 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-based Adaptive Reconfiguration Over Lattices for Hallucination Reduction
May 26, 2026We introduce CAROL (Chain-based Adaptive Reconfiguration Over Lattices), a probabilistic framework for test-time hallucination reduction in large language models. Rather than relying on token-level uncertainty, CAROL defines a semantic uncertainty measure based on the consistency between generated responses and a trusted context, inducing a string-submodular objective over a lattice of textual sequences. This formulation enables hallucination mitigation to be cast as a Markov chain accept-reject process with provable convergence and near-optimality guarantees, allowing the model to iteratively refine outputs toward semantic consistency. By operating at the level of meaning, CAROL unifies hallucination detection and mitigation within a single framework. Empirical results on question answering and multi-agent reasoning benchmarks show that CAROL significantly reduces hallucinations and improves reliability and interpretability compared to likelihood-based and retrieval-augmented baselines, while maintaining competitive computational efficiency.
Hierarchical Prompt-Domain Control and Learning for Resource-Constrained Agentic Language Models
May 26, 2026Large Language Models are increasingly deployed inside agentic systems, where they must follow structured protocols, adapt to evolving states, and operate under memory, latency, and cost constraints. In such regimes, prompt extension is unreliable: growing contexts can push compact models outside their effective prompt domain, while deployment-time fine-tuning remains limited by scarce data and compute. We propose a hierarchical control-and-learning framework in which a compact model is first distilled to learn the required output schema, then supervised online by an oracle-controller loop. The controller monitors protocol validity and semantic performance, projects accumulated histories into a feasible prompt domain, and triggers lightweight oracle-supervised fine-tuning under drift. This separates schema learning for communication compatibility from semantic adaptation for task-level correction. We formalize prompt-domain feasibility and attention-induced saturation, motivating control of the effective prompt state rather than reliance on nominal context length. Using Multi-Fidelity Bayesian Optimization as a controlled sequential testbed, we characterize a core deployment failure mode and show improved reliability and cost-efficiency over non-hierarchical, distillation-only, and non-distilled baselines.
A Partitioned Sparse Variational Gaussian Process for Fast, Distributed Spatial Modeling
Jul 22, 2025The next generation of Department of Energy supercomputers will be capable of exascale computation. For these machines, far more computation will be possible than that which can be saved to disk. As a result, users will be unable to rely on post-hoc access to data for uncertainty quantification and other statistical analyses and there will be an urgent need for sophisticated machine learning algorithms which can be trained in situ. Algorithms deployed in this setting must be highly scalable, memory efficient and capable of handling data which is distributed across nodes as spatially contiguous partitions. One suitable approach involves fitting a sparse variational Gaussian process (SVGP) model independently and in parallel to each spatial partition. The resulting model is scalable, efficient and generally accurate, but produces the undesirable effect of constructing discontinuous response surfaces due to the disagreement between neighboring models at their shared boundary. In this paper, we extend this idea by allowing for a small amount of communication between neighboring spatial partitions which encourages better alignment of the local models, leading to smoother spatial predictions and a better fit in general. Due to our decentralized communication scheme, the proposed extension remains highly scalable and adds very little overhead in terms of computation (and none, in terms of memory). We demonstrate this Partitioned SVGP (PSVGP) approach for the Energy Exascale Earth System Model (E3SM) and compare the results to the independent SVGP case.
Fast emulation of density functional theory simulations using approximate Gaussian processes
Aug 24, 2022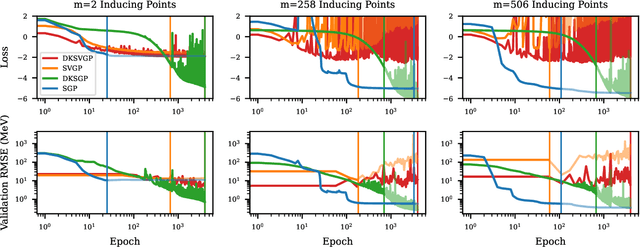
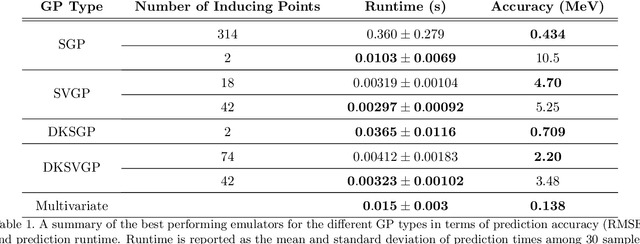
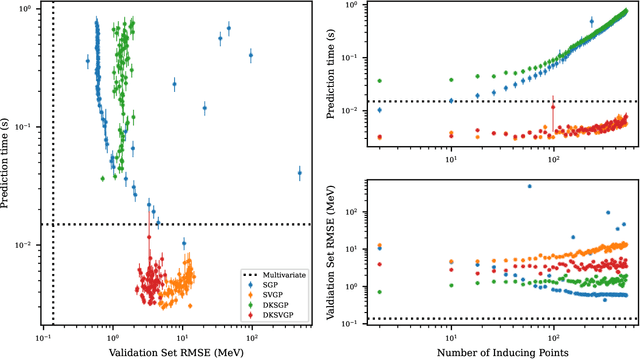
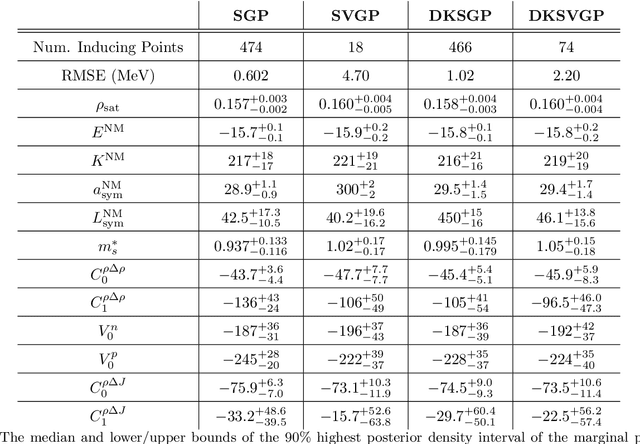
Fitting a theoretical model to experimental data in a Bayesian manner using Markov chain Monte Carlo typically requires one to evaluate the model thousands (or millions) of times. When the model is a slow-to-compute physics simulation, Bayesian model fitting becomes infeasible. To remedy this, a second statistical model that predicts the simulation output -- an "emulator" -- can be used in lieu of the full simulation during model fitting. A typical emulator of choice is the Gaussian process (GP), a flexible, non-linear model that provides both a predictive mean and variance at each input point. Gaussian process regression works well for small amounts of training data ($n < 10^3$), but becomes slow to train and use for prediction when the data set size becomes large. Various methods can be used to speed up the Gaussian process in the medium-to-large data set regime ($n > 10^5$), trading away predictive accuracy for drastically reduced runtime. This work examines the accuracy-runtime trade-off of several approximate Gaussian process models -- the sparse variational GP, stochastic variational GP, and deep kernel learned GP -- when emulating the predictions of density functional theory (DFT) models. Additionally, we use the emulators to calibrate, in a Bayesian manner, the DFT model parameters using observed data, resolving the computational barrier imposed by the data set size, and compare calibration results to previous work. The utility of these calibrated DFT models is to make predictions, based on observed data, about the properties of experimentally unobserved nuclides of interest e.g. super-heavy nuclei.