 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCase-Grounded Evidence Verification: A Framework for Constructing Evidence-Sensitive Supervision
Apr 10, 2026Evidence-grounded reasoning requires more than attaching retrieved text to a prediction: a model should make decisions that depend on whether the provided evidence supports the target claim. In practice, this often fails because supervision is weak, evidence is only loosely tied to the claim, and evaluation does not test evidence dependence directly. We introduce case-grounded evidence verification, a general framework in which a model receives a local case context, external evidence, and a structured claim, and must decide whether the evidence supports the claim for that case. Our key contribution is a supervision construction procedure that generates explicit support examples together with semantically controlled non-support examples, including counterfactual wrong-state and topic-related negatives, without manual evidence annotation. We instantiate the framework in radiology and train a standard verifier on the resulting support task. The learned verifier substantially outperforms both case-only and evidence-only baselines, remains strong under correct evidence, and collapses when evidence is removed or swapped, indicating genuine evidence dependence. This behavior transfers across unseen evidence articles and an external case distribution, though performance degrades under evidence-source shift and remains sensitive to backbone choice. Overall, the results suggest that a major bottleneck in evidence grounding is not only model capacity, but the lack of supervision that encodes the causal role of evidence.
Boosting multi-demographic federated learning for chest x-ray analysis using general-purpose self-supervised representations
Apr 11, 2025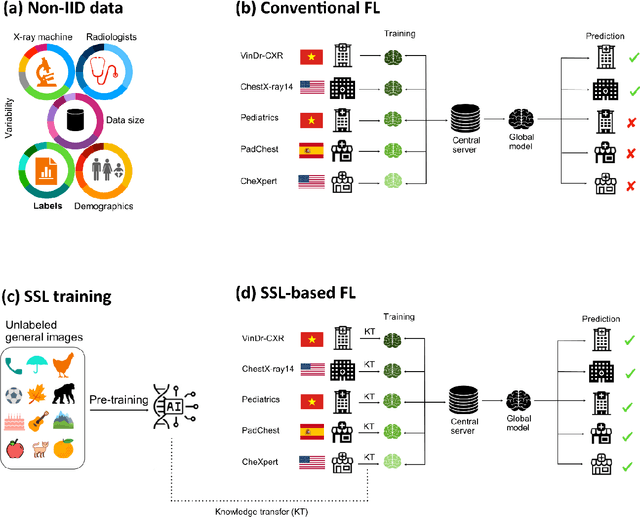



Reliable artificial intelligence (AI) models for medical image analysis often depend on large and diverse labeled datasets. Federated learning (FL) offers a decentralized and privacy-preserving approach to training but struggles in highly non-independent and identically distributed (non-IID) settings, where institutions with more representative data may experience degraded performance. Moreover, existing large-scale FL studies have been limited to adult datasets, neglecting the unique challenges posed by pediatric data, which introduces additional non-IID variability. To address these limitations, we analyzed n=398,523 adult chest radiographs from diverse institutions across multiple countries and n=9,125 pediatric images, leveraging transfer learning from general-purpose self-supervised image representations to classify pneumonia and cases with no abnormality. Using state-of-the-art vision transformers, we found that FL improved performance only for smaller adult datasets (P<0.001) but degraded performance for larger datasets (P<0.064) and pediatric cases (P=0.242). However, equipping FL with self-supervised weights significantly enhanced outcomes across pediatric cases (P=0.031) and most adult datasets (P<0.008), except the largest dataset (P=0.052). These findings underscore the potential of easily deployable general-purpose self-supervised image representations to address non-IID challenges in clinical FL applications and highlight their promise for enhancing patient outcomes and advancing pediatric healthcare, where data scarcity and variability remain persistent obstacles.