 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Feature or Mel Frequency Cepstral Coefficients - Which One is Better for MLN-Based Bangla Speech Recognition?
Oct 05, 2013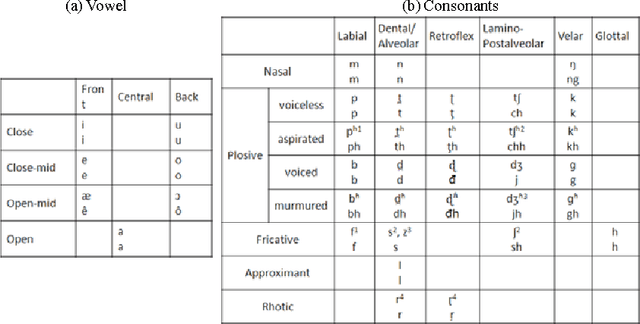
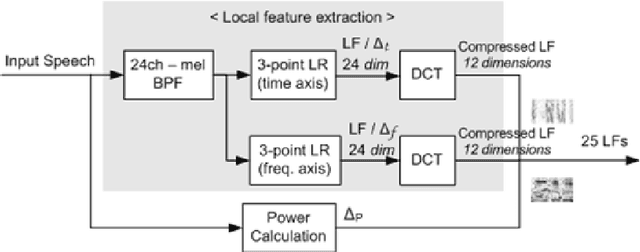
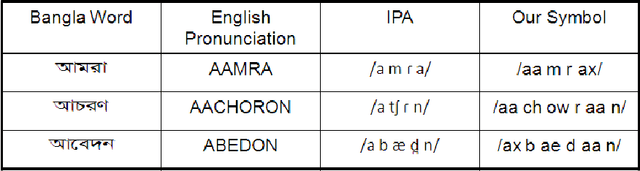

This paper discusses the dominancy of local features (LFs), as input to the multilayer neural network (MLN), extracted from a Bangla input speech over mel frequency cepstral coefficients (MFCCs). Here, LF-based method comprises three stages: (i) LF extraction from input speech, (ii) phoneme probabilities extraction using MLN from LF and (iii) the hidden Markov model (HMM) based classifier to obtain more accurate phoneme strings. In the experiments on Bangla speech corpus prepared by us, it is observed that the LFbased automatic speech recognition (ASR) system provides higher phoneme correct rate than the MFCC-based system. Moreover, the proposed system requires fewer mixture components in the HMMs.
A State of the Art of Word Sense Induction: A Way Towards Word Sense Disambiguation for Under-Resourced Languages
Oct 05, 2013Word Sense Disambiguation (WSD), the process of automatically identifying the meaning of a polysemous word in a sentence, is a fundamental task in Natural Language Processing (NLP). Progress in this approach to WSD opens up many promising developments in the field of NLP and its applications. Indeed, improvement over current performance levels could allow us to take a first step towards natural language understanding. Due to the lack of lexical resources it is sometimes difficult to perform WSD for under-resourced languages. This paper is an investigation on how to initiate research in WSD for under-resourced languages by applying Word Sense Induction (WSI) and suggests some interesting topics to focus on.