 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping fNIRS Signals to Agent Performance: Toward Reinforcement Learning from Neural Feedback
Nov 17, 2025Reinforcement Learning from Human Feedback (RLHF) is a methodology that aligns agent behavior with human preferences by integrating human feedback into the agent's training process. We introduce a possible framework that employs passive Brain-Computer Interfaces (BCI) to guide agent training from implicit neural signals. We present and release a novel dataset of functional near-infrared spectroscopy (fNIRS) recordings collected from 25 human participants across three domains: a Pick-and-Place Robot, Lunar Lander, and Flappy Bird. We train classifiers to predict levels of agent performance (optimal, sub-optimal, or worst-case) from windows of preprocessed fNIRS feature vectors, achieving an average F1 score of 67% for binary classification and 46% for multi-class models averaged across conditions and domains. We also train regressors to predict the degree of deviation between an agent's chosen action and a set of near-optimal policies, providing a continuous measure of performance. We evaluate cross-subject generalization and demonstrate that fine-tuning pre-trained models with a small sample of subject-specific data increases average F1 scores by 17% and 41% for binary and multi-class models, respectively. Our work demonstrates that mapping implicit fNIRS signals to agent performance is feasible and can be improved, laying the foundation for future brain-driven RLHF systems.
Mapping Neural Signals to Agent Performance, A Step Towards Reinforcement Learning from Neural Feedback
Jun 14, 2025Implicit Human-in-the-Loop Reinforcement Learning (HITL-RL) is a methodology that integrates passive human feedback into autonomous agent training while minimizing human workload. However, existing methods often rely on active instruction, requiring participants to teach an agent through unnatural expression or gesture. We introduce NEURO-LOOP, an implicit feedback framework that utilizes the intrinsic human reward system to drive human-agent interaction. This work demonstrates the feasibility of a critical first step in the NEURO-LOOP framework: mapping brain signals to agent performance. Using functional near-infrared spectroscopy (fNIRS), we design a dataset to enable future research using passive Brain-Computer Interfaces for Human-in-the-Loop Reinforcement Learning. Participants are instructed to observe or guide a reinforcement learning agent in its environment while signals from the prefrontal cortex are collected. We conclude that a relationship between fNIRS data and agent performance exists using classical machine learning techniques. Finally, we highlight the potential that neural interfaces may offer to future applications of human-agent interaction, assistive AI, and adaptive autonomous systems.
Maximizing Model Generalization for Manufacturing with Self-Supervised Learning and Federated Learning
Apr 27, 2023Deep Learning (DL) can diagnose faults and assess machine health from raw condition monitoring data without manually designed statistical features. However, practical manufacturing applications remain extremely difficult for existing DL methods. Machine data is often unlabeled and from very few health conditions (e.g., only normal operating data). Furthermore, models often encounter shifts in domain as process parameters change and new categories of faults emerge. Traditional supervised learning may struggle to learn compact, discriminative representations that generalize to these unseen target domains since it depends on having plentiful classes to partition the feature space with decision boundaries. Transfer Learning (TL) with domain adaptation attempts to adapt these models to unlabeled target domains but assumes similar underlying structure that may not be present if new faults emerge. This study proposes focusing on maximizing the feature generality on the source domain and applying TL via weight transfer to copy the model to the target domain. Specifically, Self-Supervised Learning (SSL) with Barlow Twins may produce more discriminative features for monitoring health condition than supervised learning by focusing on semantic properties of the data. Furthermore, Federated Learning (FL) for distributed training may also improve generalization by efficiently expanding the effective size and diversity of training data by sharing information across multiple client machines. Results show that Barlow Twins outperforms supervised learning in an unlabeled target domain with emerging motor faults when the source training data contains very few distinct categories. Incorporating FL may also provide a slight advantage by diffusing knowledge of health conditions between machines.
Modeling Order in Neural Word Embeddings at Scale
Jun 11, 2015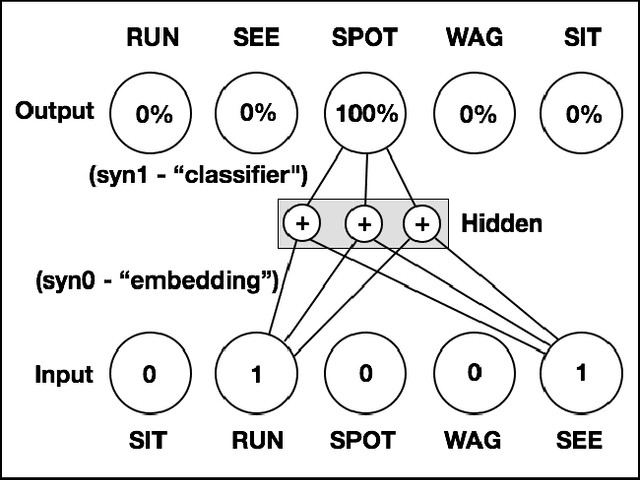
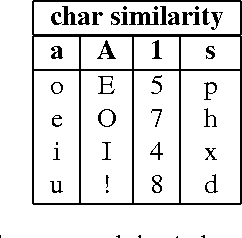
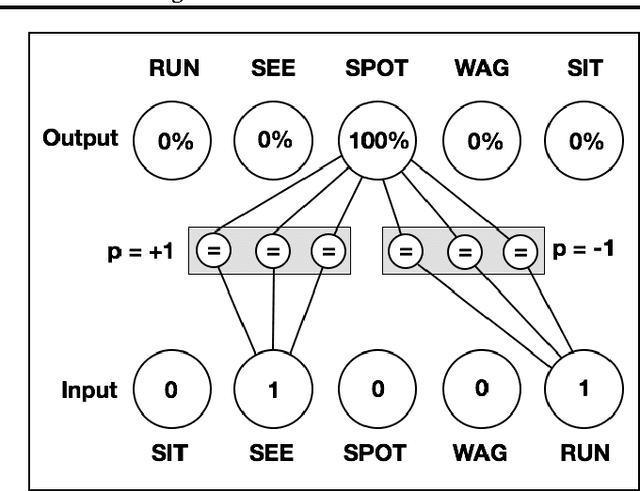
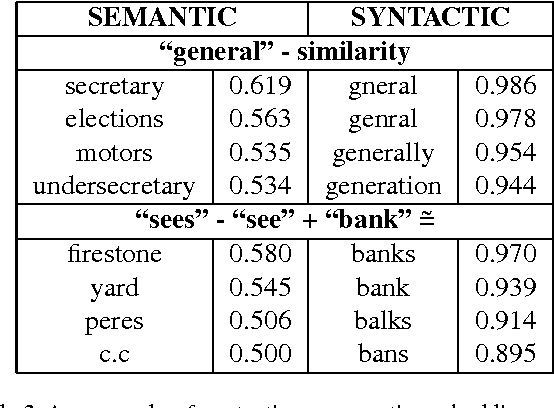
Natural Language Processing (NLP) systems commonly leverage bag-of-words co-occurrence techniques to capture semantic and syntactic word relationships. The resulting word-level distributed representations often ignore morphological information, though character-level embeddings have proven valuable to NLP tasks. We propose a new neural language model incorporating both word order and character order in its embedding. The model produces several vector spaces with meaningful substructure, as evidenced by its performance of 85.8% on a recent word-analogy task, exceeding best published syntactic word-analogy scores by a 58% error margin. Furthermore, the model includes several parallel training methods, most notably allowing a skip-gram network with 160 billion parameters to be trained overnight on 3 multi-core CPUs, 14x larger than the previous largest neural network.