 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReason2Decide: Rationale-Driven Multi-Task Learning
Dec 23, 2025



Despite the wide adoption of Large Language Models (LLM)s, clinical decision support systems face a critical challenge: achieving high predictive accuracy while generating explanations aligned with the predictions. Current approaches suffer from exposure bias leading to misaligned explanations. We propose Reason2Decide, a two-stage training framework that addresses key challenges in self-rationalization, including exposure bias and task separation. In Stage-1, our model is trained on rationale generation, while in Stage-2, we jointly train on label prediction and rationale generation, applying scheduled sampling to gradually transition from conditioning on gold labels to model predictions. We evaluate Reason2Decide on three medical datasets, including a proprietary triage dataset and public biomedical QA datasets. Across model sizes, Reason2Decide outperforms other fine-tuning baselines and some zero-shot LLMs in prediction (F1) and rationale fidelity (BERTScore, BLEU, LLM-as-a-Judge). In triage, Reason2Decide is rationale source-robust across LLM-generated, nurse-authored, and nurse-post-processed rationales. In our experiments, while using only LLM-generated rationales in Stage-1, Reason2Decide outperforms other fine-tuning variants. This indicates that LLM-generated rationales are suitable for pretraining models, reducing reliance on human annotations. Remarkably, Reason2Decide achieves these gains with models 40x smaller than contemporary foundation models, making clinical reasoning more accessible for resource-constrained deployments while still providing explainable decision support.
On Generality and Knowledge Transferability in Cross-Domain Duplicate Question Detection for Heterogeneous Community Question Answering
Nov 15, 2018
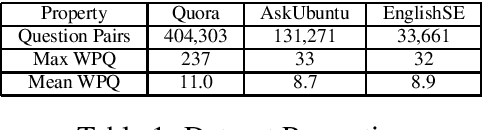
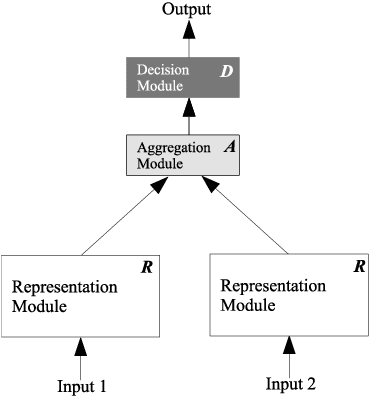
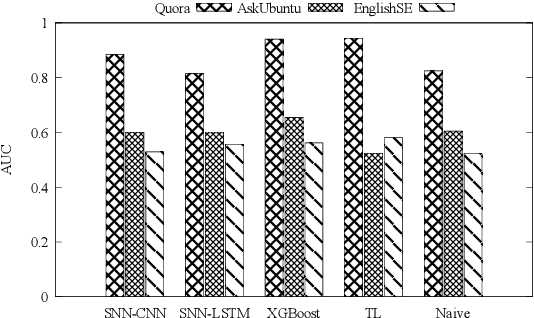
Duplicate question detection is an ongoing challenge in community question answering because semantically equivalent questions can have significantly different words and structures. In addition, the identification of duplicate questions can reduce the resources required for retrieval, when the same questions are not repeated. This study compares the performance of deep neural networks and gradient tree boosting, and explores the possibility of domain adaptation with transfer learning to improve the under-performing target domains for the text-pair duplicates classification task, using three heterogeneous datasets: general-purpose Quora, technical Ask Ubuntu, and academic English Stack Exchange. Ultimately, our study exposes the alternative hypothesis that the meaning of a "duplicate" is not inherently general-purpose, but rather is dependent on the domain of learning, hence reducing the chance of transfer learning through adapting to the domain.