 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoze: Sports Technique Feedback under Data Constraints
Nov 08, 2024Access to expert coaching is essential for developing technique in sports, yet economic barriers often place it out of reach for many enthusiasts. To bridge this gap, we introduce Poze, an innovative video processing framework that provides feedback on human motion, emulating the insights of a professional coach. Poze combines pose estimation with sequence comparison and is optimized to function effectively with minimal data. Poze surpasses state-of-the-art vision-language models in video question-answering frameworks, achieving 70% and 196% increase in accuracy over GPT4V and LLaVAv1.6 7b, respectively.
Discerning the Chaos: Detecting Adversarial Perturbations while Disentangling Intentional from Unintentional Noises
Sep 29, 2024Deep learning models, such as those used for face recognition and attribute prediction, are susceptible to manipulations like adversarial noise and unintentional noise, including Gaussian and impulse noise. This paper introduces CIAI, a Class-Independent Adversarial Intent detection network built on a modified vision transformer with detection layers. CIAI employs a novel loss function that combines Maximum Mean Discrepancy and Center Loss to detect both intentional (adversarial attacks) and unintentional noise, regardless of the image class. It is trained in a multi-step fashion. We also introduce the aspect of intent during detection that can act as an added layer of security. We further showcase the performance of our proposed detector on CelebA, CelebA-HQ, LFW, AgeDB, and CIFAR-10 datasets. Our detector is able to detect both intentional (like FGSM, PGD, and DeepFool) and unintentional (like Gaussian and Salt & Pepper noises) perturbations.
HyperSpaceX: Radial and Angular Exploration of HyperSpherical Dimensions
Aug 05, 2024Traditional deep learning models rely on methods such as softmax cross-entropy and ArcFace loss for tasks like classification and face recognition. These methods mainly explore angular features in a hyperspherical space, often resulting in entangled inter-class features due to dense angular data across many classes. In this paper, a new field of feature exploration is proposed known as HyperSpaceX which enhances class discrimination by exploring both angular and radial dimensions in multi-hyperspherical spaces, facilitated by a novel DistArc loss. The proposed DistArc loss encompasses three feature arrangement components: two angular and one radial, enforcing intra-class binding and inter-class separation in multi-radial arrangement, improving feature discriminability. Evaluation of HyperSpaceX framework for the novel representation utilizes a proposed predictive measure that accounts for both angular and radial elements, providing a more comprehensive assessment of model accuracy beyond standard metrics. Experiments across seven object classification and six face recognition datasets demonstrate state-of-the-art (SoTA) results obtained from HyperSpaceX, achieving up to a 20% performance improvement on large-scale object datasets in lower dimensions and up to 6% gain in higher dimensions.
Navigating Text-to-Image Generative Bias across Indic Languages
Aug 01, 2024



This research investigates biases in text-to-image (TTI) models for the Indic languages widely spoken across India. It evaluates and compares the generative performance and cultural relevance of leading TTI models in these languages against their performance in English. Using the proposed IndicTTI benchmark, we comprehensively assess the performance of 30 Indic languages with two open-source diffusion models and two commercial generation APIs. The primary objective of this benchmark is to evaluate the support for Indic languages in these models and identify areas needing improvement. Given the linguistic diversity of 30 languages spoken by over 1.4 billion people, this benchmark aims to provide a detailed and insightful analysis of TTI models' effectiveness within the Indic linguistic landscape. The data and code for the IndicTTI benchmark can be accessed at https://iab-rubric.org/resources/other-databases/indictti.
Low-Resolution Chest X-ray Classification via Knowledge Distillation and Multi-task Learning
May 22, 2024



This research addresses the challenges of diagnosing chest X-rays (CXRs) at low resolutions, a common limitation in resource-constrained healthcare settings. High-resolution CXR imaging is crucial for identifying small but critical anomalies, such as nodules or opacities. However, when images are downsized for processing in Computer-Aided Diagnosis (CAD) systems, vital spatial details and receptive fields are lost, hampering diagnosis accuracy. To address this, this paper presents the Multilevel Collaborative Attention Knowledge (MLCAK) method. This approach leverages the self-attention mechanism of Vision Transformers (ViT) to transfer critical diagnostic knowledge from high-resolution images to enhance the diagnostic efficacy of low-resolution CXRs. MLCAK incorporates local pathological findings to boost model explainability, enabling more accurate global predictions in a multi-task framework tailored for low-resolution CXR analysis. Our research, utilizing the Vindr CXR dataset, shows a considerable enhancement in the ability to diagnose diseases from low-resolution images (e.g. 28 x 28), suggesting a critical transition from the traditional reliance on high-resolution imaging (e.g. 224 x 224).
Learn "No" to Say "Yes" Better: Improving Vision-Language Models via Negations
Mar 29, 2024



Existing vision-language models (VLMs) treat text descriptions as a unit, confusing individual concepts in a prompt and impairing visual semantic matching and reasoning. An important aspect of reasoning in logic and language is negations. This paper highlights the limitations of popular VLMs such as CLIP, at understanding the implications of negations, i.e., the effect of the word "not" in a given prompt. To enable evaluation of VLMs on fluent prompts with negations, we present CC-Neg, a dataset containing 228,246 images, true captions and their corresponding negated captions. Using CC-Neg along with modifications to the contrastive loss of CLIP, our proposed CoN-CLIP framework, has an improved understanding of negations. This training paradigm improves CoN-CLIP's ability to encode semantics reliably, resulting in 3.85% average gain in top-1 accuracy for zero-shot image classification across 8 datasets. Further, CoN-CLIP outperforms CLIP on challenging compositionality benchmarks such as SugarCREPE by 4.4%, showcasing emergent compositional understanding of objects, relations, and attributes in text. Overall, our work addresses a crucial limitation of VLMs by introducing a dataset and framework that strengthens semantic associations between images and text, demonstrating improved large-scale foundation models with significantly reduced computational cost, promoting efficiency and accessibility.
Optimizing Skin Lesion Classification via Multimodal Data and Auxiliary Task Integration
Feb 16, 2024



The rising global prevalence of skin conditions, some of which can escalate to life-threatening stages if not timely diagnosed and treated, presents a significant healthcare challenge. This issue is particularly acute in remote areas where limited access to healthcare often results in delayed treatment, allowing skin diseases to advance to more critical stages. One of the primary challenges in diagnosing skin diseases is their low inter-class variations, as many exhibit similar visual characteristics, making accurate classification challenging. This research introduces a novel multimodal method for classifying skin lesions, integrating smartphone-captured images with essential clinical and demographic information. This approach mimics the diagnostic process employed by medical professionals. A distinctive aspect of this method is the integration of an auxiliary task focused on super-resolution image prediction. This component plays a crucial role in refining visual details and enhancing feature extraction, leading to improved differentiation between classes and, consequently, elevating the overall effectiveness of the model. The experimental evaluations have been conducted using the PAD-UFES20 dataset, applying various deep-learning architectures. The results of these experiments not only demonstrate the effectiveness of the proposed method but also its potential applicability under-resourced healthcare environments.
Adventures of Trustworthy Vision-Language Models: A Survey
Dec 07, 2023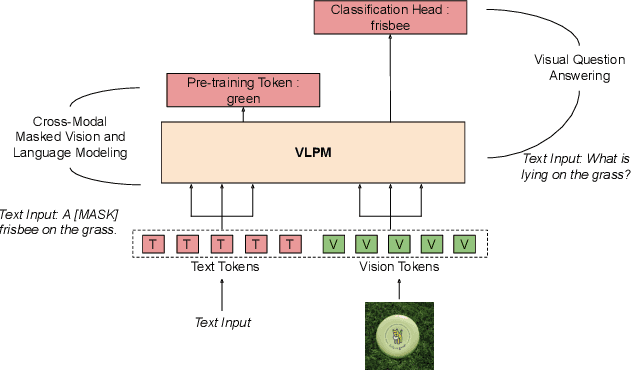
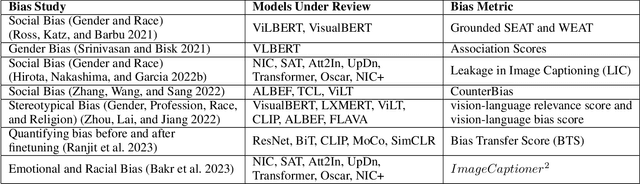
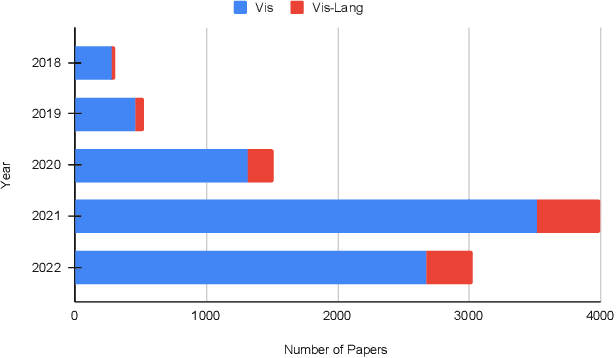
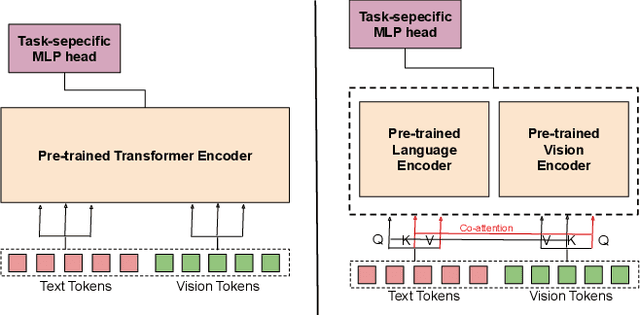
Recently, transformers have become incredibly popular in computer vision and vision-language tasks. This notable rise in their usage can be primarily attributed to the capabilities offered by attention mechanisms and the outstanding ability of transformers to adapt and apply themselves to a variety of tasks and domains. Their versatility and state-of-the-art performance have established them as indispensable tools for a wide array of applications. However, in the constantly changing landscape of machine learning, the assurance of the trustworthiness of transformers holds utmost importance. This paper conducts a thorough examination of vision-language transformers, employing three fundamental principles of responsible AI: Bias, Robustness, and Interpretability. The primary objective of this paper is to delve into the intricacies and complexities associated with the practical use of transformers, with the overarching goal of advancing our comprehension of how to enhance their reliability and accountability.
On Responsible Machine Learning Datasets with Fairness, Privacy, and Regulatory Norms
Oct 31, 2023



Artificial Intelligence (AI) has made its way into various scientific fields, providing astonishing improvements over existing algorithms for a wide variety of tasks. In recent years, there have been severe concerns over the trustworthiness of AI technologies. The scientific community has focused on the development of trustworthy AI algorithms. However, machine and deep learning algorithms, popular in the AI community today, depend heavily on the data used during their development. These learning algorithms identify patterns in the data, learning the behavioral objective. Any flaws in the data have the potential to translate directly into algorithms. In this study, we discuss the importance of Responsible Machine Learning Datasets and propose a framework to evaluate the datasets through a responsible rubric. While existing work focuses on the post-hoc evaluation of algorithms for their trustworthiness, we provide a framework that considers the data component separately to understand its role in the algorithm. We discuss responsible datasets through the lens of fairness, privacy, and regulatory compliance and provide recommendations for constructing future datasets. After surveying over 100 datasets, we use 60 datasets for analysis and demonstrate that none of these datasets is immune to issues of fairness, privacy preservation, and regulatory compliance. We provide modifications to the ``datasheets for datasets" with important additions for improved dataset documentation. With governments around the world regularizing data protection laws, the method for the creation of datasets in the scientific community requires revision. We believe this study is timely and relevant in today's era of AI.
Multi-task Explainable Skin Lesion Classification
Oct 11, 2023



Skin cancer is one of the deadliest diseases and has a high mortality rate if left untreated. The diagnosis generally starts with visual screening and is followed by a biopsy or histopathological examination. Early detection can aid in lowering mortality rates. Visual screening can be limited by the experience of the doctor. Due to the long tail distribution of dermatological datasets and significant intra-variability between classes, automatic classification utilizing computer-aided methods becomes challenging. In this work, we propose a multitask few-shot-based approach for skin lesions that generalizes well with few labelled data to address the small sample space challenge. The proposed approach comprises a fusion of a segmentation network that acts as an attention module and classification network. The output of the segmentation network helps to focus on the most discriminatory features while making a decision by the classification network. To further enhance the classification performance, we have combined segmentation and classification loss in a weighted manner. We have also included the visualization results that explain the decisions made by the algorithm. Three dermatological datasets are used to evaluate the proposed method thoroughly. We also conducted cross-database experiments to ensure that the proposed approach is generalizable across similar datasets. Experimental results demonstrate the efficacy of the proposed work.