 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Generation of Inference Making Questions for Reading Comprehension Assessments
Jun 09, 2025Inference making is an essential but complex skill in reading comprehension (RC). Some inferences require resolving references across sentences, and some rely on using prior knowledge to fill in the detail that is not explicitly written in the text. Diagnostic RC questions can help educators provide more effective and targeted reading instruction and interventions for school-age students. We introduce a taxonomy of inference types for RC and use it to analyze the distribution of items within a diagnostic RC item bank. Next, we present experiments using GPT-4o to generate bridging-inference RC items for given reading passages via few-shot prompting, comparing conditions with and without chain-of-thought prompts. Generated items were evaluated on three aspects: overall item quality, appropriate inference type, and LLM reasoning, achieving high inter-rater agreements above 0.90. Our results show that GPT-4o produced 93.8% good-quality questions suitable for operational use in grade 3-12 contexts; however, only 42.6% of the generated questions accurately matched the targeted inference type. We conclude that combining automatic item generation with human judgment offers a promising path toward scalable, high-quality diagnostic RC assessments.
Towards an automatic method for generating topical vocabulary test forms for specific reading passages
May 24, 2025Background knowledge is typically needed for successful comprehension of topical and domain specific reading passages, such as in the STEM domain. However, there are few automated measures of student knowledge that can be readily deployed and scored in time to make predictions on whether a given student will likely be able to understand a specific content area text. In this paper, we present our effort in developing K-tool, an automated system for generating topical vocabulary tests that measure students' background knowledge related to a specific text. The system automatically detects the topic of a given text and produces topical vocabulary items based on their relationship with the topic. This information is used to automatically generate background knowledge forms that contain words that are highly related to the topic and words that share similar features but do not share high associations to the topic. Prior research indicates that performance on such tasks can help determine whether a student is likely to understand a particular text based on their knowledge state. The described system is intended for use with middle and high school student population of native speakers of English. It is designed to handle single reading passages and is not dependent on any corpus or text collection. In this paper, we describe the system architecture and present an initial evaluation of the system outputs.
Scaling up the Evaluation of Collaborative Problem Solving: Promises and Challenges of Coding Chat Data with ChatGPT
Nov 15, 2024



Collaborative problem solving (CPS) is widely recognized as a critical 21st century skill. Efficiently coding communication data is a big challenge in scaling up research on assessing CPS. This paper reports the findings on using ChatGPT to directly code CPS chat data by benchmarking performance across multiple datasets and coding frameworks. We found that ChatGPT-based coding outperformed human coding in tasks where the discussions were characterized by colloquial languages but fell short in tasks where the discussions dealt with specialized scientific terminology and contexts. The findings offer practical guidelines for researchers to develop strategies for efficient and scalable analysis of communication data from CPS tasks.
Is getting the right answer just about choosing the right words? The role of syntactically-informed features in short answer scoring
Mar 05, 2014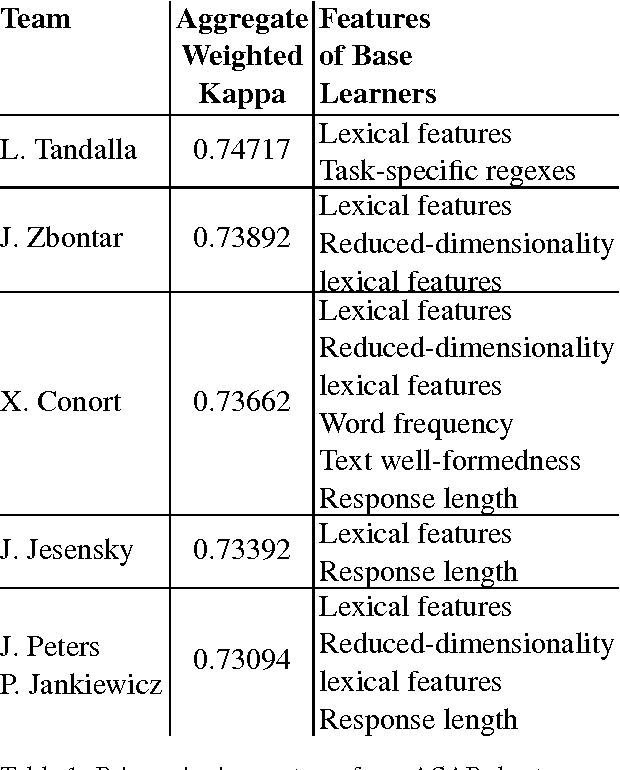

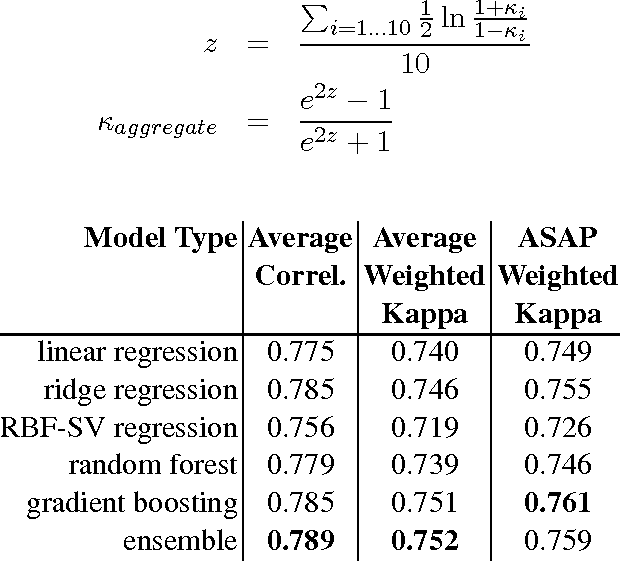
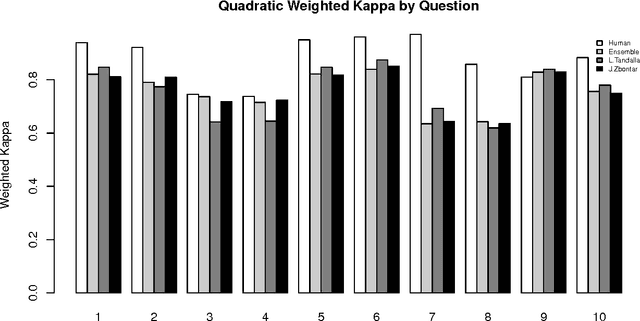
Developments in the educational landscape have spurred greater interest in the problem of automatically scoring short answer questions. A recent shared task on this topic revealed a fundamental divide in the modeling approaches that have been applied to this problem, with the best-performing systems split between those that employ a knowledge engineering approach and those that almost solely leverage lexical information (as opposed to higher-level syntactic information) in assigning a score to a given response. This paper aims to introduce the NLP community to the largest corpus currently available for short-answer scoring, provide an overview of methods used in the shared task using this data, and explore the extent to which more syntactically-informed features can contribute to the short answer scoring task in a way that avoids the question-specific manual effort of the knowledge engineering approach.