 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Spacecraft Attitude Control During Atmospheric Re-Entry
Jun 30, 2026Deep reinforcement learning has the potential to solve attitude control problems more adaptively, precisely, and robustly by handling nonlinear dynamics, uncertainties, and failure cases more effectively than traditional attitude control approaches. We explore reinforcement learning (RL) for attitude control in spacecraft re-entry. An industry-standard proportional-integral-derivative controller with gain scheduling serves as a strong baseline for model-free RL and hybrid controllers that combine these two approaches. We formalize the application in the RL framework to apply continuous, off-policy RL. State-of-the-art RL achieves comparable performance to traditional control approaches in this domain. However, its out-of-distribution generalization is not sufficient. Hence, we use dynamics randomization to introduce challenging task variations during training and enforce generalization in a predefined operational envelope. Finally, we assess the best obtained RL-based controllers with application-specific metrics to show superior performance in comparison to traditional controllers in the operational envelope, that is, hybrid controllers are able to track the angle of attack better and are more robust under variations of mass, inertia tensor, and flap actuator bandwidth.
Task-specific Subnetwork Discovery in Reinforcement Learning for Autonomous Underwater Navigation
Apr 23, 2026Autonomous underwater vehicles are required to perform multiple tasks adaptively and in an explainable manner under dynamic, uncertain conditions and limited sensing, challenges that classical controllers struggle to address. This demands robust, generalizable, and inherently interpretable control policies for reliable long-term monitoring. Reinforcement learning, particularly multi-task RL, overcomes these limitations by leveraging shared representations to enable efficient adaptation across tasks and environments. However, while such policies show promising results in simulation and controlled experiments, they yet remain opaque and offer limited insight into the agent's internal decision-making, creating gaps in transparency, trust, and safety that hinder real-world deployment. The internal policy structure and task-specific specialization remain poorly understood. To address these gaps, we analyze the internal structure of a pretrained multi-task reinforcement learning network in the HoloOcean simulator for underwater navigation by identifying and comparing task-specific subnetworks responsible for navigating toward different species. We find that in a contextual multi-task reinforcement learning setting with related tasks, the network uses only about 1.5% of its weights to differentiate between tasks. Of these, approximately 85% connect the context-variable nodes in the input layer to the next hidden layer, highlighting the importance of context variables in such settings. Our approach provides insights into shared and specialized network components, useful for efficient model editing, transfer learning, and continual learning for underwater monitoring through a contextual multi-task reinforcement learning method.
DINO-Explorer: Active Underwater Discovery via Ego-Motion Compensated Semantic Predictive Coding
Apr 14, 2026Marine ecosystem degradation necessitates continuous, scientifically selective underwater monitoring. However, most autonomous underwater vehicles (AUVs) operate as passive data loggers, capturing exhaustive video for offline review and frequently missing transient events of high scientific value. Transitioning to active perception requires a causal, online signal that highlights significant phenomena while suppressing maneuver-induced visual changes. We propose DINO-Explorer, a novelty-aware perception framework driven by a continuous semantic surprise signal. Operating within the latent space of a frozen DINOv3 foundation model, it leverages a lightweight, action-conditioned recurrent predictor to anticipate short-horizon semantic evolution. An efference-copy-inspired module utilizes globally pooled optical flow to discount self-induced visual changes without suppressing genuine environmental novelty. We evaluate this signal on the downstream task of asynchronous event triage under variant telemetry constraints. Results demonstrate that DINO-Explorer provides a robust, bandwidth-efficient attention mechanism. At a fixed operating point, the system retains 78.8% of post-discovery human-reviewer consensus events with a 56.8% trigger confirmation rate, effectively surfacing mission-relevant phenomena. Crucially, ego-motion conditioning suppresses 45.5% of false positives relative to an uncompensated surprise signal baseline. In a replay-side Pareto ablation study, DINO-Explorer robustly dominates the validated peak F1 versus telemetry bandwidth frontier, reducing telemetry bandwidth by 48.2% at the selected operating point while maintaining a 62.2% peak F1 score, successfully concentrating data transmission around human-verified novelty events.
Contextual Multi-Task Reinforcement Learning for Autonomous Reef Monitoring
Apr 14, 2026Although autonomous underwater vehicles promise the capability of marine ecosystem monitoring, their deployment is fundamentally limited by the difficulty of controlling vehicles under highly uncertain and non-stationary underwater dynamics. To address these challenges, we employ a data-driven reinforcement learning approach to compensate for unknown dynamics and task variations.Traditional single-task reinforcement learning has a tendency to overfit the training environment, thus, limit the long-term usefulness of the learnt policy. Hence, we propose to use a contextual multi-task reinforcement learning paradigm instead, allowing us to learn controllers that can be reused for various tasks, e.g., detecting oysters in one reef and detecting corals in another. We evaluate whether contextual multi-task reinforcement learning can efficiently learn robust and generalisable control policies for autonomous underwater reef monitoring. We train a single context-dependent policy that is able to solve multiple related monitoring tasks in a simulated reef environment in HoloOcean. In our experiments, we empirically evaluate the contextual policies regarding sample-efficiency, zero-shot generalisation to unseen tasks, and robustness to varying water currents. By utilising multi-task reinforcement learning, we aim to improve the training effectiveness, as well as the reusability of learnt policies to take a step towards more sustainable procedures in autonomous reef monitoring.
Bayesian Inverse Physics for Neuro-Symbolic Robot Learning
Jun 10, 2025Real-world robotic applications, from autonomous exploration to assistive technologies, require adaptive, interpretable, and data-efficient learning paradigms. While deep learning architectures and foundation models have driven significant advances in diverse robotic applications, they remain limited in their ability to operate efficiently and reliably in unknown and dynamic environments. In this position paper, we critically assess these limitations and introduce a conceptual framework for combining data-driven learning with deliberate, structured reasoning. Specifically, we propose leveraging differentiable physics for efficient world modeling, Bayesian inference for uncertainty-aware decision-making, and meta-learning for rapid adaptation to new tasks. By embedding physical symbolic reasoning within neural models, robots could generalize beyond their training data, reason about novel situations, and continuously expand their knowledge. We argue that such hybrid neuro-symbolic architectures are essential for the next generation of autonomous systems, and to this end, we provide a research roadmap to guide and accelerate their development.
A Modular Approach to the Embodiment of Hand Motions from Human Demonstrations
Mar 05, 2022



Manipulating objects with robotic hands is a complicated task. Not only the pose of the robot's end effector, but also the fingers of the hand need to be controlled and coordinated. Using human demonstrations of movements is an intuitive and data-efficient way of guiding the robot's behavior. We propose a modular framework with an automatic embodiment mapping to transfer human hand motions to robotic systems and use motion capture to record human motion. We evaluate our approach on eight challenging tasks, in which a robotic arm with a mounted robotic hand needs to grasp and manipulate deformable objects or small, fragile material.
Deep Adversarial Reinforcement Learning for Object Disentangling
Mar 08, 2020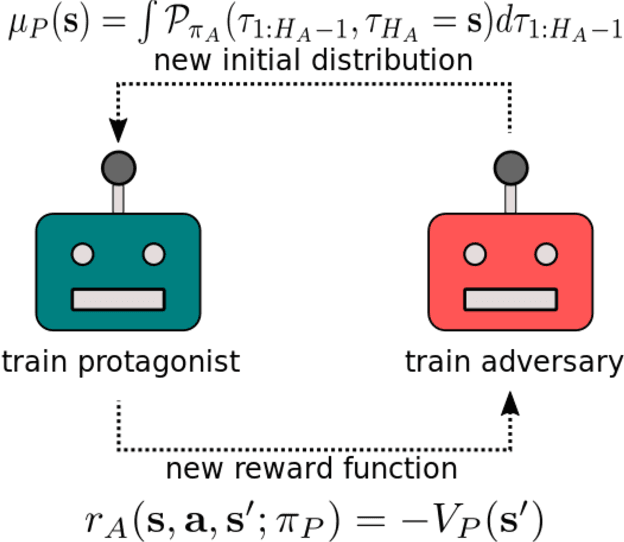



Deep learning in combination with improved training techniques and high computational power has led to recent advances in the field of reinforcement learning (RL) and to successful robotic RL applications such as in-hand manipulation. However, most robotic RL relies on a well known initial state distribution. In real-world tasks, this information is however often not available. For example, when disentangling waste objects the actual position of the robot w.r.t.\ the objects may not match the positions the RL policy was trained for. To solve this problem, we present a novel adversarial reinforcement learning (ARL) framework. The ARL framework utilizes an adversary, which is trained to steer the original agent, the protagonist, to challenging states. We train the protagonist and the adversary jointly to allow them to adapt to the changing policy of their opponent. We show that our method can generalize from training to test scenarios by training an end-to-end system for robot control to solve a challenging object disentangling task. Experiments with a KUKA LBR+ 7-DOF robot arm show that our approach outperforms the baseline method in disentangling when starting from different initial states than provided during training.