 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDPR Auto-Formalization with AI Agents and Human Verification
Apr 16, 2026We study the overall process of automatic formalization of GDPR provisions using large language models, within a human-in-the-loop verification framework. Rather than aiming for full autonomy, we adopt a role-specialized workflow in which LLM-based AI components, operating in a multi-agent setting with iterative feedback, generate legal scenarios, formal rules, and atomic facts. This is coupled with independent verification modules which include human reviewers' assessment of representational, logical, and legal correctness. Using this approach, we construct a high-quality dataset to be used for GDPR auto-formalization, and analyze both successful and problematic cases. Our results show that structured verification and targeted human oversight are essential for reliable legal formalization, especially in the presence of legal nuance and context-sensitive reasoning.
Can Legislation Be Made Machine-Readable in PROLEG?
Jan 04, 2026The anticipated positive social impact of regulatory processes requires both the accuracy and efficiency of their application. Modern artificial intelligence technologies, including natural language processing and machine-assisted reasoning, hold great promise for addressing this challenge. We present a framework to address the challenge of tools for regulatory application, based on current state-of-the-art (SOTA) methods for natural language processing (large language models or LLMs) and formalization of legal reasoning (the legal representation system PROLEG). As an example, we focus on Article 6 of the European General Data Protection Regulation (GDPR). In our framework, a single LLM prompt simultaneously transforms legal text into if-then rules and a corresponding PROLEG encoding, which are then validated and refined by legal domain experts. The final output is an executable PROLEG program that can produce human-readable explanations for instances of GDPR decisions. We describe processes to support the end-to-end transformation of a segment of a regulatory document (Article 6 from GDPR), including the prompting frame to guide an LLM to "compile" natural language text to if-then rules, then to further "compile" the vetted if-then rules to PROLEG. Finally, we produce an instance that shows the PROLEG execution. We conclude by summarizing the value of this approach and note observed limitations with suggestions to further develop such technologies for capturing and deploying regulatory frameworks.
Lex Rosetta: Transfer of Predictive Models Across Languages, Jurisdictions, and Legal Domains
Dec 15, 2021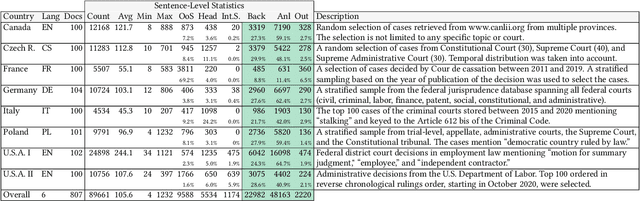
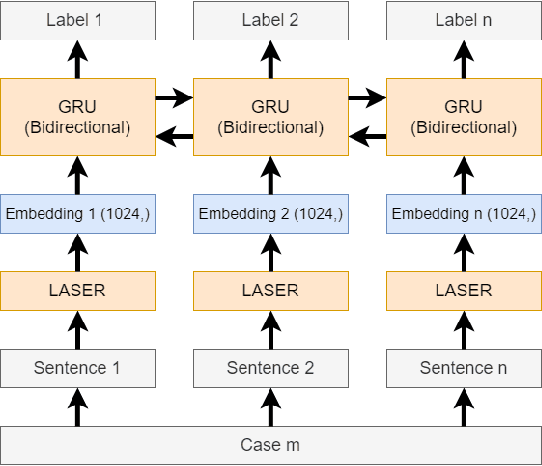
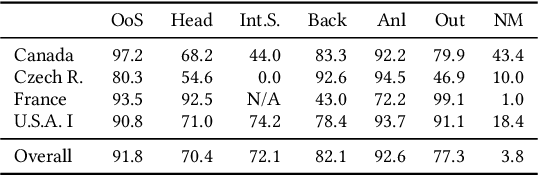
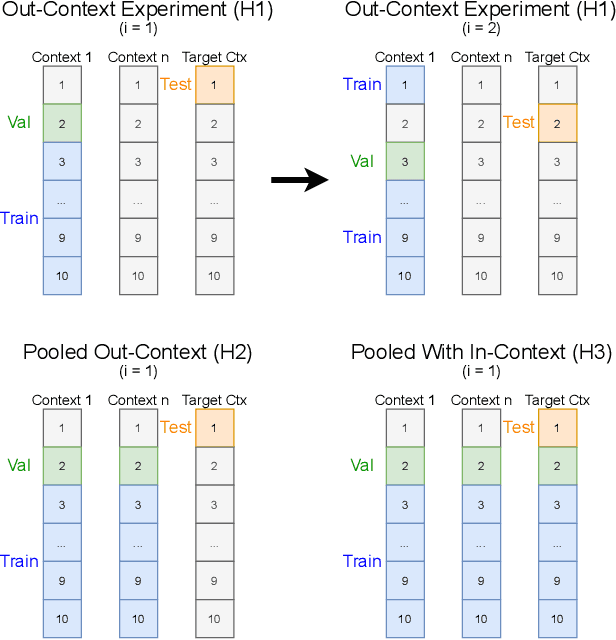
In this paper, we examine the use of multi-lingual sentence embeddings to transfer predictive models for functional segmentation of adjudicatory decisions across jurisdictions, legal systems (common and civil law), languages, and domains (i.e. contexts). Mechanisms for utilizing linguistic resources outside of their original context have significant potential benefits in AI & Law because differences between legal systems, languages, or traditions often block wider adoption of research outcomes. We analyze the use of Language-Agnostic Sentence Representations in sequence labeling models using Gated Recurrent Units (GRUs) that are transferable across languages. To investigate transfer between different contexts we developed an annotation scheme for functional segmentation of adjudicatory decisions. We found that models generalize beyond the contexts on which they were trained (e.g., a model trained on administrative decisions from the US can be applied to criminal law decisions from Italy). Further, we found that training the models on multiple contexts increases robustness and improves overall performance when evaluating on previously unseen contexts. Finally, we found that pooling the training data from all the contexts enhances the models' in-context performance.
* 10 pages