 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLDP: Language-driven Dual-Pixel Image Defocus Deblurring Network
Jul 21, 2023



Recovering sharp images from dual-pixel (DP) pairs with disparity-dependent blur is a challenging task.~Existing blur map-based deblurring methods have demonstrated promising results. In this paper, we propose, to the best of our knowledge, the first framework to introduce the contrastive language-image pre-training framework (CLIP) to achieve accurate blur map estimation from DP pairs unsupervisedly. To this end, we first carefully design text prompts to enable CLIP to understand blur-related geometric prior knowledge from the DP pair. Then, we propose a format to input stereo DP pair to the CLIP without any fine-tuning, where the CLIP is pre-trained on monocular images. Given the estimated blur map, we introduce a blur-prior attention block, a blur-weighting loss and a blur-aware loss to recover the all-in-focus image. Our method achieves state-of-the-art performance in extensive experiments.
Parametric Depth Based Feature Representation Learning for Object Detection and Segmentation in Bird's Eye View
Jul 11, 2023



Recent vision-only perception models for autonomous driving achieved promising results by encoding multi-view image features into Bird's-Eye-View (BEV) space. A critical step and the main bottleneck of these methods is transforming image features into the BEV coordinate frame. This paper focuses on leveraging geometry information, such as depth, to model such feature transformation. Existing works rely on non-parametric depth distribution modeling leading to significant memory consumption, or ignore the geometry information to address this problem. In contrast, we propose to use parametric depth distribution modeling for feature transformation. We first lift the 2D image features to the 3D space defined for the ego vehicle via a predicted parametric depth distribution for each pixel in each view. Then, we aggregate the 3D feature volume based on the 3D space occupancy derived from depth to the BEV frame. Finally, we use the transformed features for downstream tasks such as object detection and semantic segmentation. Existing semantic segmentation methods do also suffer from an hallucination problem as they do not take visibility information into account. This hallucination can be particularly problematic for subsequent modules such as control and planning. To mitigate the issue, our method provides depth uncertainty and reliable visibility-aware estimations. We further leverage our parametric depth modeling to present a novel visibility-aware evaluation metric that, when taken into account, can mitigate the hallucination problem. Extensive experiments on object detection and semantic segmentation on the nuScenes datasets demonstrate that our method outperforms existing methods on both tasks.
VisFusion: Visibility-aware Online 3D Scene Reconstruction from Videos
Apr 21, 2023



We propose VisFusion, a visibility-aware online 3D scene reconstruction approach from posed monocular videos. In particular, we aim to reconstruct the scene from volumetric features. Unlike previous reconstruction methods which aggregate features for each voxel from input views without considering its visibility, we aim to improve the feature fusion by explicitly inferring its visibility from a similarity matrix, computed from its projected features in each image pair. Following previous works, our model is a coarse-to-fine pipeline including a volume sparsification process. Different from their works which sparsify voxels globally with a fixed occupancy threshold, we perform the sparsification on a local feature volume along each visual ray to preserve at least one voxel per ray for more fine details. The sparse local volume is then fused with a global one for online reconstruction. We further propose to predict TSDF in a coarse-to-fine manner by learning its residuals across scales leading to better TSDF predictions. Experimental results on benchmarks show that our method can achieve superior performance with more scene details. Code is available at: https://github.com/huiyu-gao/VisFusion
Sampled Transformer for Point Sets
Feb 28, 2023The sparse transformer can reduce the computational complexity of the self-attention layers to $O(n)$, whilst still being a universal approximator of continuous sequence-to-sequence functions. However, this permutation variant operation is not appropriate for direct application to sets. In this paper, we proposed an $O(n)$ complexity sampled transformer that can process point set elements directly without any additional inductive bias. Our sampled transformer introduces random element sampling, which randomly splits point sets into subsets, followed by applying a shared Hamiltonian self-attention mechanism to each subset. The overall attention mechanism can be viewed as a Hamiltonian cycle in the complete attention graph, and the permutation of point set elements is equivalent to randomly sampling Hamiltonian cycles. This mechanism implements a Monte Carlo simulation of the $O(n^2)$ dense attention connections. We show that it is a universal approximator for continuous set-to-set functions. Experimental results on point-clouds show comparable or better accuracy with significantly reduced computational complexity compared to the dense transformer or alternative sparse attention schemes.
Contact-aware Human Motion Forecasting
Oct 08, 2022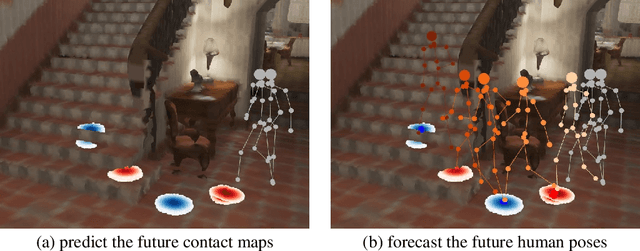
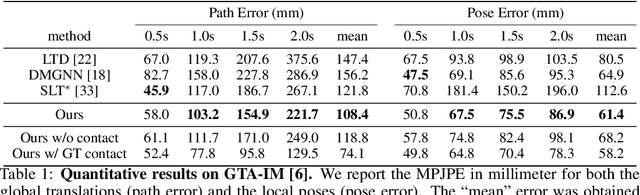
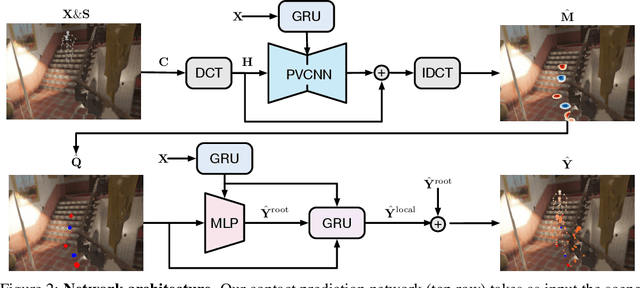
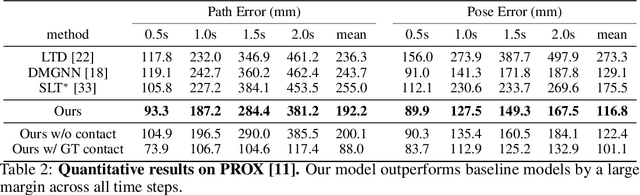
In this paper, we tackle the task of scene-aware 3D human motion forecasting, which consists of predicting future human poses given a 3D scene and a past human motion. A key challenge of this task is to ensure consistency between the human and the scene, accounting for human-scene interactions. Previous attempts to do so model such interactions only implicitly, and thus tend to produce artifacts such as "ghost motion" because of the lack of explicit constraints between the local poses and the global motion. Here, by contrast, we propose to explicitly model the human-scene contacts. To this end, we introduce distance-based contact maps that capture the contact relationships between every joint and every 3D scene point at each time instant. We then develop a two-stage pipeline that first predicts the future contact maps from the past ones and the scene point cloud, and then forecasts the future human poses by conditioning them on the predicted contact maps. During training, we explicitly encourage consistency between the global motion and the local poses via a prior defined using the contact maps and future poses. Our approach outperforms the state-of-the-art human motion forecasting and human synthesis methods on both synthetic and real datasets. Our code is available at https://github.com/wei-mao-2019/ContAwareMotionPred.
WiCV 2022: The Tenth Women In Computer Vision Workshop
Aug 24, 2022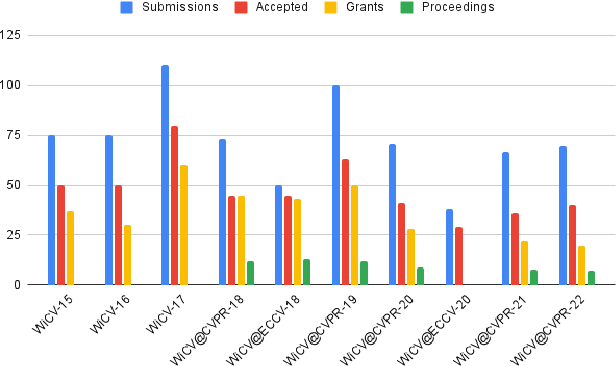
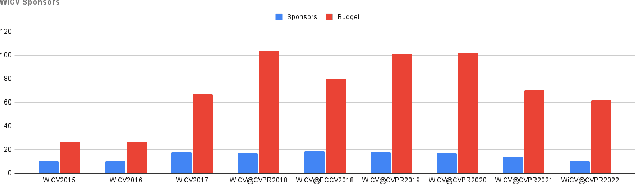
In this paper, we present the details of Women in Computer Vision Workshop - WiCV 2022, organized alongside the hybrid CVPR 2022 in New Orleans, Louisiana. It provides a voice to a minority (female) group in the computer vision community and focuses on increasing the visibility of these researchers, both in academia and industry. WiCV believes that such an event can play an important role in lowering the gender imbalance in the field of computer vision. WiCV is organized each year where it provides a) opportunity for collaboration between researchers from minority groups, b) mentorship to female junior researchers, c) financial support to presenters to overcome monetary burden and d) large and diverse choice of role models, who can serve as examples to younger researchers at the beginning of their careers. In this paper, we present a report on the workshop program, trends over the past years, a summary of statistics regarding presenters, attendees, and sponsorship for the WiCV 2022 workshop.
Weakly-supervised Action Transition Learning for Stochastic Human Motion Prediction
May 31, 2022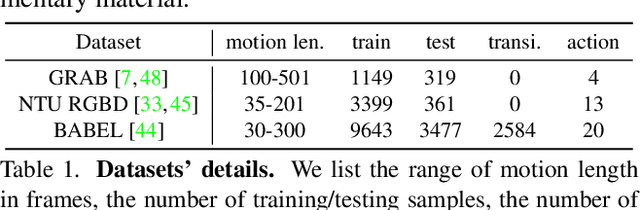
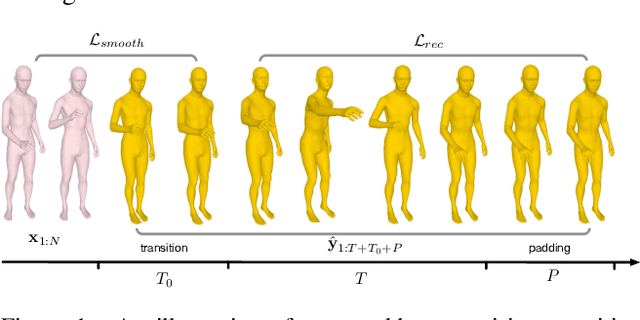
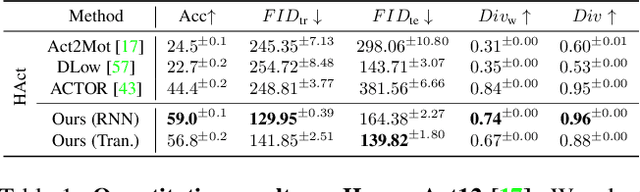
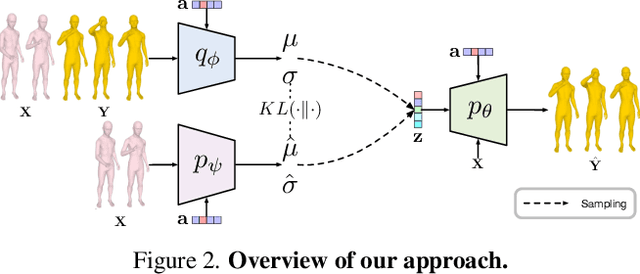
We introduce the task of action-driven stochastic human motion prediction, which aims to predict multiple plausible future motions given a sequence of action labels and a short motion history. This differs from existing works, which predict motions that either do not respect any specific action category, or follow a single action label. In particular, addressing this task requires tackling two challenges: The transitions between the different actions must be smooth; the length of the predicted motion depends on the action sequence and varies significantly across samples. As we cannot realistically expect training data to cover sufficiently diverse action transitions and motion lengths, we propose an effective training strategy consisting of combining multiple motions from different actions and introducing a weak form of supervision to encourage smooth transitions. We then design a VAE-based model conditioned on both the observed motion and the action label sequence, allowing us to generate multiple plausible future motions of varying length. We illustrate the generality of our approach by exploring its use with two different temporal encoding models, namely RNNs and Transformers. Our approach outperforms baseline models constructed by adapting state-of-the-art single action-conditioned motion generation methods and stochastic human motion prediction approaches to our new task of action-driven stochastic motion prediction. Our code is available at https://github.com/wei-mao-2019/WAT.
Non-parametric Depth Distribution Modelling based Depth Inference for Multi-view Stereo
May 08, 2022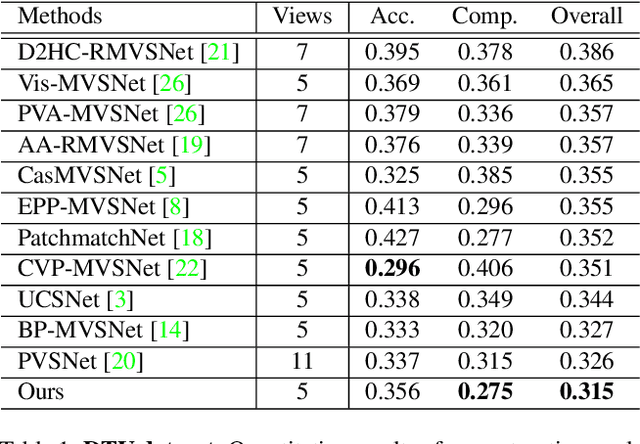
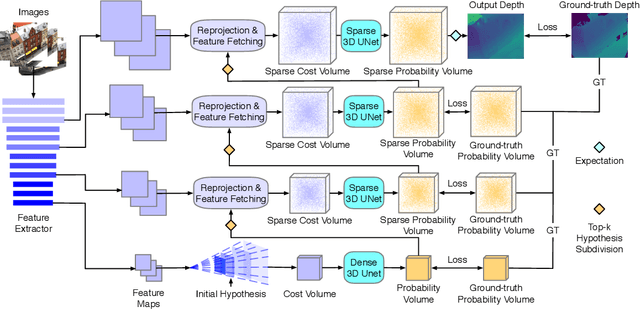
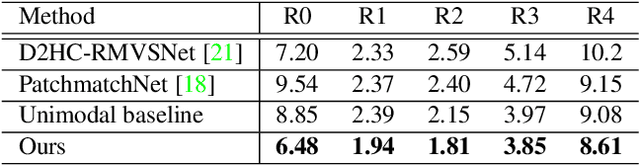
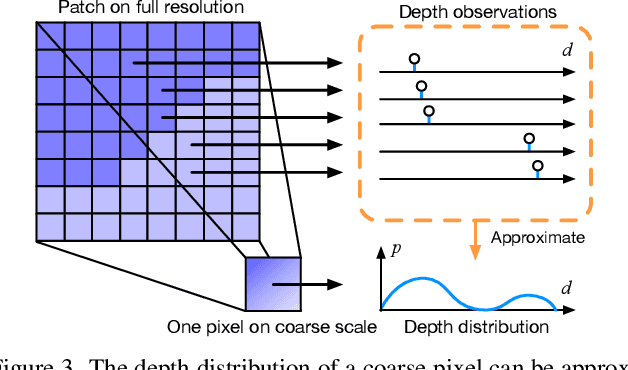
Recent cost volume pyramid based deep neural networks have unlocked the potential of efficiently leveraging high-resolution images for depth inference from multi-view stereo. In general, those approaches assume that the depth of each pixel follows a unimodal distribution. Boundary pixels usually follow a multi-modal distribution as they represent different depths; Therefore, the assumption results in an erroneous depth prediction at the coarser level of the cost volume pyramid and can not be corrected in the refinement levels leading to wrong depth predictions. In contrast, we propose constructing the cost volume by non-parametric depth distribution modeling to handle pixels with unimodal and multi-modal distributions. Our approach outputs multiple depth hypotheses at the coarser level to avoid errors in the early stage. As we perform local search around these multiple hypotheses in subsequent levels, our approach does not maintain the rigid depth spatial ordering and, therefore, we introduce a sparse cost aggregation network to derive information within each volume. We evaluate our approach extensively on two benchmark datasets: DTU and Tanks & Temples. Our experimental results show that our model outperforms existing methods by a large margin and achieves superior performance on boundary regions. Code is available at https://github.com/NVlabs/NP-CVP-MVSNet
SPA-VAE: Similar-Parts-Assignment for Unsupervised 3D Point Cloud Generation
Mar 15, 2022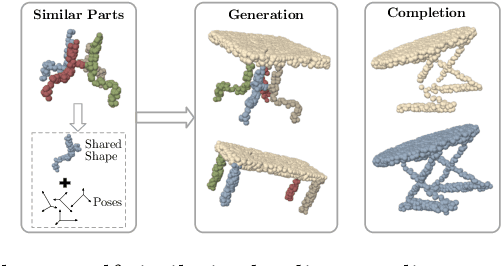
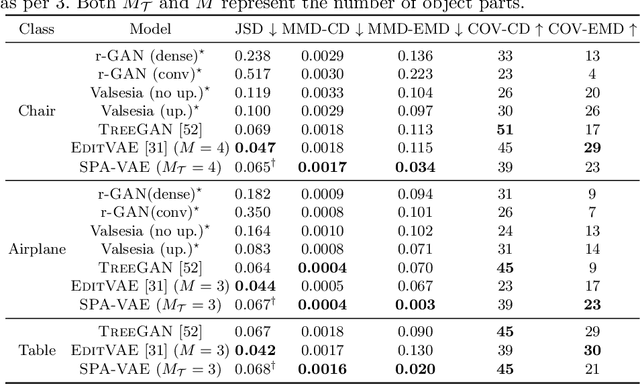

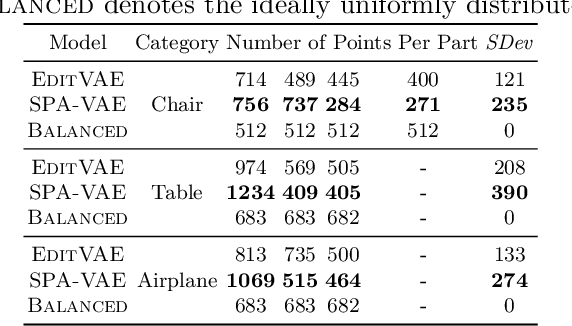
This paper addresses the problem of unsupervised parts-aware point cloud generation with learned parts-based self-similarity. Our SPA-VAE infers a set of latent canonical candidate shapes for any given object, along with a set of rigid body transformations for each such candidate shape to one or more locations within the assembled object. In this way, noisy samples on the surface of, say, each leg of a table, are effectively combined to estimate a single leg prototype. When parts-based self-similarity exists in the raw data, sharing data among parts in this way confers numerous advantages: modeling accuracy, appropriately self-similar generative outputs, precise in-filling of occlusions, and model parsimony. SPA-VAE is trained end-to-end using a variational Bayesian approach which uses the Gumbel-softmax trick for the shared part assignments, along with various novel losses to provide appropriate inductive biases. Quantitative and qualitative analyses on ShapeNet demonstrate the advantage of SPA-VAE.
Mining Meta-indicators of University Ranking: A Machine Learning Approach Based on SHAP
Nov 24, 2021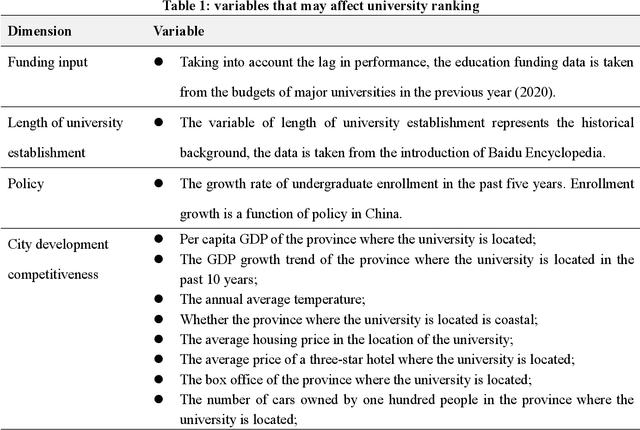
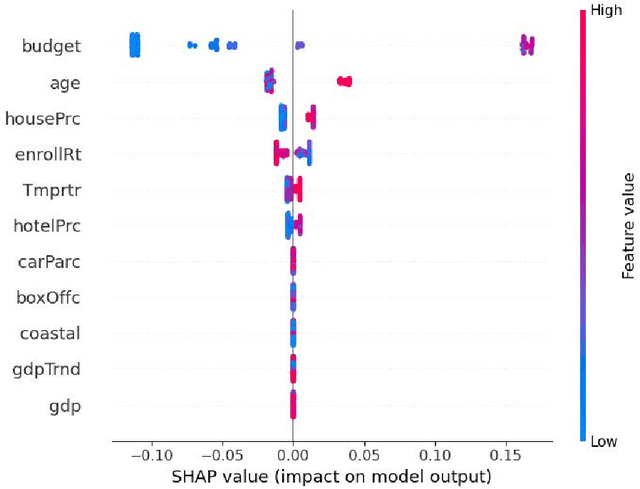
University evaluation and ranking is an extremely complex activity. Major universities are struggling because of increasingly complex indicator systems of world university rankings. So can we find the meta-indicators of the index system by simplifying the complexity? This research discovered three meta-indicators based on interpretable machine learning. The first one is time, to be friends with time, and believe in the power of time, and accumulate historical deposits; the second one is space, to be friends with city, and grow together by co-develop; the third one is relationships, to be friends with alumni, and strive for more alumni donations without ceiling.