 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fast Training-Free Compression Framework for Vision Transformers
Mar 04, 2023Token pruning has emerged as an effective solution to speed up the inference of large Transformer models. However, prior work on accelerating Vision Transformer (ViT) models requires training from scratch or fine-tuning with additional parameters, which prevents a simple plug-and-play. To avoid high training costs during the deployment stage, we present a fast training-free compression framework enabled by (i) a dense feature extractor in the initial layers; (ii) a sharpness-minimized model which is more compressible; and (iii) a local-global token merger that can exploit spatial relationships at various contexts. We applied our framework to various ViT and DeiT models and achieved up to 2x reduction in FLOPS and 1.8x speedup in inference throughput with <1% accuracy loss, while saving two orders of magnitude shorter training times than existing approaches. Code will be available at https://github.com/johnheo/fast-compress-vit
Efficient Compilation and Mapping of Fixed Function Combinational Logic onto Digital Signal Processors Targeting Neural Network Inference and Utilizing High-level Synthesis
Jul 30, 2022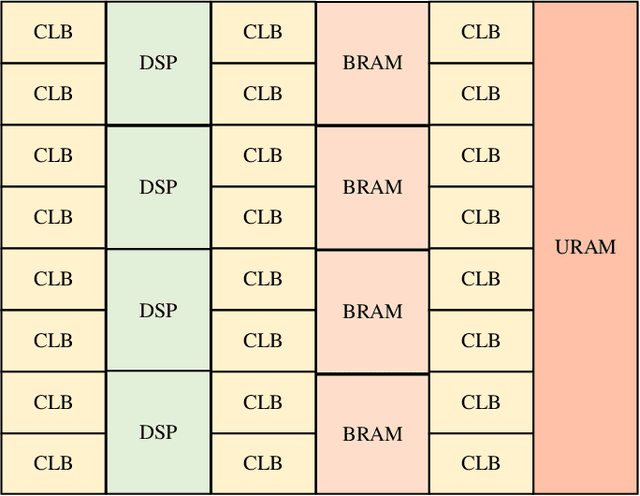
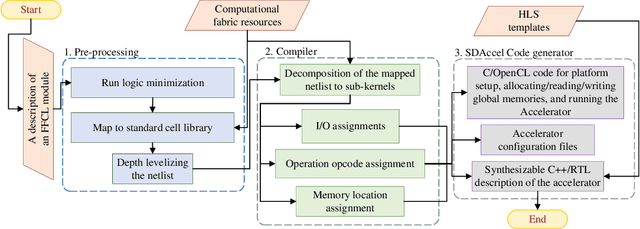
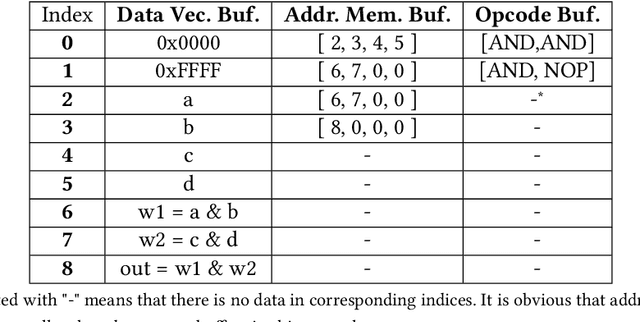
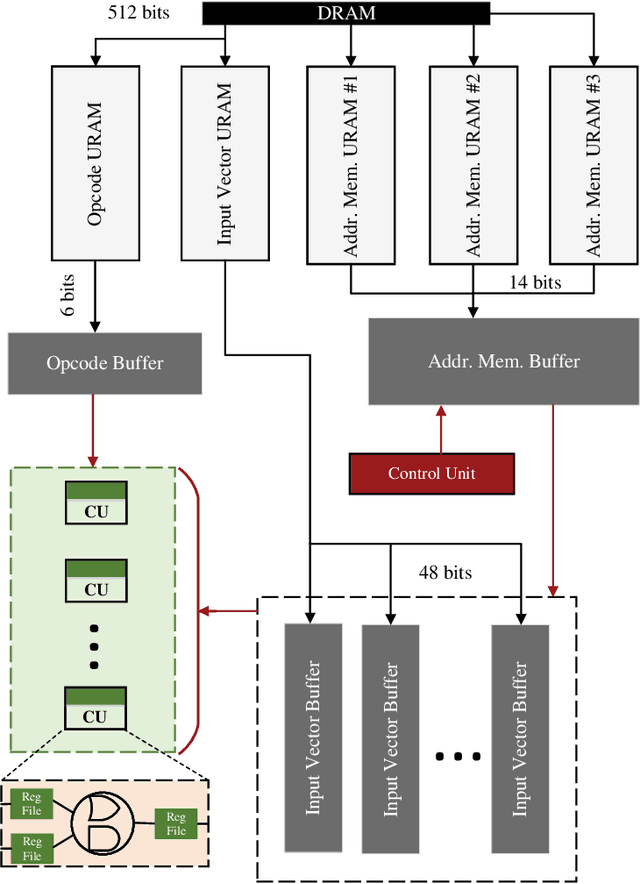
Recent efforts for improving the performance of neural network (NN) accelerators that meet today's application requirements have given rise to a new trend of logic-based NN inference relying on fixed function combinational logic. Mapping such large Boolean functions with many input variables and product terms to digital signal processors (DSPs) on Field-programmable gate arrays (FPGAs) needs a novel framework considering the structure and the reconfigurability of DSP blocks during this process. The proposed methodology in this paper maps the fixed function combinational logic blocks to a set of Boolean functions where Boolean operations corresponding to each function are mapped to DSP devices rather than look-up tables (LUTs) on the FPGAs to take advantage of the high performance, low latency, and parallelism of DSP blocks. % This paper also presents an innovative design and optimization methodology for compilation and mapping of NNs, utilizing fixed function combinational logic to DSPs on FPGAs employing high-level synthesis flow. % Our experimental evaluations across several \REVone{datasets} and selected NNs demonstrate the comparable performance of our framework in terms of the inference latency and output accuracy compared to prior art FPGA-based NN accelerators employing DSPs.
Sparse Periodic Systolic Dataflow for Lowering Latency and Power Dissipation of Convolutional Neural Network Accelerators
Jun 30, 2022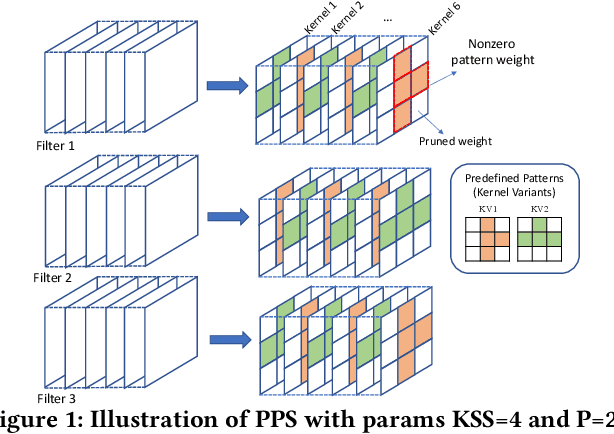
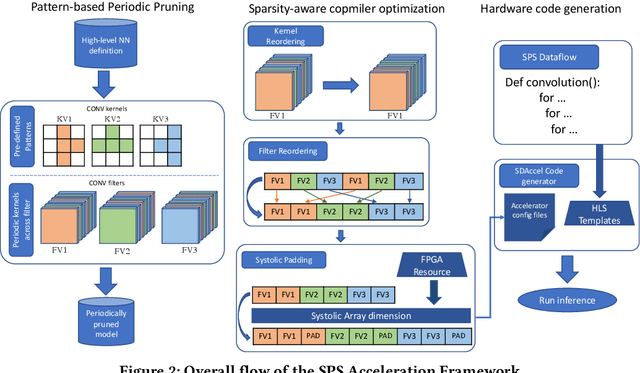
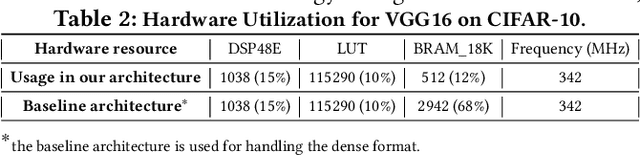
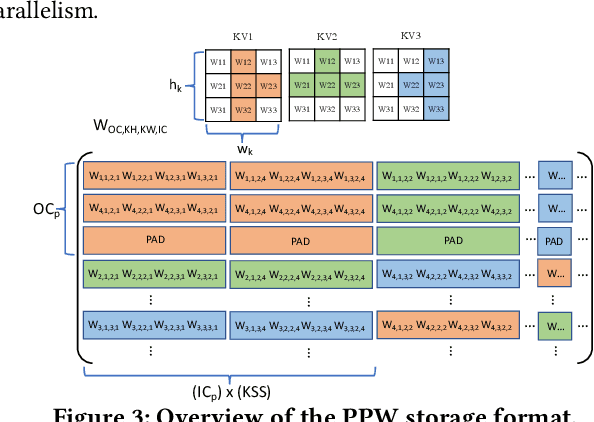
This paper introduces the sparse periodic systolic (SPS) dataflow, which advances the state-of-the-art hardware accelerator for supporting lightweight neural networks. Specifically, the SPS dataflow enables a novel hardware design approach unlocked by an emergent pruning scheme, periodic pattern-based sparsity (PPS). By exploiting the regularity of PPS, our sparsity-aware compiler optimally reorders the weights and uses a simple indexing unit in hardware to create matches between the weights and activations. Through the compiler-hardware codesign, SPS dataflow enjoys higher degrees of parallelism while being free of the high indexing overhead and without model accuracy loss. Evaluated on popular benchmarks such as VGG and ResNet, the SPS dataflow and accompanying neural network compiler outperform prior work in convolutional neural network (CNN) accelerator designs targeting FPGA devices. Against other sparsity-supporting weight storage formats, SPS results in 4.49x energy efficiency gain while lowering storage requirements by 3.67x for total weight storage (non-pruned weights plus indexing) and 22,044x for indexing memory.
A Fast and Efficient Conditional Learning for Tunable Trade-Off between Accuracy and Robustness
Mar 28, 2022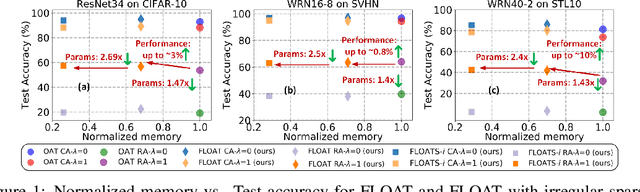

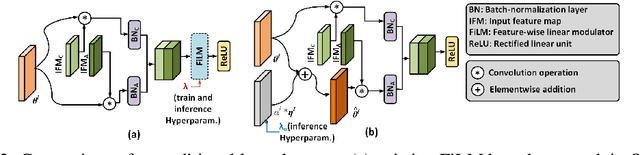
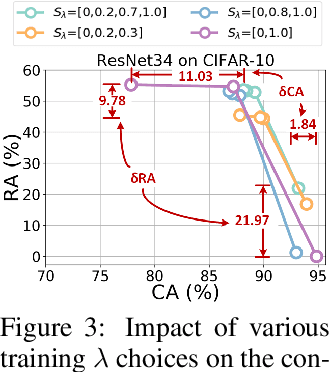
Existing models that achieve state-of-the-art (SOTA) performance on both clean and adversarially-perturbed images rely on convolution operations conditioned with feature-wise linear modulation (FiLM) layers. These layers require many new parameters and are hyperparameter sensitive. They significantly increase training time, memory cost, and potential latency which can prove costly for resource-limited or real-time applications. In this paper, we present a fast learnable once-for-all adversarial training (FLOAT) algorithm, which instead of the existing FiLM-based conditioning, presents a unique weight conditioned learning that requires no additional layer, thereby incurring no significant increase in parameter count, training time, or network latency compared to standard adversarial training. In particular, we add configurable scaled noise to the weight tensors that enables a trade-off between clean and adversarial performance. Extensive experiments show that FLOAT can yield SOTA performance improving both clean and perturbed image classification by up to ~6% and ~10%, respectively. Moreover, real hardware measurement shows that FLOAT can reduce the training time by up to 1.43x with fewer model parameters of up to 1.47x on iso-hyperparameter settings compared to the FiLM-based alternatives. Additionally, to further improve memory efficiency we introduce FLOAT sparse (FLOATS), a form of non-iterative model pruning and provide detailed empirical analysis to provide a three way accuracy-robustness-complexity trade-off for these new class of pruned conditionally trained models.
BMPQ: Bit-Gradient Sensitivity Driven Mixed-Precision Quantization of DNNs from Scratch
Dec 24, 2021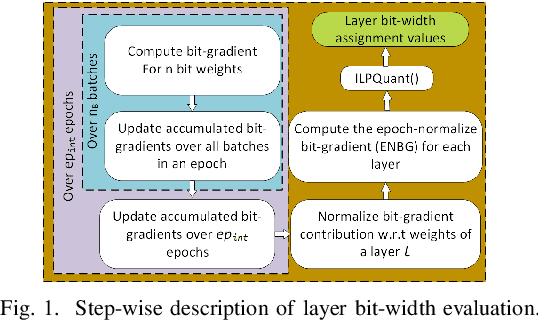
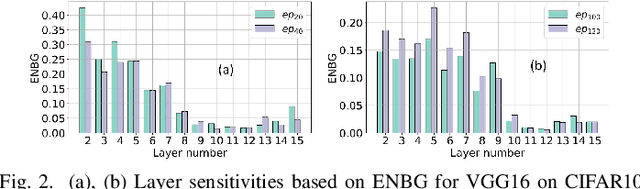
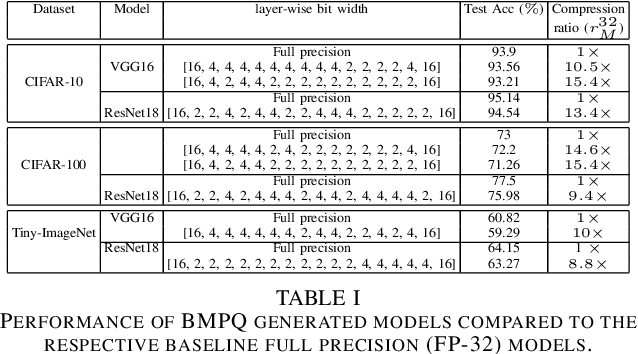
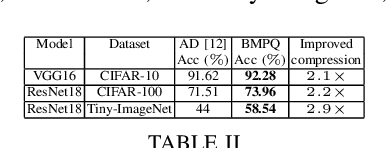
Large DNNs with mixed-precision quantization can achieve ultra-high compression while retaining high classification performance. However, because of the challenges in finding an accurate metric that can guide the optimization process, these methods either sacrifice significant performance compared to the 32-bit floating-point (FP-32) baseline or rely on a compute-expensive, iterative training policy that requires the availability of a pre-trained baseline. To address this issue, this paper presents BMPQ, a training method that uses bit gradients to analyze layer sensitivities and yield mixed-precision quantized models. BMPQ requires a single training iteration but does not need a pre-trained baseline. It uses an integer linear program (ILP) to dynamically adjust the precision of layers during training, subject to a fixed hardware budget. To evaluate the efficacy of BMPQ, we conduct extensive experiments with VGG16 and ResNet18 on CIFAR-10, CIFAR-100, and Tiny-ImageNet datasets. Compared to the baseline FP-32 models, BMPQ can yield models that have 15.4x fewer parameter bits with a negligible drop in accuracy. Compared to the SOTA "during training", mixed-precision training scheme, our models are 2.1x, 2.2x, and 2.9x smaller, on CIFAR-10, CIFAR-100, and Tiny-ImageNet, respectively, with an improved accuracy of up to 14.54%.
Towards Low-Latency Energy-Efficient Deep SNNs via Attention-Guided Compression
Jul 16, 2021
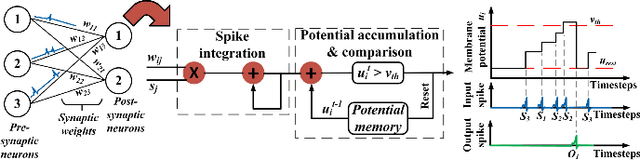
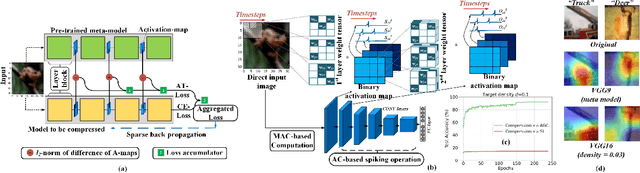
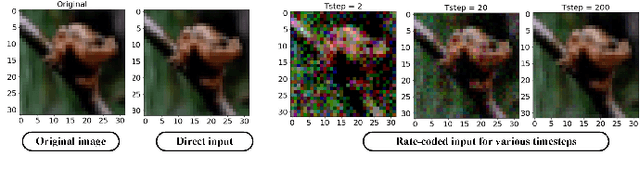
Deep spiking neural networks (SNNs) have emerged as a potential alternative to traditional deep learning frameworks, due to their promise to provide increased compute efficiency on event-driven neuromorphic hardware. However, to perform well on complex vision applications, most SNN training frameworks yield large inference latency which translates to increased spike activity and reduced energy efficiency. Hence,minimizing average spike activity while preserving accuracy indeep SNNs remains a significant challenge and opportunity.This paper presents a non-iterative SNN training technique thatachieves ultra-high compression with reduced spiking activitywhile maintaining high inference accuracy. In particular, our framework first uses the attention-maps of an un compressed meta-model to yield compressed ANNs. This step can be tuned to support both irregular and structured channel pruning to leverage computational benefits over a broad range of platforms. The framework then performs sparse-learning-based supervised SNN training using direct inputs. During the training, it jointly optimizes the SNN weight, threshold, and leak parameters to drastically minimize the number of time steps required while retaining compression. To evaluate the merits of our approach, we performed experiments with variants of VGG and ResNet, on both CIFAR-10 and CIFAR-100, and VGG16 on Tiny-ImageNet.The SNN models generated through the proposed technique yield SOTA compression ratios of up to 33.4x with no significant drops in accuracy compared to baseline unpruned counterparts. Compared to existing SNN pruning methods, we achieve up to 8.3x higher compression with improved accuracy.
NullaNet Tiny: Ultra-low-latency DNN Inference Through Fixed-function Combinational Logic
Apr 07, 2021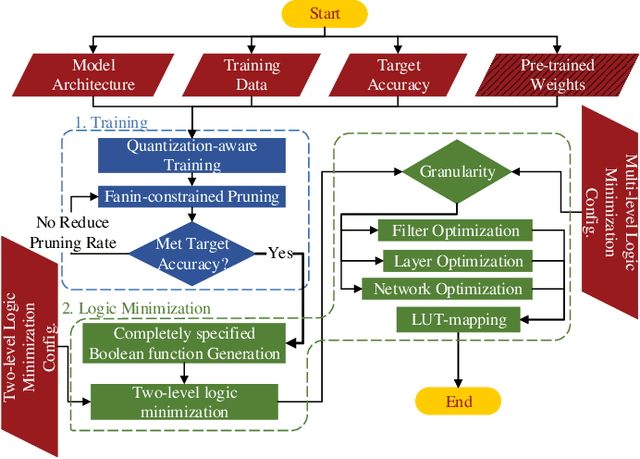
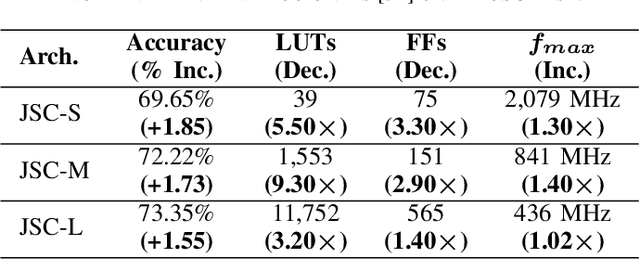
While there is a large body of research on efficient processing of deep neural networks (DNNs), ultra-low-latency realization of these models for applications with stringent, sub-microsecond latency requirements continues to be an unresolved, challenging problem. Field-programmable gate array (FPGA)-based DNN accelerators are gaining traction as a serious contender to replace graphics processing unit/central processing unit-based platforms considering their performance, flexibility, and energy efficiency. This paper presents NullaNet Tiny, an across-the-stack design and optimization framework for constructing resource and energy-efficient, ultra-low-latency FPGA-based neural network accelerators. The key idea is to replace expensive operations required to compute various filter/neuron functions in a DNN with Boolean logic expressions that are mapped to the native look-up tables (LUTs) of the FPGA device (examples of such operations are multiply-and-accumulate and batch normalization). At about the same level of classification accuracy, compared to Xilinx's LogicNets, our design achieves 2.36$\times$ lower latency and 24.42$\times$ lower LUT utilization.
A2P-MANN: Adaptive Attention Inference Hops Pruned Memory-Augmented Neural Networks
Jan 24, 2021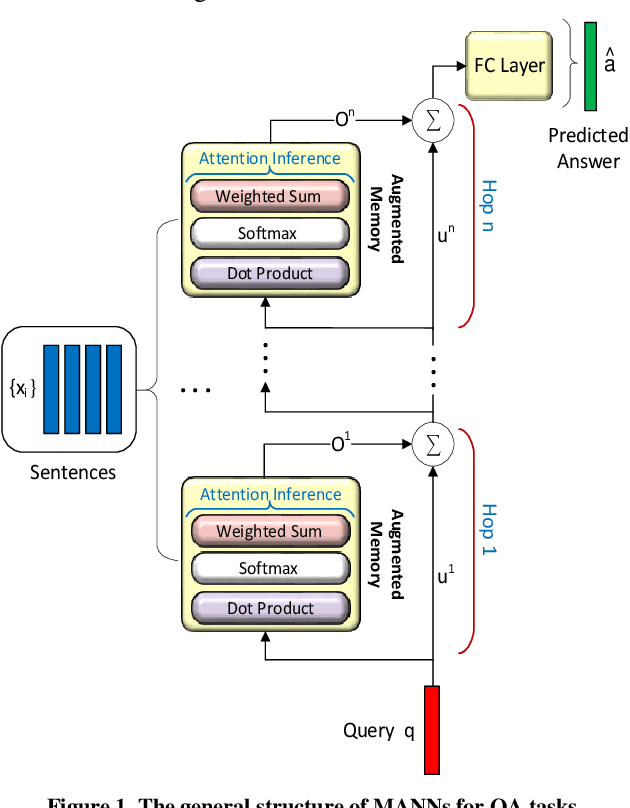
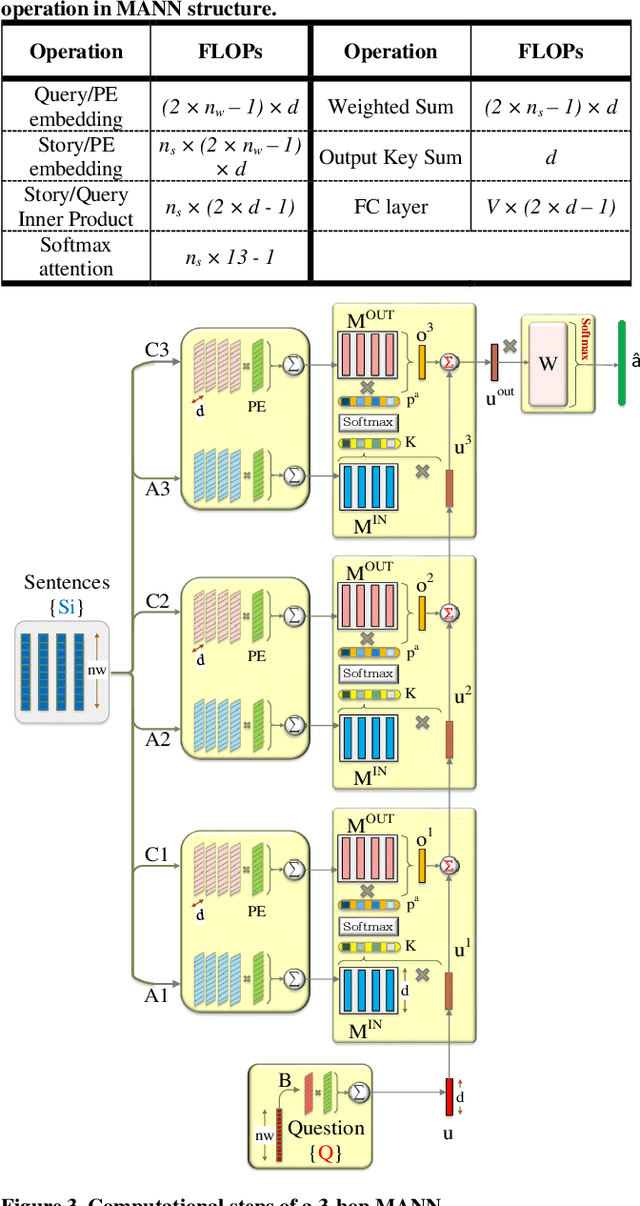
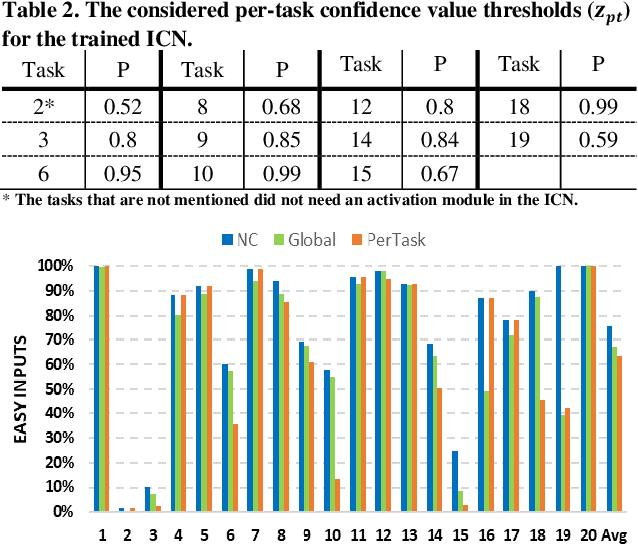
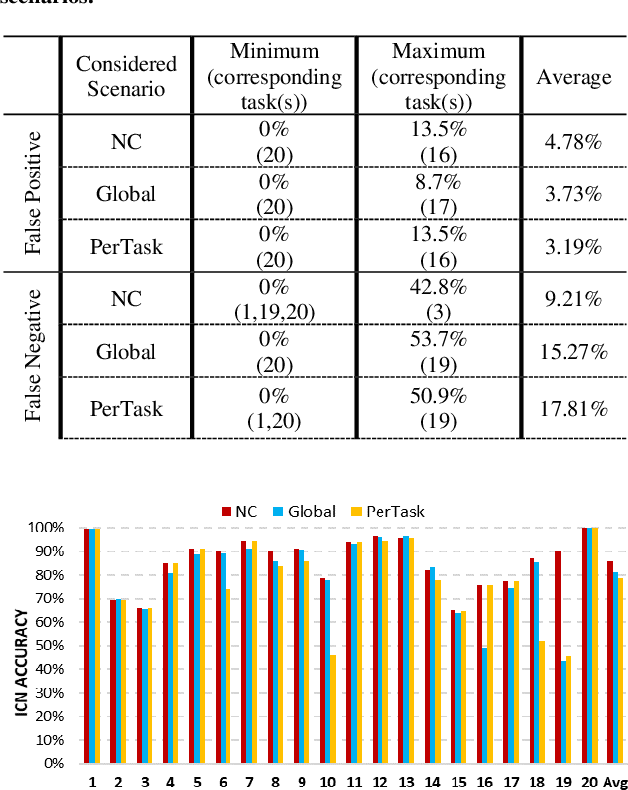
In this work, to limit the number of required attention inference hops in memory-augmented neural networks, we propose an online adaptive approach called A2P-MANN. By exploiting a small neural network classifier, an adequate number of attention inference hops for the input query is determined. The technique results in elimination of a large number of unnecessary computations in extracting the correct answer. In addition, to further lower computations in A2P-MANN, we suggest pruning weights of the final FC (fully-connected) layers. To this end, two pruning approaches, one with negligible accuracy loss and the other with controllable loss on the final accuracy, are developed. The efficacy of the technique is assessed by using the twenty question-answering (QA) tasks of bAbI dataset. The analytical assessment reveals, on average, more than 42% fewer computations compared to the baseline MANN at the cost of less than 1% accuracy loss. In addition, when used along with the previously published zero-skipping technique, a computation count reduction of up to 68% is achieved. Finally, when the proposed approach (without zero-skipping) is implemented on the CPU and GPU platforms, up to 43% runtime reduction is achieved.
BRDS: An FPGA-based LSTM Accelerator with Row-Balanced Dual-Ratio Sparsification
Jan 07, 2021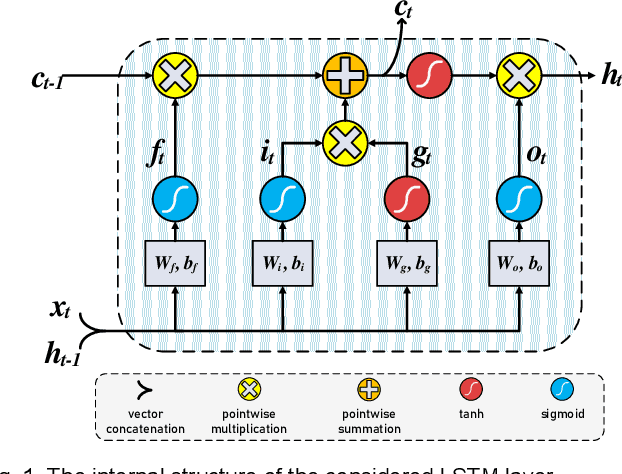

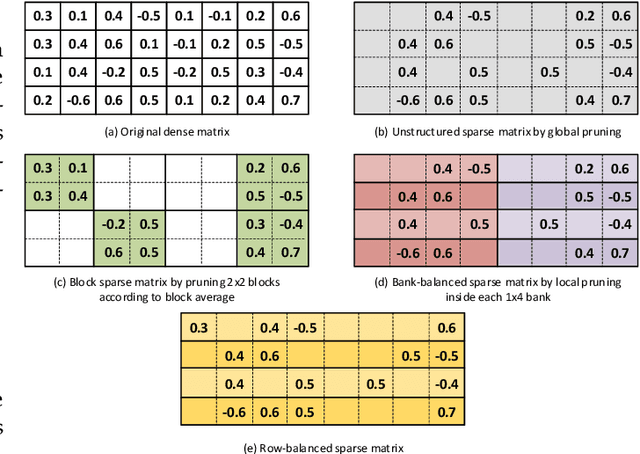
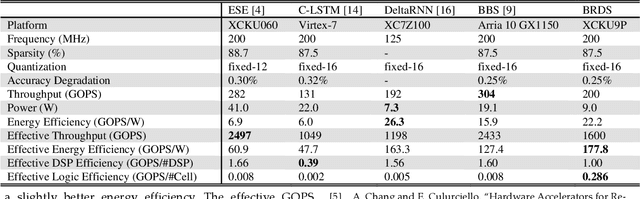
In this paper, first, a hardware-friendly pruning algorithm for reducing energy consumption and improving the speed of Long Short-Term Memory (LSTM) neural network accelerators is presented. Next, an FPGA-based platform for efficient execution of the pruned networks based on the proposed algorithm is introduced. By considering the sensitivity of two weight matrices of the LSTM models in pruning, different sparsity ratios (i.e., dual-ratio sparsity) are applied to these weight matrices. To reduce memory accesses, a row-wise sparsity pattern is adopted. The proposed hardware architecture makes use of computation overlapping and pipelining to achieve low-power and high-speed. The effectiveness of the proposed pruning algorithm and accelerator is assessed under some benchmarks for natural language processing, binary sentiment classification, and speech recognition. Results show that, e.g., compared to a recently published work in this field, the proposed accelerator could provide up to 272% higher effective GOPS/W and the perplexity error is reduced by up to 1.4% for the PTB dataset.
A Tunable Robust Pruning Framework Through Dynamic Network Rewiring of DNNs
Nov 03, 2020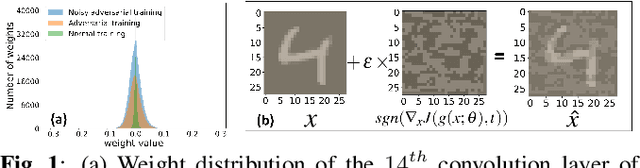

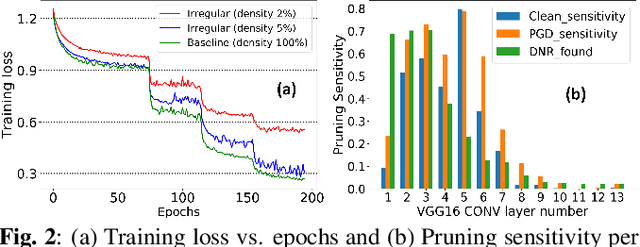
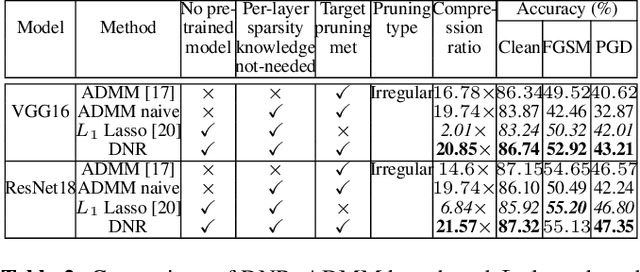
This paper presents a dynamic network rewiring (DNR) method to generate pruned deep neural network (DNN) models that are robust against adversarial attacks yet maintain high accuracy on clean images. In particular, the disclosed DNR method is based on a unified constrained optimization formulation using a hybrid loss function that merges ultra-high model compression with robust adversarial training. This training strategy dynamically adjusts inter-layer connectivity based on per-layer normalized momentum computed from the hybrid loss function. In contrast to existing robust pruning frameworks that require multiple training iterations, the proposed learning strategy achieves an overall target pruning ratio with only a single training iteration and can be tuned to support both irregular and structured channel pruning. To evaluate the merits of DNR, experiments were performed with two widely accepted models, namely VGG16 and ResNet-18, on CIFAR-10, CIFAR-100 as well as with VGG16 on Tiny-ImageNet. Compared to the baseline uncompressed models, DNR provides over20x compression on all the datasets with no significant drop in either clean or adversarial classification accuracy. Moreover, our experiments show that DNR consistently finds compressed models with better clean and adversarial image classification performance than what is achievable through state-of-the-art alternatives.