 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Correlation Space for Time Series
May 15, 2018
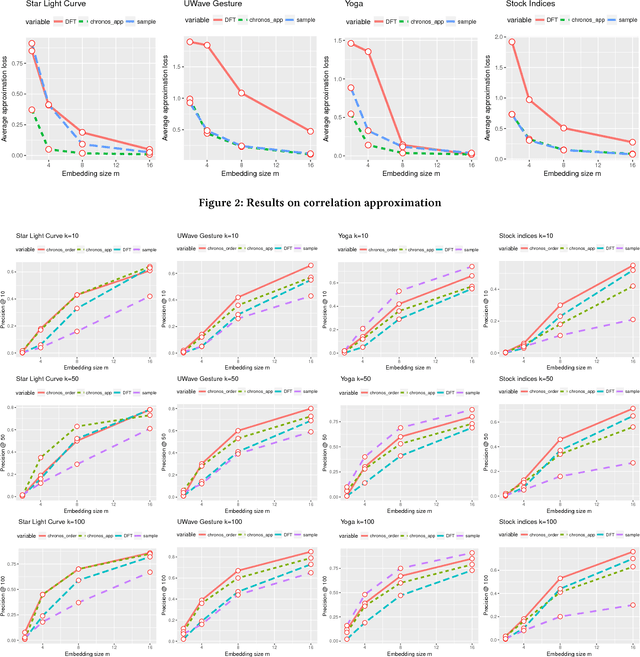
We propose an approximation algorithm for efficient correlation search in time series data. In our method, we use Fourier transform and neural network to embed time series into a low-dimensional Euclidean space. The given space is learned such that time series correlation can be effectively approximated from Euclidean distance between corresponding embedded vectors. Therefore, search for correlated time series can be done using an index in the embedding space for efficient nearest neighbor search. Our theoretical analysis illustrates that our method's accuracy can be guaranteed under certain regularity conditions. We further conduct experiments on real-world datasets and the results show that our method indeed outperforms the baseline solution. In particular, for approximation of correlation, our method reduces the approximation loss by a half in most test cases compared to the baseline solution. For top-$k$ highest correlation search, our method improves the precision from 5\% to 20\% while the query time is similar to the baseline approach query time.
Non-parametric estimation of Jensen-Shannon Divergence in Generative Adversarial Network training
Oct 15, 2017


Generative Adversarial Networks (GANs) have become a widely popular framework for generative modelling of high-dimensional datasets. However their training is well-known to be difficult. This work presents a rigorous statistical analysis of GANs providing straight-forward explanations for common training pathologies such as vanishing gradients. Furthermore, it proposes a new training objective, Kernel GANs, and demonstrates its practical effectiveness on large-scale real-world data sets. A key element in the analysis is the distinction between training with respect to the (unknown) data distribution, and its empirical counterpart. To overcome issues in GAN training, we pursue the idea of smoothing the Jensen-Shannon Divergence (JSD) by incorporating noise in the input distributions of the discriminator. As we show, this effectively leads to an empirical version of the JSD in which the true and the generator densities are replaced by kernel density estimates, which leads to Kernel GANs.
One button machine for automating feature engineering in relational databases
Jun 01, 2017
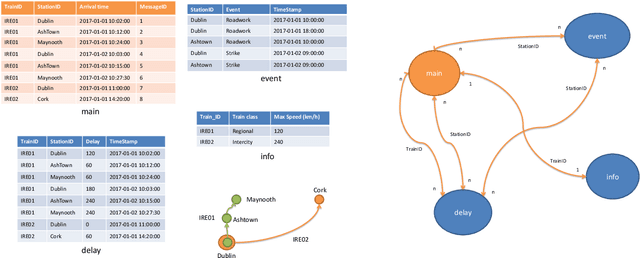
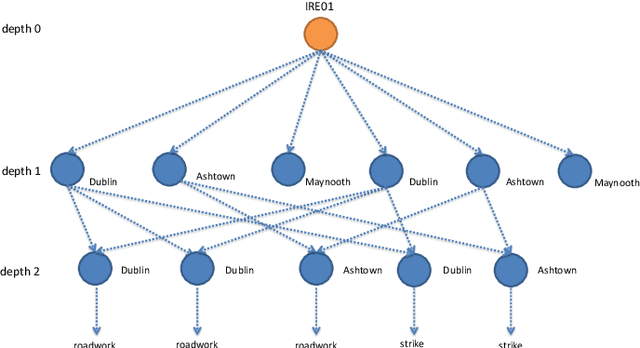
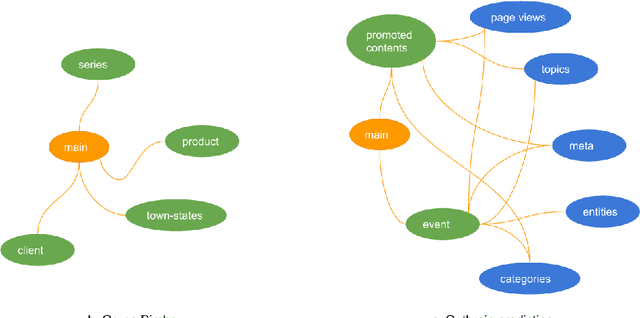
Feature engineering is one of the most important and time consuming tasks in predictive analytics projects. It involves understanding domain knowledge and data exploration to discover relevant hand-crafted features from raw data. In this paper, we introduce a system called One Button Machine, or OneBM for short, which automates feature discovery in relational databases. OneBM automatically performs a key activity of data scientists, namely, joining of database tables and applying advanced data transformations to extract useful features from data. We validated OneBM in Kaggle competitions in which OneBM achieved performance as good as top 16% to 24% data scientists in three Kaggle competitions. More importantly, OneBM outperformed the state-of-the-art system in a Kaggle competition in terms of prediction accuracy and ranking on Kaggle leaderboard. The results show that OneBM can be useful for both data scientists and non-experts. It helps data scientists reduce data exploration time allowing them to try and error many ideas in short time. On the other hand, it enables non-experts, who are not familiar with data science, to quickly extract value from their data with a little effort, time and cost.
Multi-task additive models with shared transfer functions based on dictionary learning
May 19, 2015
Additive models form a widely popular class of regression models which represent the relation between covariates and response variables as the sum of low-dimensional transfer functions. Besides flexibility and accuracy, a key benefit of these models is their interpretability: the transfer functions provide visual means for inspecting the models and identifying domain-specific relations between inputs and outputs. However, in large-scale problems involving the prediction of many related tasks, learning independently additive models results in a loss of model interpretability, and can cause overfitting when training data is scarce. We introduce a novel multi-task learning approach which provides a corpus of accurate and interpretable additive models for a large number of related forecasting tasks. Our key idea is to share transfer functions across models in order to reduce the model complexity and ease the exploration of the corpus. We establish a connection with sparse dictionary learning and propose a new efficient fitting algorithm which alternates between sparse coding and transfer function updates. The former step is solved via an extension of Orthogonal Matching Pursuit, whose properties are analyzed using a novel recovery condition which extends existing results in the literature. The latter step is addressed using a traditional dictionary update rule. Experiments on real-world data demonstrate that our approach compares favorably to baseline methods while yielding an interpretable corpus of models, revealing structure among the individual tasks and being more robust when training data is scarce. Our framework therefore extends the well-known benefits of additive models to common regression settings possibly involving thousands of tasks.
Comparative Analysis of Probabilistic Models for Activity Recognition with an Instrumented Walker
Mar 15, 2012


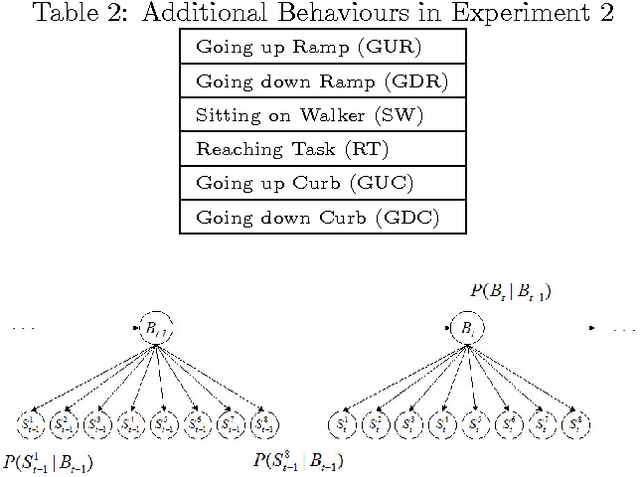
Rollating walkers are popular mobility aids used by older adults to improve balance control. There is a need to automatically recognize the activities performed by walker users to better understand activity patterns, mobility issues and the context in which falls are more likely to happen. We design and compare several techniques to recognize walker related activities. A comprehensive evaluation with control subjects and walker users from a retirement community is presented.