 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentLTV: An Agent-Based Unified Search-and-Evolution Framework for Automated Lifetime Value Prediction
Feb 25, 2026Lifetime Value (LTV) prediction is critical in advertising, recommender systems, and e-commerce. In practice, LTV data patterns vary across decision scenarios. As a result, practitioners often build complex, scenario-specific pipelines and iterate over feature processing, objective design, and tuning. This process is expensive and hard to transfer. We propose AgentLTV, an agent-based unified search-and-evolution framework for automated LTV modeling. AgentLTV treats each candidate solution as an {executable pipeline program}. LLM-driven agents generate code, run and repair pipelines, and analyze execution feedback. Two decision agents coordinate a two-stage search. The Monte Carlo Tree Search (MCTS) stage explores a broad space of modeling choices under a fixed budget, guided by the Polynomial Upper Confidence bounds for Trees criterion and a Pareto-aware multi-metric value function. The Evolutionary Algorithm (EA) stage refines the best MCTS program via island-based evolution with crossover, mutation, and migration. Experiments on a large-scale proprietary dataset and a public benchmark show that AgentLTV consistently discovers strong models across ranking and error metrics. Online bucket-level analysis further indicates improved ranking consistency and value calibration, especially for high-value and negative-LTV segments. We summarize practitioner-oriented takeaways: use MCTS for rapid adaptation to new data patterns, use EA for stable refinement, and validate deployment readiness with bucket-level ranking and calibration diagnostics. The proposed AgentLTV has been successfully deployed online.
SHORE: A Long-term User Lifetime Value Prediction Model in Digital Games
Jun 12, 2025In digital gaming, long-term user lifetime value (LTV) prediction is essential for monetization strategy, yet presents major challenges due to delayed payment behavior, sparse early user data, and the presence of high-value outliers. While existing models typically rely on either short-cycle observations or strong distributional assumptions, such approaches often underestimate long-term value or suffer from poor robustness. To address these issues, we propose SHort-cycle auxiliary with Order-preserving REgression (SHORE), a novel LTV prediction framework that integrates short-horizon predictions (e.g., LTV-15 and LTV-30) as auxiliary tasks to enhance long-cycle targets (e.g., LTV-60). SHORE also introduces a hybrid loss function combining order-preserving multi-class classification and a dynamic Huber loss to mitigate the influence of zero-inflation and outlier payment behavior. Extensive offline and online experiments on real-world datasets demonstrate that SHORE significantly outperforms existing baselines, achieving a 47.91\% relative reduction in prediction error in online deployment. These results highlight SHORE's practical effectiveness and robustness in industrial-scale LTV prediction for digital games.
HIT Model: A Hierarchical Interaction-Enhanced Two-Tower Model for Pre-Ranking Systems
May 26, 2025Online display advertising platforms rely on pre-ranking systems to efficiently filter and prioritize candidate ads from large corpora, balancing relevance to users with strict computational constraints. The prevailing two-tower architecture, though highly efficient due to its decoupled design and pre-caching, suffers from cross-domain interaction and coarse similarity metrics, undermining its capacity to model complex user-ad relationships. In this study, we propose the Hierarchical Interaction-Enhanced Two-Tower (HIT) model, a new architecture that augments the two-tower paradigm with two key components: $\textit{generators}$ that pre-generate holistic vectors incorporating coarse-grained user-ad interactions through a dual-generator framework with a cosine-similarity-based generation loss as the training objective, and $\textit{multi-head representers}$ that project embeddings into multiple latent subspaces to capture fine-grained, multi-faceted user interests and multi-dimensional ad attributes. This design enhances modeling effectiveness without compromising inference efficiency. Extensive experiments on public datasets and large-scale online A/B testing on Tencent's advertising platform demonstrate that HIT significantly outperforms several baselines in relevance metrics, yielding a $1.66\%$ increase in Gross Merchandise Volume and a $1.55\%$ improvement in Return on Investment, alongside similar serving latency to the vanilla two-tower models. The HIT model has been successfully deployed in Tencent's online display advertising system, serving billions of impressions daily. The code is available at https://anonymous.4open.science/r/HIT_model-5C23.
An interpretable neural network model through piecewise linear approximation
Jan 20, 2020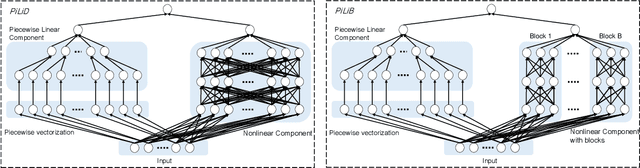
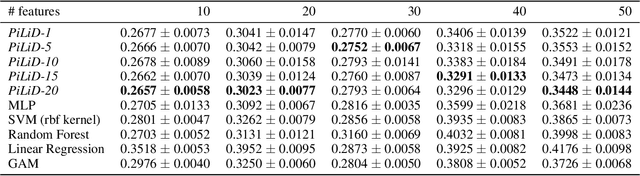

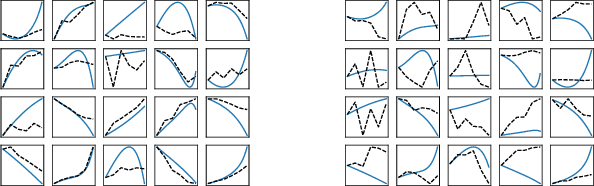
Most existing interpretable methods explain a black-box model in a post-hoc manner, which uses simpler models or data analysis techniques to interpret the predictions after the model is learned. However, they (a) may derive contradictory explanations on the same predictions given different methods and data samples, and (b) focus on using simpler models to provide higher descriptive accuracy at the sacrifice of prediction accuracy. To address these issues, we propose a hybrid interpretable model that combines a piecewise linear component and a nonlinear component. The first component describes the explicit feature contributions by piecewise linear approximation to increase the expressiveness of the model. The other component uses a multi-layer perceptron to capture feature interactions and implicit nonlinearity, and increase the prediction performance. Different from the post-hoc approaches, the interpretability is obtained once the model is learned in the form of feature shapes. We also provide a variant to explore higher-order interactions among features to demonstrate that the proposed model is flexible for adaptation. Experiments demonstrate that the proposed model can achieve good interpretability by describing feature shapes while maintaining state-of-the-art accuracy.
Explainable Ordinal Factorization Model: Deciphering the Effects of Attributes by Piece-wise Linear Approximation
Nov 14, 2019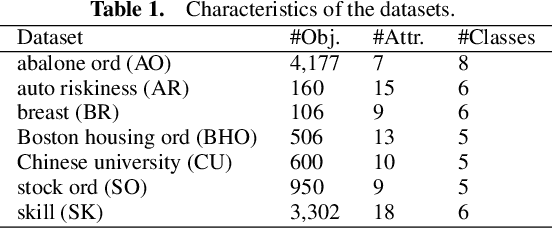
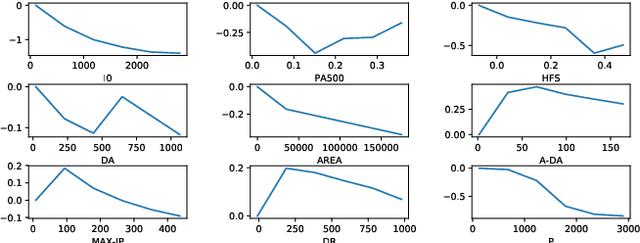

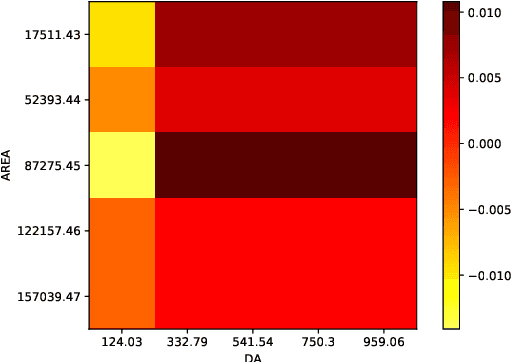
Ordinal regression predicts the objects' labels that exhibit a natural ordering, which is important to many managerial problems such as credit scoring and clinical diagnosis. In these problems, the ability to explain how the attributes affect the prediction is critical to users. However, most, if not all, existing ordinal regression models simplify such explanation in the form of constant coefficients for the main and interaction effects of individual attributes. Such explanation cannot characterize the contributions of attributes at different value scales. To address this challenge, we propose a new explainable ordinal regression model, namely, the Explainable Ordinal Factorization Model (XOFM). XOFM uses the piece-wise linear functions to approximate the actual contributions of individual attributes and their interactions. Moreover, XOFM introduces a novel ordinal transformation process to assign each object the probabilities of belonging to multiple relevant classes, instead of fixing boundaries to differentiate classes. XOFM is based on the Factorization Machines to handle the potential sparsity problem as a result of discretizing the attribute scales. Comprehensive experiments with benchmark datasets and baseline models demonstrate that the proposed XOFM exhibits superior explainability and leads to state-of-the-art prediction accuracy.
An interpretable machine learning framework for modelling human decision behavior
Jun 04, 2019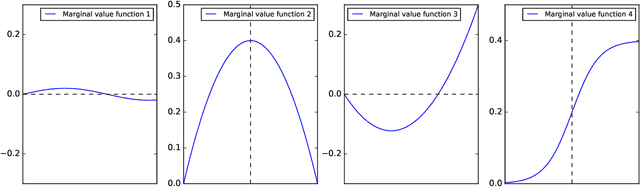
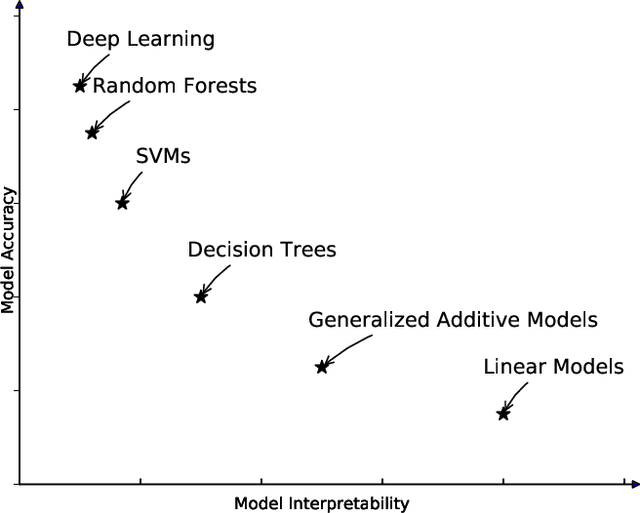
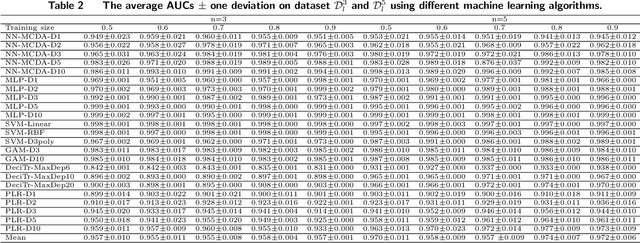
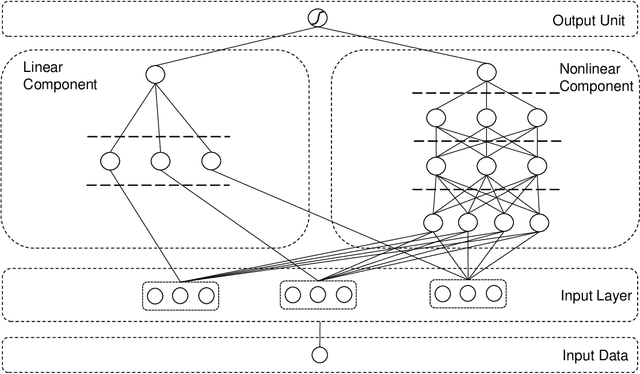
Machine learning has recently been widely adopted to address the managerial decision making problems. However, there is a trade-off between performance and interpretability. Full complexity models (such as neural network-based models) are non-traceable black-box, whereas classic interpretable models (such as logistic regression) are usually simplified with lower accuracy. This trade-off limits the application of state-of-the-art machine learning models in management problems, which requires high prediction performance, as well as the understanding of individual attributes' contributions to the model outcome. Multiple criteria decision aiding (MCDA) is a family of interpretable approaches to depicting the rationale of human decision behavior. It is also limited by strong assumptions (e.g. preference independence). In this paper, we propose an interpretable machine learning approach, namely Neural Network-based Multiple Criteria Decision Aiding (NN-MCDA), which combines an additive MCDA model and a fully-connected multilayer perceptron (MLP) to achieve good performance while preserving a certain degree of interpretability. NN-MCDA has a linear component (in an additive form of a set of polynomial functions) to capture the detailed relationship between individual attributes and the prediction, and a nonlinear component (in a standard MLP form) to capture the high-order interactions between attributes and their complex nonlinear transformations. We demonstrate the effectiveness of NN-MCDA with extensive simulation studies and two real-world datasets. To the best of our knowledge, this research is the first to enhance the interpretability of machine learning models with MCDA techniques. The proposed framework also sheds light on how to use machine learning techniques to free MCDA from strong assumptions.