 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Aspect and Opinion Words in Target-based Sentiment Analysis using Lifelong Learning
Feb 16, 2018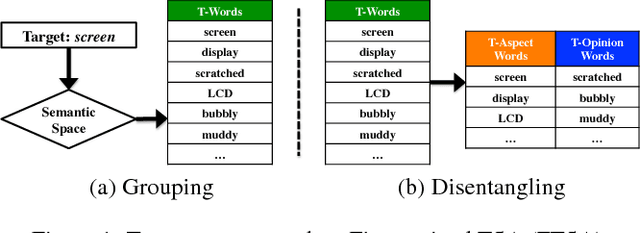

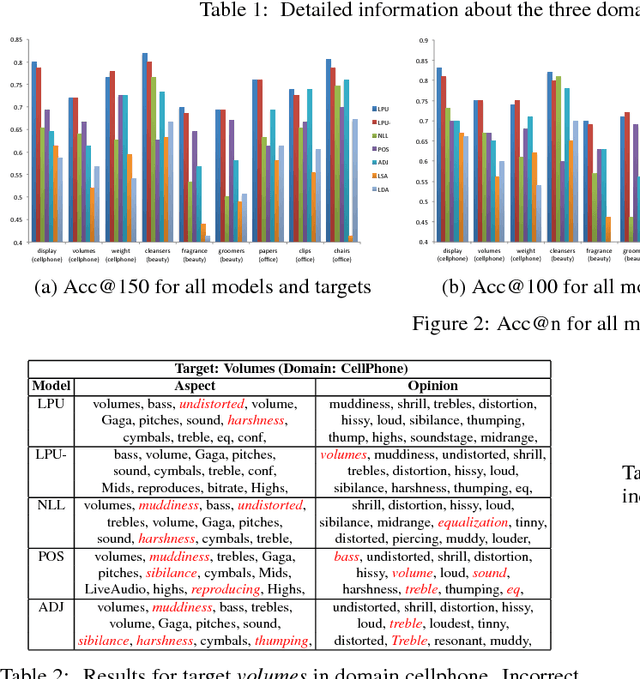
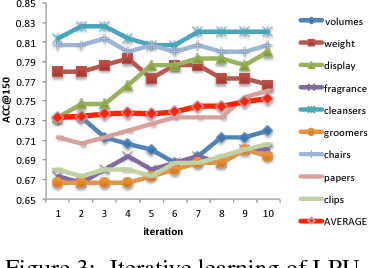
Given a target name, which can be a product aspect or entity, identifying its aspect words and opinion words in a given corpus is a fine-grained task in target-based sentiment analysis (TSA). This task is challenging, especially when we have no labeled data and we want to perform it for any given domain. To address it, we propose a general two-stage approach. Stage one extracts/groups the target-related words (call t-words) for a given target. This is relatively easy as we can apply an existing semantics-based learning technique. Stage two separates the aspect and opinion words from the grouped t-words, which is challenging because we often do not have enough word-level aspect and opinion labels. In this work, we formulate this problem in a PU learning setting and incorporate the idea of lifelong learning to solve it. Experimental results show the effectiveness of our approach.
Contextual and Position-Aware Factorization Machines for Sentiment Classification
Jan 18, 2018
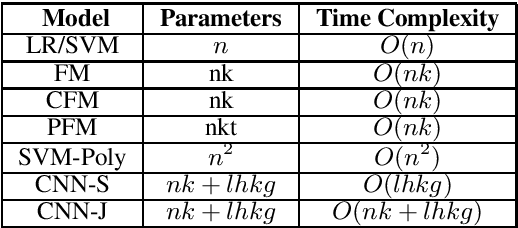
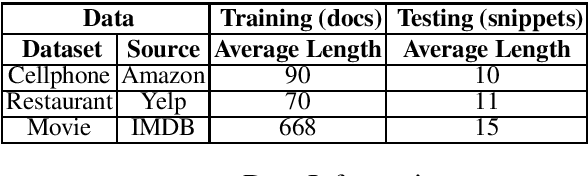
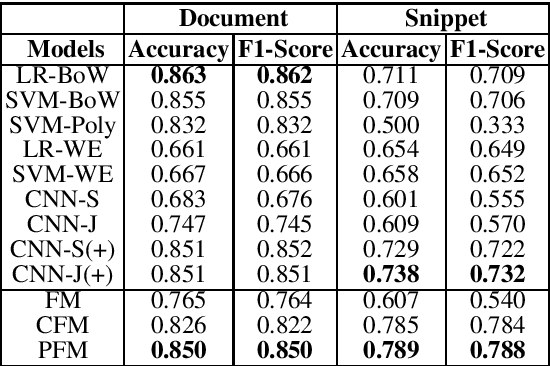
While existing machine learning models have achieved great success for sentiment classification, they typically do not explicitly capture sentiment-oriented word interaction, which can lead to poor results for fine-grained analysis at the snippet level (a phrase or sentence). Factorization Machine provides a possible approach to learning element-wise interaction for recommender systems, but they are not directly applicable to our task due to the inability to model contexts and word sequences. In this work, we develop two Position-aware Factorization Machines which consider word interaction, context and position information. Such information is jointly encoded in a set of sentiment-oriented word interaction vectors. Compared to traditional word embeddings, SWI vectors explicitly capture sentiment-oriented word interaction and simplify the parameter learning. Experimental results show that while they have comparable performance with state-of-the-art methods for document-level classification, they benefit the snippet/sentence-level sentiment analysis.