 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Model-Mediated Stacked Ensemble Approach for Depression Prediction Among Professionals
Jun 17, 2025Depression is a significant mental health concern, particularly in professional environments where work-related stress, financial pressure, and lifestyle imbalances contribute to deteriorating well-being. Despite increasing awareness, researchers and practitioners face critical challenges in developing accurate and generalizable predictive models for mental health disorders. Traditional classification approaches often struggle with the complexity of depression, as it is influenced by multifaceted, interdependent factors, including occupational stress, sleep patterns, and job satisfaction. This study addresses these challenges by proposing a stacking-based ensemble learning approach to improve the predictive accuracy of depression classification among professionals. The Depression Professional Dataset has been collected from Kaggle. The dataset comprises demographic, occupational, and lifestyle attributes that influence mental well-being. Our stacking model integrates multiple base learners with a logistic regression-mediated model, effectively capturing diverse learning patterns. The experimental results demonstrate that the proposed model achieves high predictive performance, with an accuracy of 99.64% on training data and 98.75% on testing data, with precision, recall, and F1-score all exceeding 98%. These findings highlight the effectiveness of ensemble learning in mental health analytics and underscore its potential for early detection and intervention strategies.
Local Feature or Mel Frequency Cepstral Coefficients - Which One is Better for MLN-Based Bangla Speech Recognition?
Oct 05, 2013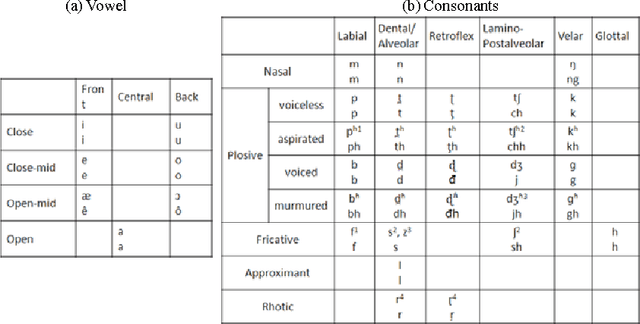
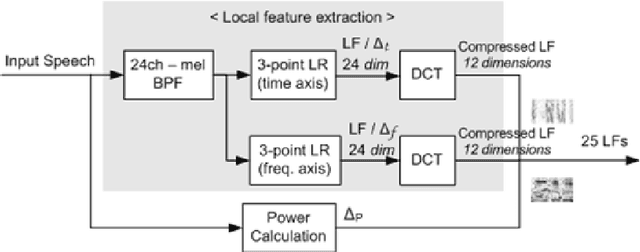
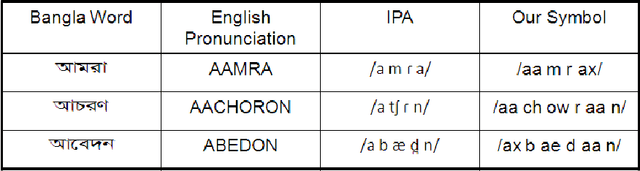

This paper discusses the dominancy of local features (LFs), as input to the multilayer neural network (MLN), extracted from a Bangla input speech over mel frequency cepstral coefficients (MFCCs). Here, LF-based method comprises three stages: (i) LF extraction from input speech, (ii) phoneme probabilities extraction using MLN from LF and (iii) the hidden Markov model (HMM) based classifier to obtain more accurate phoneme strings. In the experiments on Bangla speech corpus prepared by us, it is observed that the LFbased automatic speech recognition (ASR) system provides higher phoneme correct rate than the MFCC-based system. Moreover, the proposed system requires fewer mixture components in the HMMs.