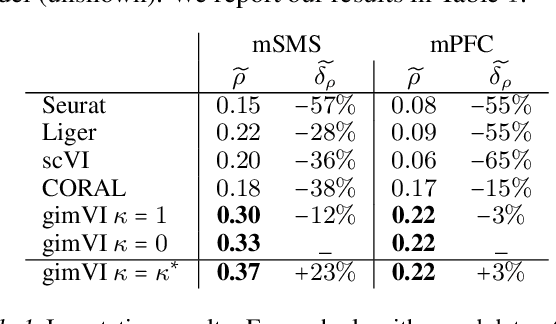
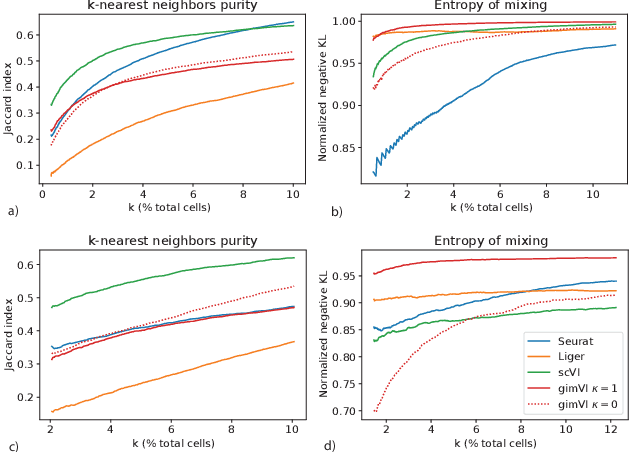
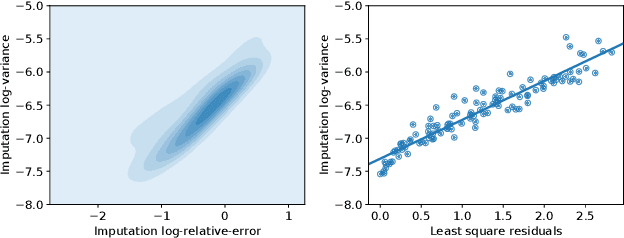
Spatial studies of transcriptome provide biologists with gene expression maps of heterogeneous and complex tissues. However, most experimental protocols for spatial transcriptomics suffer from the need to select beforehand a small fraction of genes to be quantified over the entire transcriptome. Standard single-cell RNA sequencing (scRNA-seq) is more prevalent, easier to implement and can in principle capture any gene but cannot recover the spatial location of the cells. In this manuscript, we focus on the problem of imputation of missing genes in spatial transcriptomic data based on (unpaired) standard scRNA-seq data from the same biological tissue. Building upon domain adaptation work, we propose gimVI, a deep generative model for the integration of spatial transcriptomic data and scRNA-seq data that can be used to impute missing genes. After describing our generative model and an inference procedure for it, we compare gimVI to alternative methods from computational biology or domain adaptation on real datasets and outperform Seurat Anchors, Liger and CORAL to impute held-out genes.