 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural SQL: Making SQL Easier to Infer from Natural Language Specifications
Sep 11, 2021



Addressing the mismatch between natural language descriptions and the corresponding SQL queries is a key challenge for text-to-SQL translation. To bridge this gap, we propose an SQL intermediate representation (IR) called Natural SQL (NatSQL). Specifically, NatSQL preserves the core functionalities of SQL, while it simplifies the queries as follows: (1) dispensing with operators and keywords such as GROUP BY, HAVING, FROM, JOIN ON, which are usually hard to find counterparts for in the text descriptions; (2) removing the need for nested subqueries and set operators; and (3) making schema linking easier by reducing the required number of schema items. On Spider, a challenging text-to-SQL benchmark that contains complex and nested SQL queries, we demonstrate that NatSQL outperforms other IRs, and significantly improves the performance of several previous SOTA models. Furthermore, for existing models that do not support executable SQL generation, NatSQL easily enables them to generate executable SQL queries, and achieves the new state-of-the-art execution accuracy.
A Longitudinal Multi-modal Dataset for Dementia Monitoring and Diagnosis
Sep 03, 2021
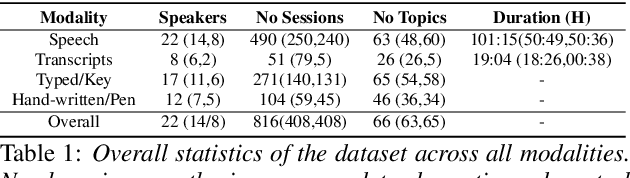
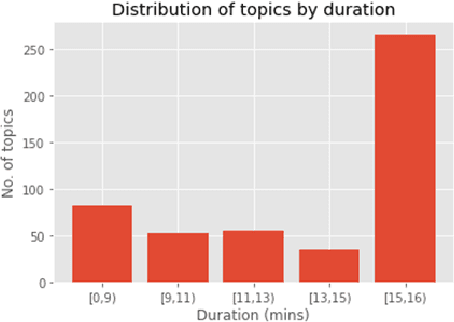
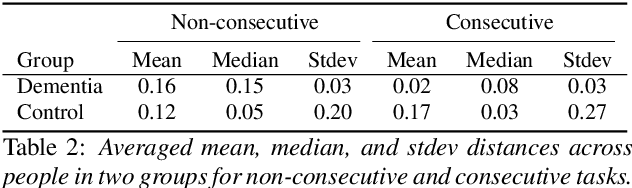
Dementia is a family of neurogenerative conditions affecting memory and cognition in an increasing number of individuals in our globally aging population. Automated analysis of language, speech and paralinguistic indicators have been gaining popularity as potential indicators of cognitive decline. Here we propose a novel longitudinal multi-modal dataset collected from people with mild dementia and age matched controls over a period of several months in a natural setting. The multi-modal data consists of spoken conversations, a subset of which are transcribed, as well as typed and written thoughts and associated extra-linguistic information such as pen strokes and keystrokes. We describe the dataset in detail and proceed to focus on a task using the speech modality. The latter involves distinguishing controls from people with dementia by exploiting the longitudinal nature of the data. Our experiments showed significant differences in how the speech varied from session to session in the control and dementia groups.
Evaluation of contextual embeddings on less-resourced languages
Jul 22, 2021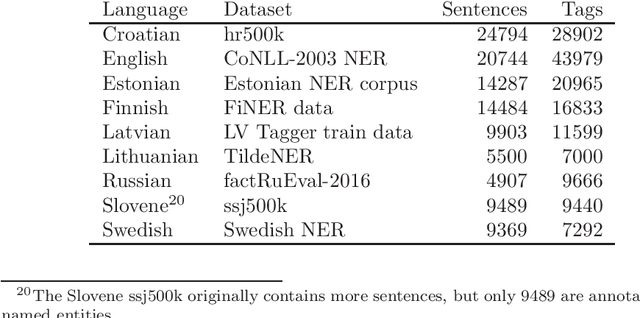

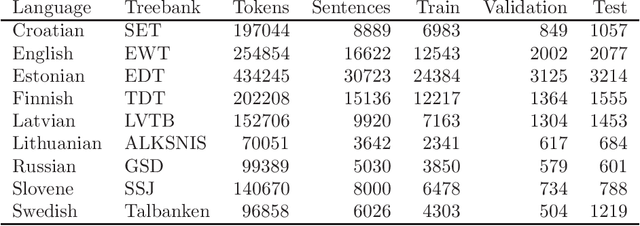
The current dominance of deep neural networks in natural language processing is based on contextual embeddings such as ELMo, BERT, and BERT derivatives. Most existing work focuses on English; in contrast, we present here the first multilingual empirical comparison of two ELMo and several monolingual and multilingual BERT models using 14 tasks in nine languages. In monolingual settings, our analysis shows that monolingual BERT models generally dominate, with a few exceptions such as the dependency parsing task, where they are not competitive with ELMo models trained on large corpora. In cross-lingual settings, BERT models trained on only a few languages mostly do best, closely followed by massively multilingual BERT models.
Alzheimer's Dementia Recognition Using Acoustic, Lexical, Disfluency and Speech Pause Features Robust to Noisy Inputs
Jun 29, 2021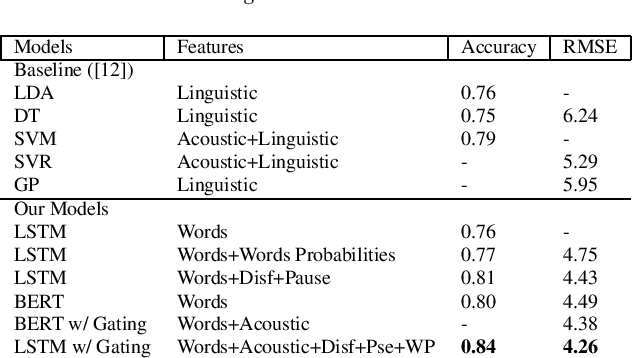

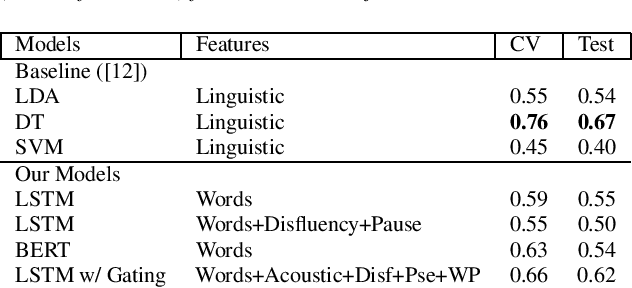
We present two multimodal fusion-based deep learning models that consume ASR transcribed speech and acoustic data simultaneously to classify whether a speaker in a structured diagnostic task has Alzheimer's Disease and to what degree, evaluating the ADReSSo challenge 2021 data. Our best model, a BiLSTM with highway layers using words, word probabilities, disfluency features, pause information, and a variety of acoustic features, achieves an accuracy of 84% and RSME error prediction of 4.26 on MMSE cognitive scores. While predicting cognitive decline is more challenging, our models show improvement using the multimodal approach and word probabilities, disfluency and pause information over word-only models. We show considerable gains for AD classification using multimodal fusion and gating, which can effectively deal with noisy inputs from acoustic features and ASR hypotheses.
Towards Robustness of Text-to-SQL Models against Synonym Substitution
Jun 19, 2021

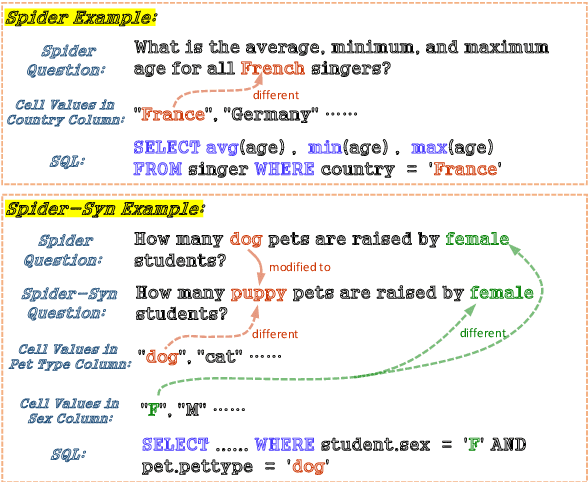
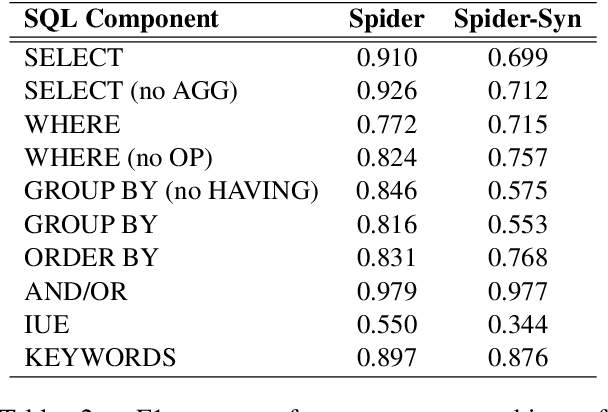
Recently, there has been significant progress in studying neural networks to translate text descriptions into SQL queries. Despite achieving good performance on some public benchmarks, existing text-to-SQL models typically rely on the lexical matching between words in natural language (NL) questions and tokens in table schemas, which may render the models vulnerable to attacks that break the schema linking mechanism. In this work, we investigate the robustness of text-to-SQL models to synonym substitution. In particular, we introduce Spider-Syn, a human-curated dataset based on the Spider benchmark for text-to-SQL translation. NL questions in Spider-Syn are modified from Spider, by replacing their schema-related words with manually selected synonyms that reflect real-world question paraphrases. We observe that the accuracy dramatically drops by eliminating such explicit correspondence between NL questions and table schemas, even if the synonyms are not adversarially selected to conduct worst-case adversarial attacks. Finally, we present two categories of approaches to improve the model robustness. The first category of approaches utilizes additional synonym annotations for table schemas by modifying the model input, while the second category is based on adversarial training. We demonstrate that both categories of approaches significantly outperform their counterparts without the defense, and the first category of approaches are more effective.
Multi-modal fusion with gating using audio, lexical and disfluency features for Alzheimer's Dementia recognition from spontaneous speech
Jun 17, 2021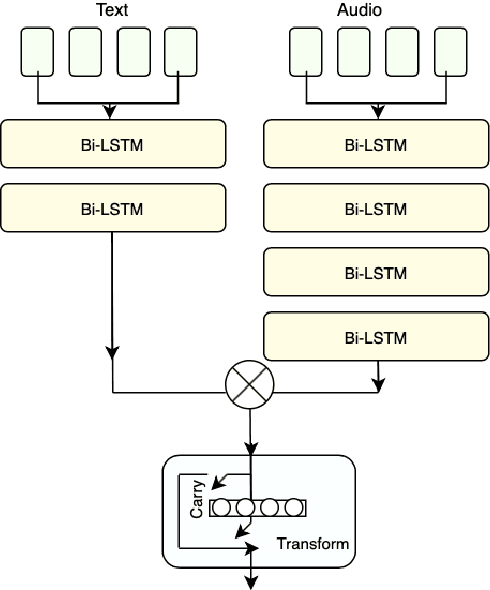

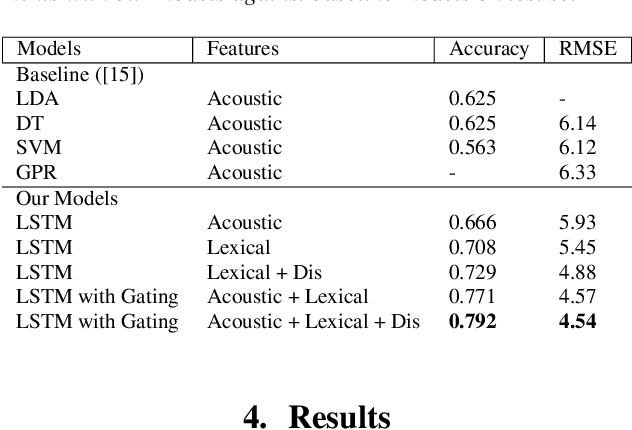
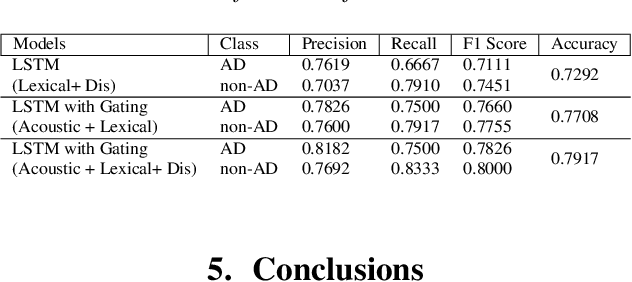
This paper is a submission to the Alzheimer's Dementia Recognition through Spontaneous Speech (ADReSS) challenge, which aims to develop methods that can assist in the automated prediction of severity of Alzheimer's Disease from speech data. We focus on acoustic and natural language features for cognitive impairment detection in spontaneous speech in the context of Alzheimer's Disease Diagnosis and the mini-mental state examination (MMSE) score prediction. We proposed a model that obtains unimodal decisions from different LSTMs, one for each modality of text and audio, and then combines them using a gating mechanism for the final prediction. We focused on sequential modelling of text and audio and investigated whether the disfluencies present in individuals' speech relate to the extent of their cognitive impairment. Our results show that the proposed classification and regression schemes obtain very promising results on both development and test sets. This suggests Alzheimer's Disease can be detected successfully with sequence modeling of the speech data of medical sessions.
Temporal Mental Health Dynamics on Social Media
Sep 02, 2020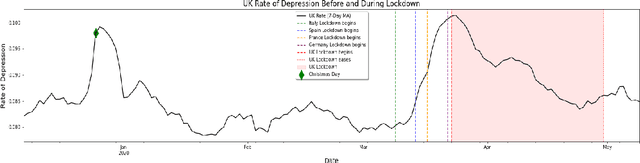
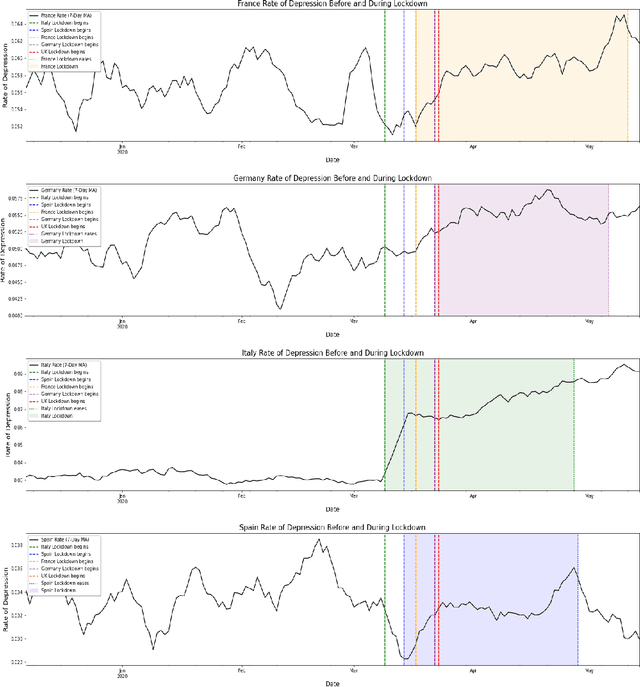

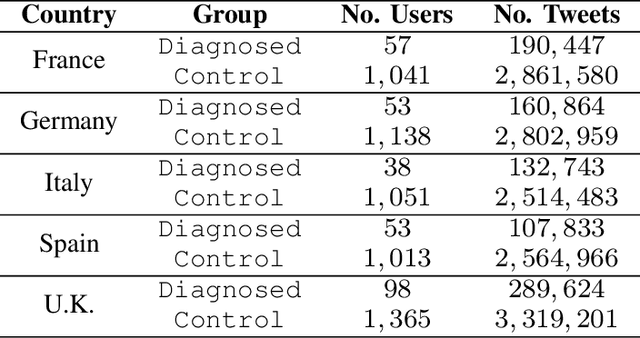
We describe a set of experiments for building a temporal mental health dynamics system. We utilise a pre-existing methodology for distant-supervision of mental health data mining from social media platforms and deploy the system during the global COVID-19 pandemic as a case study. Despite the challenging nature of the task, we produce encouraging results, both explicit to the global pandemic and implicit to a global phenomenon, Christmas Depression, supported by the literature. We propose a methodology for providing insight into temporal mental health dynamics to be utilised for strategic decision-making.
How Furiously Can Colourless Green Ideas Sleep? Sentence Acceptability in Context
Apr 02, 2020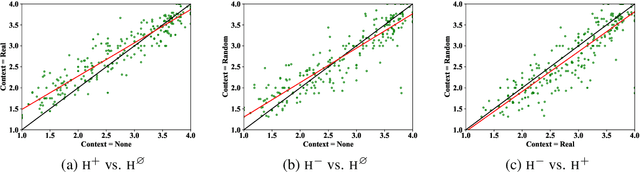

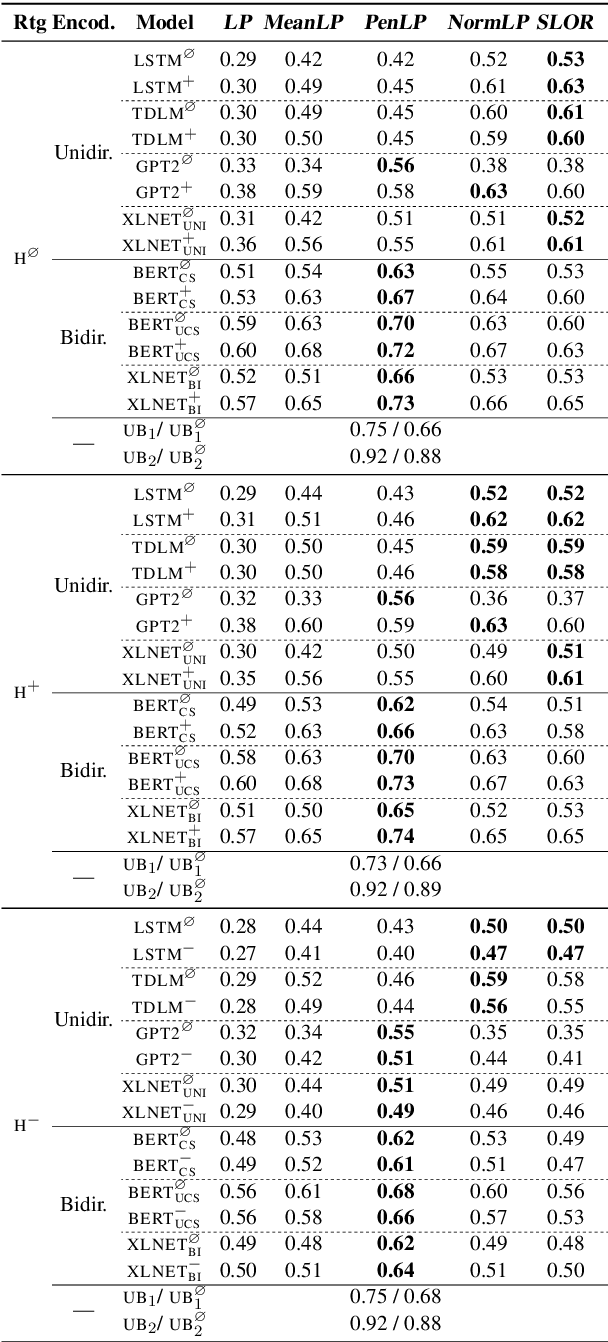
We study the influence of context on sentence acceptability. First we compare the acceptability ratings of sentences judged in isolation, with a relevant context, and with an irrelevant context. Our results show that context induces a cognitive load for humans, which compresses the distribution of ratings. Moreover, in relevant contexts we observe a discourse coherence effect which uniformly raises acceptability. Next, we test unidirectional and bidirectional language models in their ability to predict acceptability ratings. The bidirectional models show very promising results, with the best model achieving a new state-of-the-art for unsupervised acceptability prediction. The two sets of experiments provide insights into the cognitive aspects of sentence processing and central issues in the computational modelling of text and discourse.
CoSimLex: A Resource for Evaluating Graded Word Similarity in Context
Dec 18, 2019
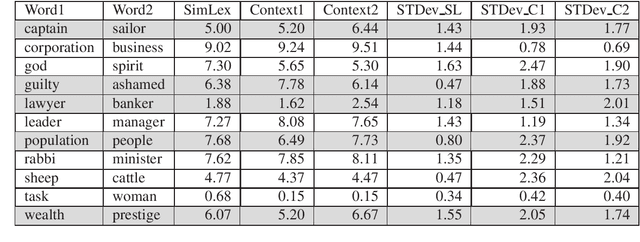

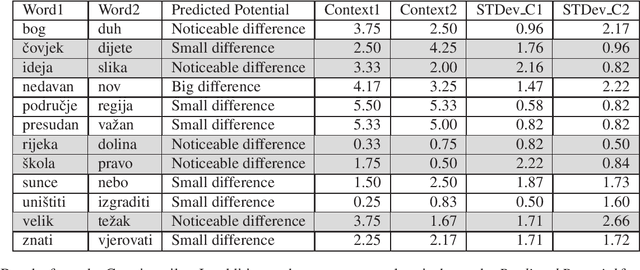
State of the art natural language processing tools are built on context-dependent word embeddings, but no direct method for evaluating these representations currently exists. Standard tasks and datasets for intrinsic evaluation of embeddings are based on judgements of similarity, but ignore context; standard tasks for word sense disambiguation take account of context but do not provide continuous measures of meaning similarity. This paper describes an effort to build a new dataset, CoSimLex, intended to fill this gap. Building on the standard pairwise similarity task of SimLex-999, it provides context-dependent similarity measures; covers not only discrete differences in word sense but more subtle, graded changes in meaning; and covers not only a well-resourced language (English) but a number of less-resourced languages. We define the task and evaluation metrics, outline the dataset collection methodology, and describe the status of the dataset so far.
Exploring Semantic Incrementality with Dynamic Syntax and Vector Space Semantics
Nov 01, 2018

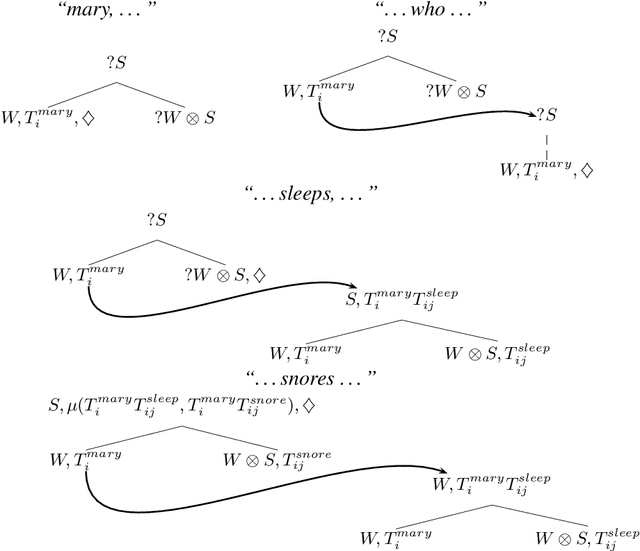
One of the fundamental requirements for models of semantic processing in dialogue is incrementality: a model must reflect how people interpret and generate language at least on a word-by-word basis, and handle phenomena such as fragments, incomplete and jointly-produced utterances. We show that the incremental word-by-word parsing process of Dynamic Syntax (DS) can be assigned a compositional distributional semantics, with the composition operator of DS corresponding to the general operation of tensor contraction from multilinear algebra. We provide abstract semantic decorations for the nodes of DS trees, in terms of vectors, tensors, and sums thereof; using the latter to model the underspecified elements crucial to assigning partial representations during incremental processing. As a working example, we give an instantiation of this theory using plausibility tensors of compositional distributional semantics, and show how our framework can incrementally assign a semantic plausibility measure as it parses phrases and sentences.