 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenefits of depth in neural networks
May 27, 2016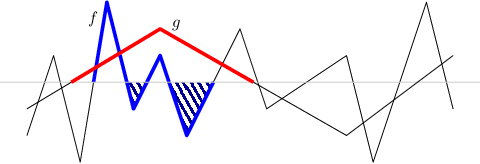
For any positive integer $k$, there exist neural networks with $\Theta(k^3)$ layers, $\Theta(1)$ nodes per layer, and $\Theta(1)$ distinct parameters which can not be approximated by networks with $\mathcal{O}(k)$ layers unless they are exponentially large --- they must possess $\Omega(2^k)$ nodes. This result is proved here for a class of nodes termed "semi-algebraic gates" which includes the common choices of ReLU, maximum, indicator, and piecewise polynomial functions, therefore establishing benefits of depth against not just standard networks with ReLU gates, but also convolutional networks with ReLU and maximization gates, sum-product networks, and boosted decision trees (in this last case with a stronger separation: $\Omega(2^{k^3})$ total tree nodes are required).
Representation Benefits of Deep Feedforward Networks
Sep 29, 2015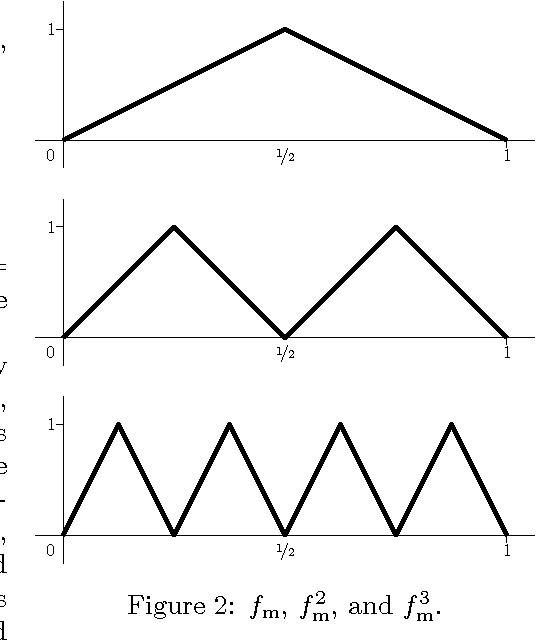
This note provides a family of classification problems, indexed by a positive integer $k$, where all shallow networks with fewer than exponentially (in $k$) many nodes exhibit error at least $1/6$, whereas a deep network with 2 nodes in each of $2k$ layers achieves zero error, as does a recurrent network with 3 distinct nodes iterated $k$ times. The proof is elementary, and the networks are standard feedforward networks with ReLU (Rectified Linear Unit) nonlinearities.
Convex Risk Minimization and Conditional Probability Estimation
Jun 15, 2015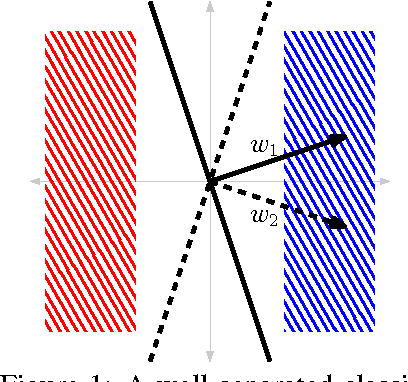
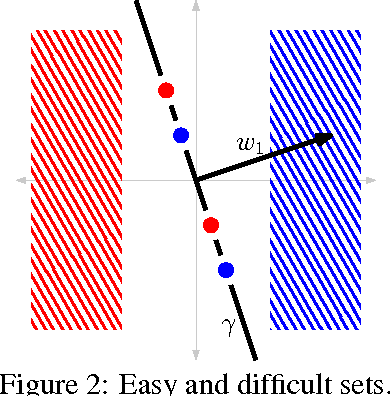
This paper proves, in very general settings, that convex risk minimization is a procedure to select a unique conditional probability model determined by the classification problem. Unlike most previous work, we give results that are general enough to include cases in which no minimum exists, as occurs typically, for instance, with standard boosting algorithms. Concretely, we first show that any sequence of predictors minimizing convex risk over the source distribution will converge to this unique model when the class of predictors is linear (but potentially of infinite dimension). Secondly, we show the same result holds for \emph{empirical} risk minimization whenever this class of predictors is finite dimensional, where the essential technical contribution is a norm-free generalization bound.
Tensor decompositions for learning latent variable models
Nov 13, 2014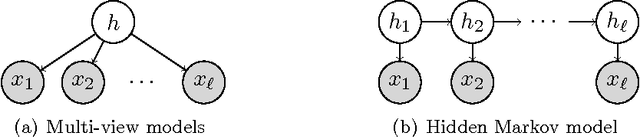
This work considers a computationally and statistically efficient parameter estimation method for a wide class of latent variable models---including Gaussian mixture models, hidden Markov models, and latent Dirichlet allocation---which exploits a certain tensor structure in their low-order observable moments (typically, of second- and third-order). Specifically, parameter estimation is reduced to the problem of extracting a certain (orthogonal) decomposition of a symmetric tensor derived from the moments; this decomposition can be viewed as a natural generalization of the singular value decomposition for matrices. Although tensor decompositions are generally intractable to compute, the decomposition of these specially structured tensors can be efficiently obtained by a variety of approaches, including power iterations and maximization approaches (similar to the case of matrices). A detailed analysis of a robust tensor power method is provided, establishing an analogue of Wedin's perturbation theorem for the singular vectors of matrices. This implies a robust and computationally tractable estimation approach for several popular latent variable models.
Scalable Nonlinear Learning with Adaptive Polynomial Expansions
Oct 02, 2014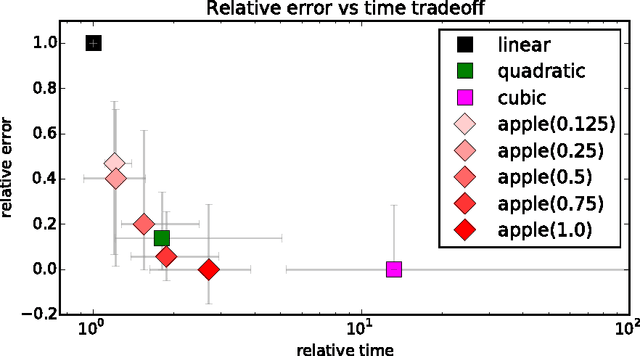

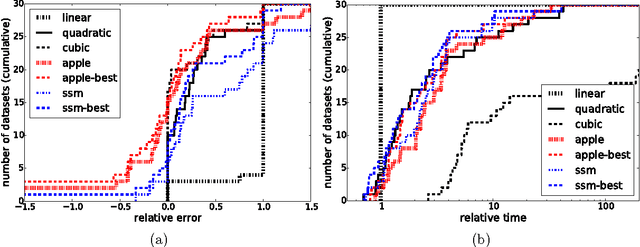
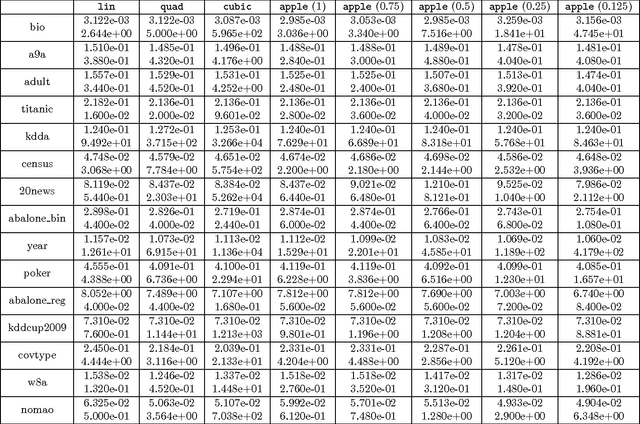
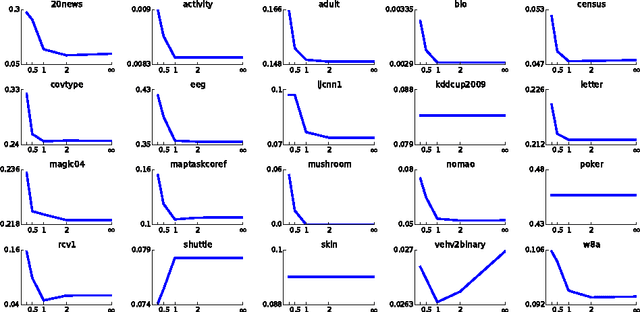
Can we effectively learn a nonlinear representation in time comparable to linear learning? We describe a new algorithm that explicitly and adaptively expands higher-order interaction features over base linear representations. The algorithm is designed for extreme computational efficiency, and an extensive experimental study shows that its computation/prediction tradeoff ability compares very favorably against strong baselines.
Moment-based Uniform Deviation Bounds for $k$-means and Friends
Nov 08, 2013Suppose $k$ centers are fit to $m$ points by heuristically minimizing the $k$-means cost; what is the corresponding fit over the source distribution? This question is resolved here for distributions with $p\geq 4$ bounded moments; in particular, the difference between the sample cost and distribution cost decays with $m$ and $p$ as $m^{\min\{-1/4, -1/2+2/p\}}$. The essential technical contribution is a mechanism to uniformly control deviations in the face of unbounded parameter sets, cost functions, and source distributions. To further demonstrate this mechanism, a soft clustering variant of $k$-means cost is also considered, namely the log likelihood of a Gaussian mixture, subject to the constraint that all covariance matrices have bounded spectrum. Lastly, a rate with refined constants is provided for $k$-means instances possessing some cluster structure.
Boosting with the Logistic Loss is Consistent
May 13, 2013This manuscript provides optimization guarantees, generalization bounds, and statistical consistency results for AdaBoost variants which replace the exponential loss with the logistic and similar losses (specifically, twice differentiable convex losses which are Lipschitz and tend to zero on one side). The heart of the analysis is to show that, in lieu of explicit regularization and constraints, the structure of the problem is fairly rigidly controlled by the source distribution itself. The first control of this type is in the separable case, where a distribution-dependent relaxed weak learning rate induces speedy convergence with high probability over any sample. Otherwise, in the nonseparable case, the convex surrogate risk itself exhibits distribution-dependent levels of curvature, and consequently the algorithm's output has small norm with high probability.
Margins, Shrinkage, and Boosting
Mar 18, 2013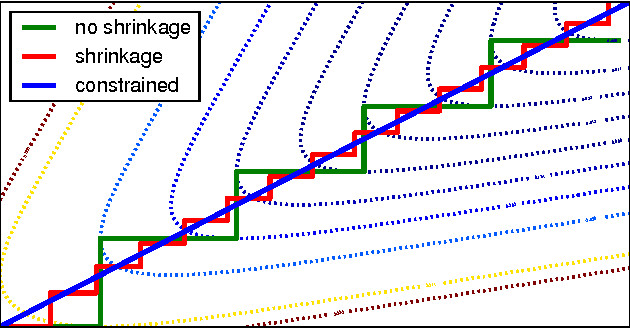
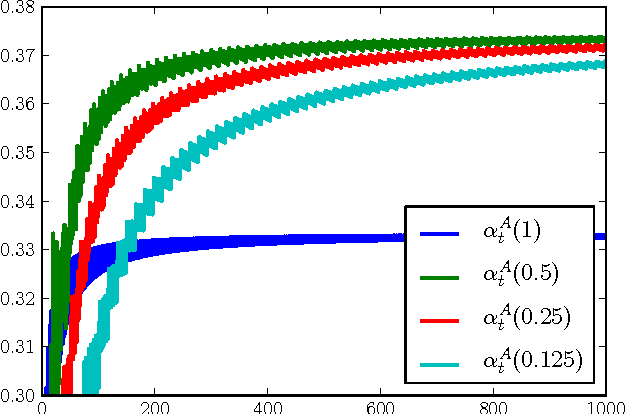
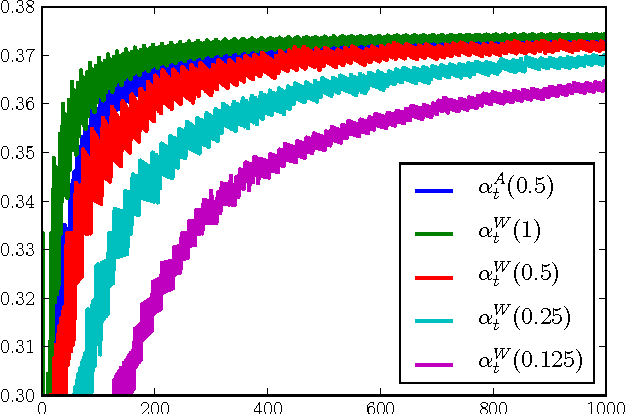
This manuscript shows that AdaBoost and its immediate variants can produce approximate maximum margin classifiers simply by scaling step size choices with a fixed small constant. In this way, when the unscaled step size is an optimal choice, these results provide guarantees for Friedman's empirically successful "shrinkage" procedure for gradient boosting (Friedman, 2000). Guarantees are also provided for a variety of other step sizes, affirming the intuition that increasingly regularized line searches provide improved margin guarantees. The results hold for the exponential loss and similar losses, most notably the logistic loss.
Dirichlet draws are sparse with high probability
Jan 21, 2013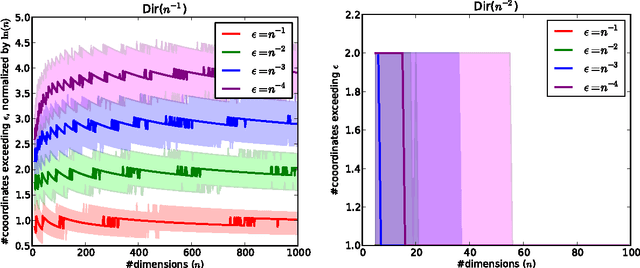
This note provides an elementary proof of the folklore fact that draws from a Dirichlet distribution (with parameters less than 1) are typically sparse (most coordinates are small).
Agglomerative Bregman Clustering
Jun 27, 2012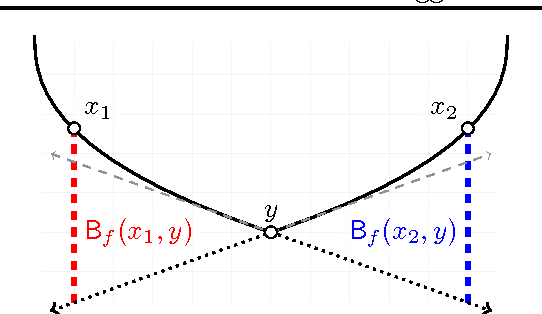
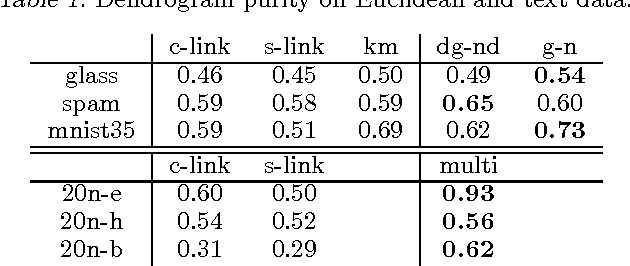
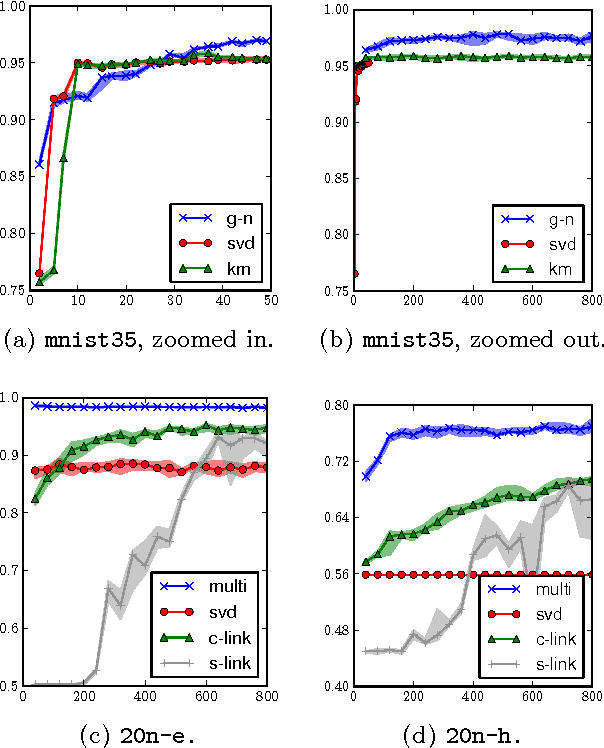
This manuscript develops the theory of agglomerative clustering with Bregman divergences. Geometric smoothing techniques are developed to deal with degenerate clusters. To allow for cluster models based on exponential families with overcomplete representations, Bregman divergences are developed for nondifferentiable convex functions.