 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFishing for User Data in Large-Batch Federated Learning via Gradient Magnification
Feb 01, 2022

Federated learning (FL) has rapidly risen in popularity due to its promise of privacy and efficiency. Previous works have exposed privacy vulnerabilities in the FL pipeline by recovering user data from gradient updates. However, existing attacks fail to address realistic settings because they either 1) require a `toy' settings with very small batch sizes, or 2) require unrealistic and conspicuous architecture modifications. We introduce a new strategy that dramatically elevates existing attacks to operate on batches of arbitrarily large size, and without architectural modifications. Our model-agnostic strategy only requires modifications to the model parameters sent to the user, which is a realistic threat model in many scenarios. We demonstrate the strategy in challenging large-scale settings, obtaining high-fidelity data extraction in both cross-device and cross-silo federated learning.
Plug-In Inversion: Model-Agnostic Inversion for Vision with Data Augmentations
Jan 31, 2022



Existing techniques for model inversion typically rely on hard-to-tune regularizers, such as total variation or feature regularization, which must be individually calibrated for each network in order to produce adequate images. In this work, we introduce Plug-In Inversion, which relies on a simple set of augmentations and does not require excessive hyper-parameter tuning. Under our proposed augmentation-based scheme, the same set of augmentation hyper-parameters can be used for inverting a wide range of image classification models, regardless of input dimensions or the architecture. We illustrate the practicality of our approach by inverting Vision Transformers (ViTs) and Multi-Layer Perceptrons (MLPs) trained on the ImageNet dataset, tasks which to the best of our knowledge have not been successfully accomplished by any previous works.
Decepticons: Corrupted Transformers Breach Privacy in Federated Learning for Language Models
Jan 29, 2022



A central tenet of Federated learning (FL), which trains models without centralizing user data, is privacy. However, previous work has shown that the gradient updates used in FL can leak user information. While the most industrial uses of FL are for text applications (e.g. keystroke prediction), nearly all attacks on FL privacy have focused on simple image classifiers. We propose a novel attack that reveals private user text by deploying malicious parameter vectors, and which succeeds even with mini-batches, multiple users, and long sequences. Unlike previous attacks on FL, the attack exploits characteristics of both the Transformer architecture and the token embedding, separately extracting tokens and positional embeddings to retrieve high-fidelity text. This work suggests that FL on text, which has historically been resistant to privacy attacks, is far more vulnerable than previously thought.
Active Learning at the ImageNet Scale
Nov 25, 2021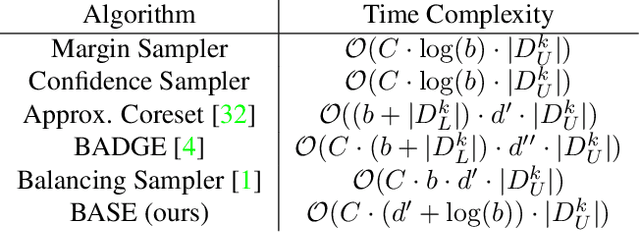
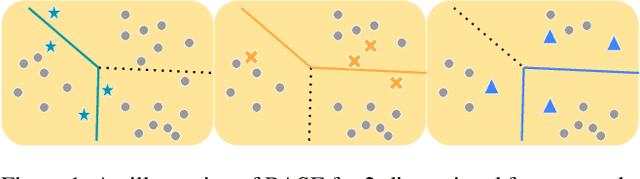

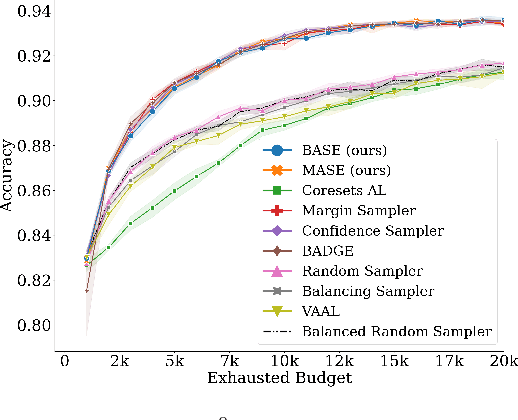
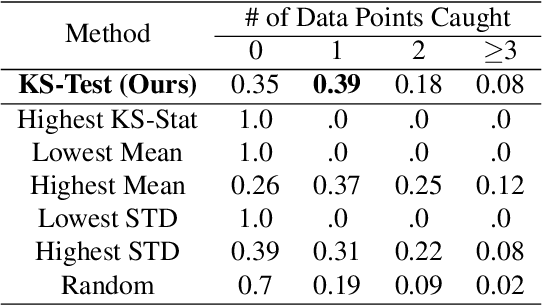
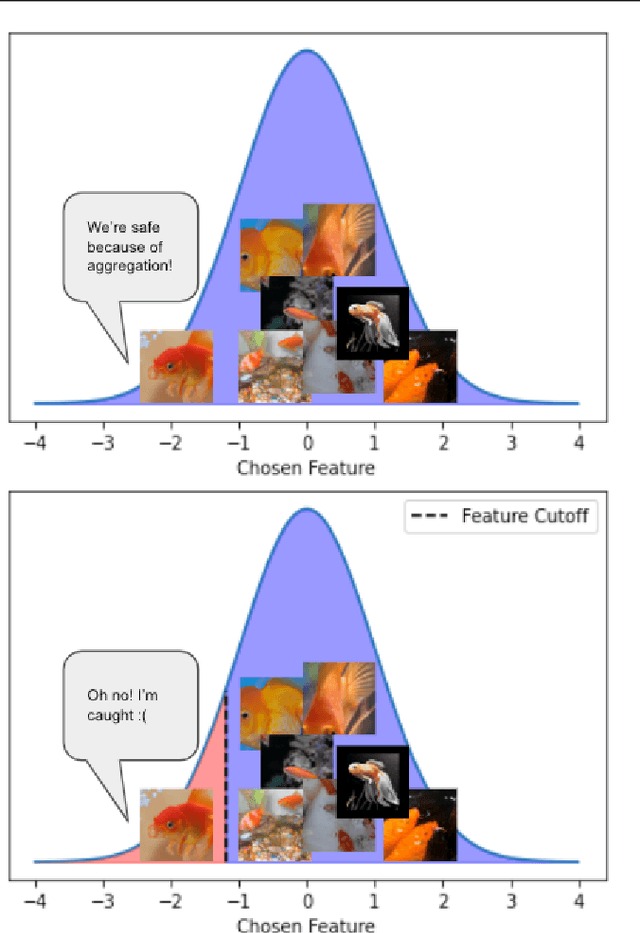
Active learning (AL) algorithms aim to identify an optimal subset of data for annotation, such that deep neural networks (DNN) can achieve better performance when trained on this labeled subset. AL is especially impactful in industrial scale settings where data labeling costs are high and practitioners use every tool at their disposal to improve model performance. The recent success of self-supervised pretraining (SSP) highlights the importance of harnessing abundant unlabeled data to boost model performance. By combining AL with SSP, we can make use of unlabeled data while simultaneously labeling and training on particularly informative samples. In this work, we study a combination of AL and SSP on ImageNet. We find that performance on small toy datasets -- the typical benchmark setting in the literature -- is not representative of performance on ImageNet due to the class imbalanced samples selected by an active learner. Among the existing baselines we test, popular AL algorithms across a variety of small and large scale settings fail to outperform random sampling. To remedy the class-imbalance problem, we propose Balanced Selection (BASE), a simple, scalable AL algorithm that outperforms random sampling consistently by selecting more balanced samples for annotation than existing methods. Our code is available at: https://github.com/zeyademam/active_learning .
Robbing the Fed: Directly Obtaining Private Data in Federated Learning with Modified Models
Oct 25, 2021


Federated learning has quickly gained popularity with its promises of increased user privacy and efficiency. Previous works have shown that federated gradient updates contain information that can be used to approximately recover user data in some situations. These previous attacks on user privacy have been limited in scope and do not scale to gradient updates aggregated over even a handful of data points, leaving some to conclude that data privacy is still intact for realistic training regimes. In this work, we introduce a new threat model based on minimal but malicious modifications of the shared model architecture which enable the server to directly obtain a verbatim copy of user data from gradient updates without solving difficult inverse problems. Even user data aggregated over large batches -- where previous methods fail to extract meaningful content -- can be reconstructed by these minimally modified models.
Comparing Human and Machine Bias in Face Recognition
Oct 25, 2021

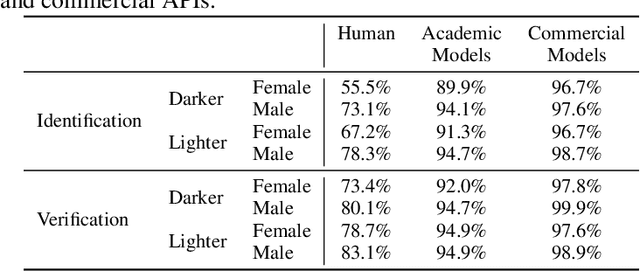
Much recent research has uncovered and discussed serious concerns of bias in facial analysis technologies, finding performance disparities between groups of people based on perceived gender, skin type, lighting condition, etc. These audits are immensely important and successful at measuring algorithmic bias but have two major challenges: the audits (1) use facial recognition datasets which lack quality metadata, like LFW and CelebA, and (2) do not compare their observed algorithmic bias to the biases of their human alternatives. In this paper, we release improvements to the LFW and CelebA datasets which will enable future researchers to obtain measurements of algorithmic bias that are not tainted by major flaws in the dataset (e.g. identical images appearing in both the gallery and test set). We also use these new data to develop a series of challenging facial identification and verification questions that we administered to various algorithms and a large, balanced sample of human reviewers. We find that both computer models and human survey participants perform significantly better at the verification task, generally obtain lower accuracy rates on dark-skinned or female subjects for both tasks, and obtain higher accuracy rates when their demographics match that of the question. Computer models are observed to achieve a higher level of accuracy than the survey participants on both tasks and exhibit bias to similar degrees as the human survey participants.
Identification of Attack-Specific Signatures in Adversarial Examples
Oct 13, 2021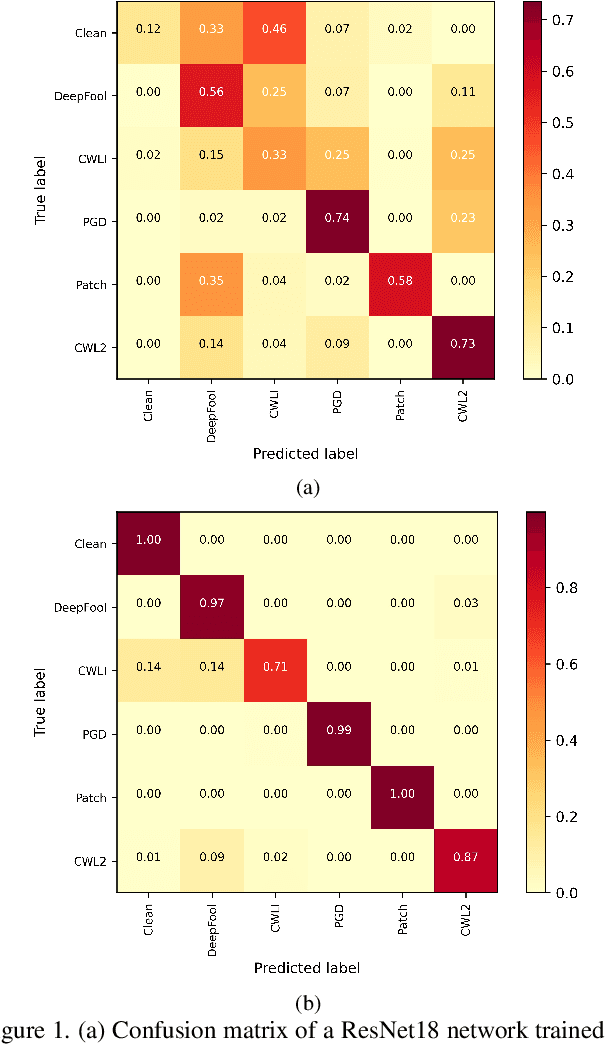

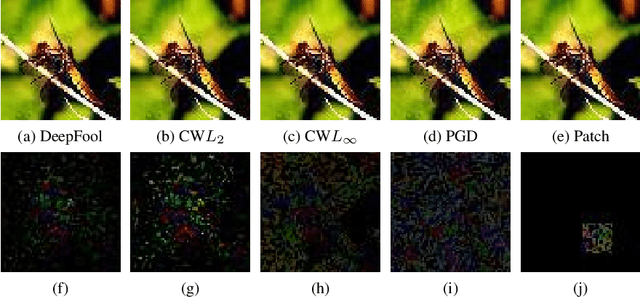
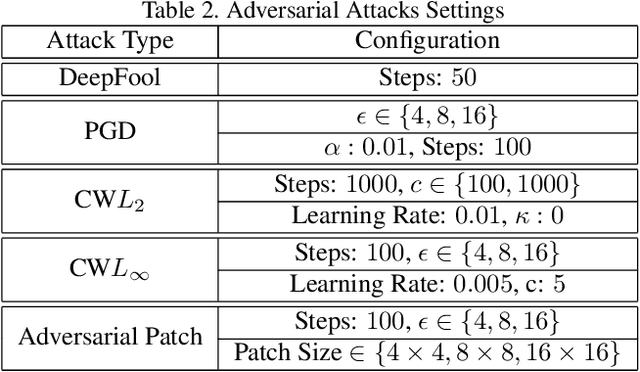
The adversarial attack literature contains a myriad of algorithms for crafting perturbations which yield pathological behavior in neural networks. In many cases, multiple algorithms target the same tasks and even enforce the same constraints. In this work, we show that different attack algorithms produce adversarial examples which are distinct not only in their effectiveness but also in how they qualitatively affect their victims. We begin by demonstrating that one can determine the attack algorithm that crafted an adversarial example. Then, we leverage recent advances in parameter-space saliency maps to show, both visually and quantitatively, that adversarial attack algorithms differ in which parts of the network and image they target. Our findings suggest that prospective adversarial attacks should be compared not only via their success rates at fooling models but also via deeper downstream effects they have on victims.
Stochastic Training is Not Necessary for Generalization
Sep 29, 2021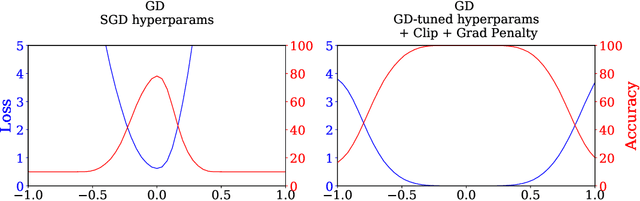

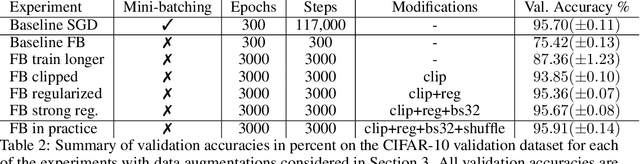
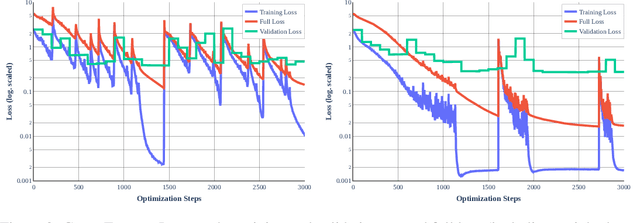
It is widely believed that the implicit regularization of stochastic gradient descent (SGD) is fundamental to the impressive generalization behavior we observe in neural networks. In this work, we demonstrate that non-stochastic full-batch training can achieve strong performance on CIFAR-10 that is on-par with SGD, using modern architectures in settings with and without data augmentation. To this end, we utilize modified hyperparameters and show that the implicit regularization of SGD can be completely replaced with explicit regularization. This strongly suggests that theories that rely heavily on properties of stochastic sampling to explain generalization are incomplete, as strong generalization behavior is still observed in the absence of stochastic sampling. Fundamentally, deep learning can succeed without stochasticity. Our observations further indicate that the perceived difficulty of full-batch training is largely the result of its optimization properties and the disproportionate time and effort spent by the ML community tuning optimizers and hyperparameters for small-batch training.
Towards Transferable Adversarial Attacks on Vision Transformers
Sep 18, 2021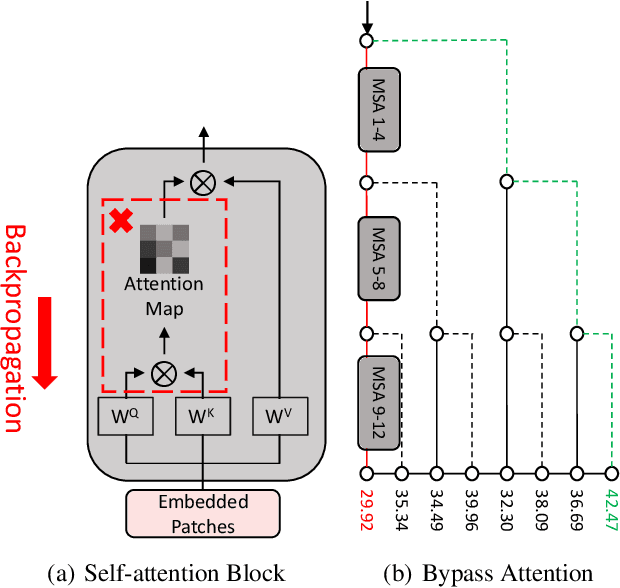
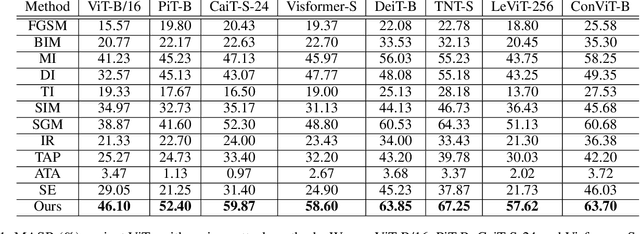
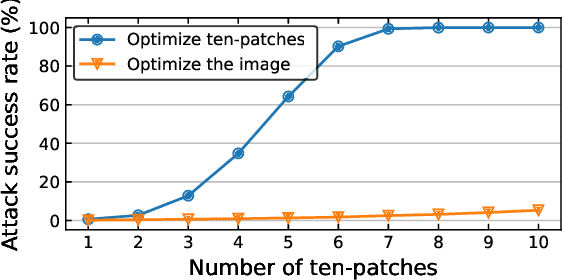
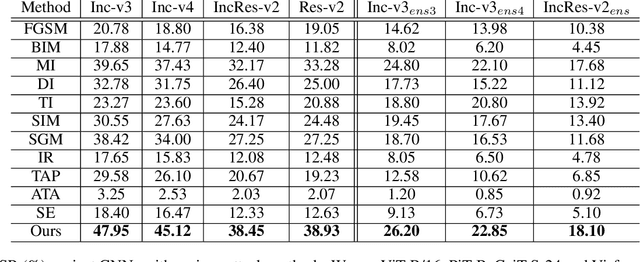
Vision transformers (ViTs) have demonstrated impressive performance on a series of computer vision tasks, yet they still suffer from adversarial examples. In this paper, we posit that adversarial attacks on transformers should be specially tailored for their architecture, jointly considering both patches and self-attention, in order to achieve high transferability. More specifically, we introduce a dual attack framework, which contains a Pay No Attention (PNA) attack and a PatchOut attack, to improve the transferability of adversarial samples across different ViTs. We show that skipping the gradients of attention during backpropagation can generate adversarial examples with high transferability. In addition, adversarial perturbations generated by optimizing randomly sampled subsets of patches at each iteration achieve higher attack success rates than attacks using all patches. We evaluate the transferability of attacks on state-of-the-art ViTs, CNNs and robustly trained CNNs. The results of these experiments demonstrate that the proposed dual attack can greatly boost transferability between ViTs and from ViTs to CNNs. In addition, the proposed method can easily be combined with existing transfer methods to boost performance.
Datasets for Studying Generalization from Easy to Hard Examples
Aug 13, 2021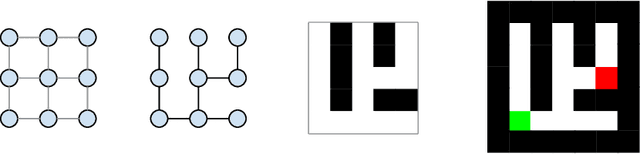
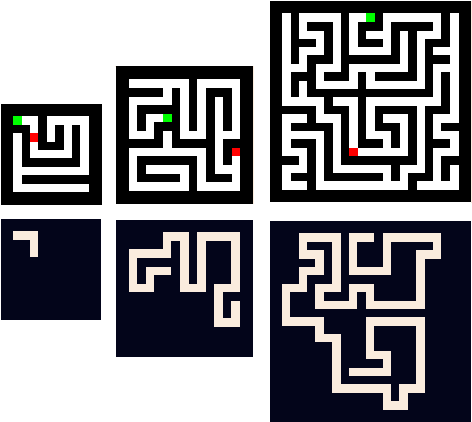
We describe new datasets for studying generalization from easy to hard examples.