 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Sparse Identification of Dynamical Systems via Bayesian Model Averaging
Apr 12, 2026In many problems of data-driven modeling for dynamical systems, the governing equations are not known a priori and must be selected phenomenologically from a large set of candidate interactions and basis functions. In such situations, point estimates alone can be misleading, because multiple model components may explain the observed data comparably well, especially when the data are limited or the dynamics exhibit poor identifiability. Quantifying the uncertainty associated with model selection is therefore essential for constructing reliable dynamical models from data. In this work, we develop a Bayesian sparse identification framework for dynamical systems with coupled components, aimed at inferring both interaction structure and functional form together with principled uncertainty quantification. The proposed method combines sparse modeling with Bayesian model averaging, yielding posterior inclusion probabilities that quantify the credibility of each candidate interaction and basis component. Through numerical experiments on oscillator networks, we show that the framework accurately recovers sparse interaction structures with quantified uncertainty, including higher-order harmonic components, phase-lag effects, and multi-body interactions. We also demonstrate that, even in a phenomenological setting where the true governing equations are not contained in the assumed model class, the method can identify effective functional components with quantified uncertainty. These results highlight the importance of Bayesian uncertainty quantification in data-driven discovery of dynamical models.
Automatic Termination Strategy of Inelastic Neutron-scattering Measurement Using Bayesian Optimization for Bin-width Selection
Mar 16, 2026Currently, an excessive amount of event data is being obtained in four-dimensional inelastic neutron-scattering experiments. A method for automatic bin-width optimization of multidimensional histograms has been developed and recently validated on real inelastic neutron-scattering data. However, measuring beyond the equipment resolution leads to inefficient use of valuable beam time. To improve experimental efficiency, an automatic termination strategy is essential. We propose a Bayesian-optimization-based method to compute stopping criteria and determine whether to continue or terminate the experiment in real time. In the proposed method, the bin-width optimization is performed using Bayesian optimization to efficiently compute the optimal bin widths. The experiment is terminated when the optimal bin widths become smaller than the target resolutions. In numerical experiments using real inelastic neutron-scattering data, the optimal bin widths decrease as the number of events increases. Even the optimal bin widths for data downsampled to 1/5 are comparable with the resolutions limited by the sample size, choppers, and so on. This implies excessive measurement of the inelastic neutron experiments for the moment. Moreover, we found that Bayesian optimization can reduce the search cost to approximately 10% of an exhaustive search in our numerical experiments.
Sequential Experimental Design for Spectral Measurement: Active Learning Using a Parametric Model
May 11, 2023



In this study, we demonstrate a sequential experimental design for spectral measurements by active learning using parametric models as predictors. In spectral measurements, it is necessary to reduce the measurement time because of sample fragility and high energy costs. To improve the efficiency of experiments, sequential experimental designs are proposed, in which the subsequent measurement is designed by active learning using the data obtained before the measurement. Conventionally, parametric models are employed in data analysis; when employed for active learning, they are expected to afford a sequential experimental design that improves the accuracy of data analysis. However, due to the complexity of the formulas, a sequential experimental design using general parametric models has not been realized. Therefore, we applied Bayesian inference-based data analysis using the exchange Monte Carlo method to realize a sequential experimental design with general parametric models. In this study, we evaluated the effectiveness of the proposed method by applying it to Bayesian spectral deconvolution and Bayesian Hamiltonian selection in X-ray photoelectron spectroscopy. Using numerical experiments with artificial data, we demonstrated that the proposed method improves the accuracy of model selection and parameter estimation while reducing the measurement time compared with the results achieved without active learning or with active learning using the Gaussian process regression.
Statistical Mechanical Analysis of Catastrophic Forgetting in Continual Learning with Teacher and Student Networks
May 16, 2021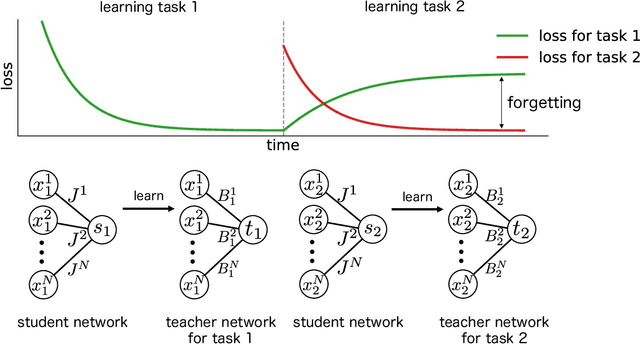
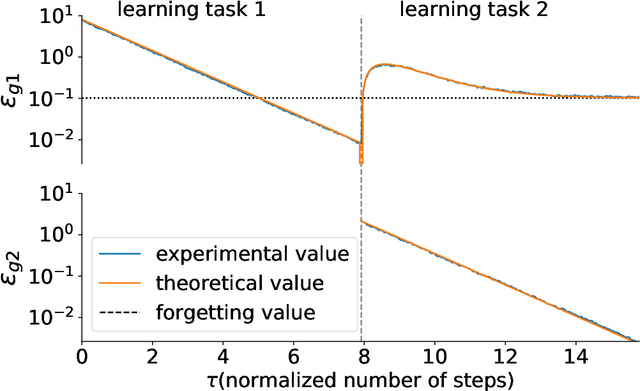
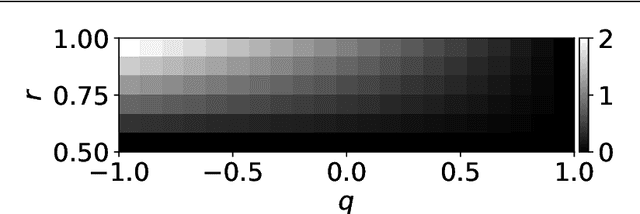
When a computational system continuously learns from an ever-changing environment, it rapidly forgets its past experiences. This phenomenon is called catastrophic forgetting. While a line of studies has been proposed with respect to avoiding catastrophic forgetting, most of the methods are based on intuitive insights into the phenomenon, and their performances have been evaluated by numerical experiments using benchmark datasets. Therefore, in this study, we provide the theoretical framework for analyzing catastrophic forgetting by using teacher-student learning. Teacher-student learning is a framework in which we introduce two neural networks: one neural network is a target function in supervised learning, and the other is a learning neural network. To analyze continual learning in the teacher-student framework, we introduce the similarity of the input distribution and the input-output relationship of the target functions as the similarity of tasks. In this theoretical framework, we also provide a qualitative understanding of how a single-layer linear learning neural network forgets tasks. Based on the analysis, we find that the network can avoid catastrophic forgetting when the similarity among input distributions is small and that of the input-output relationship of the target functions is large. The analysis also suggests that a system often exhibits a characteristic phenomenon called overshoot, which means that even if the learning network has once undergone catastrophic forgetting, it is possible that the network may perform reasonably well after further learning of the current task.
Data-Dependence of Plateau Phenomenon in Learning with Neural Network --- Statistical Mechanical Analysis
Jan 10, 2020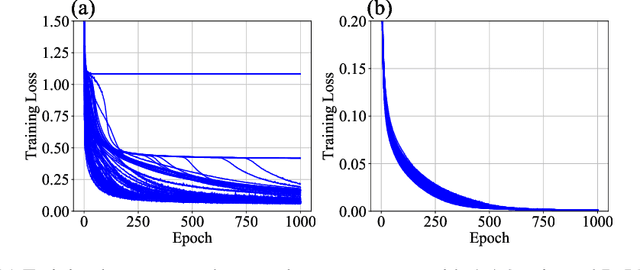
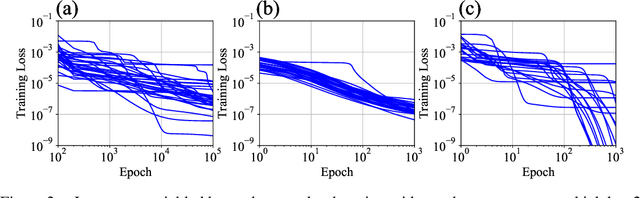
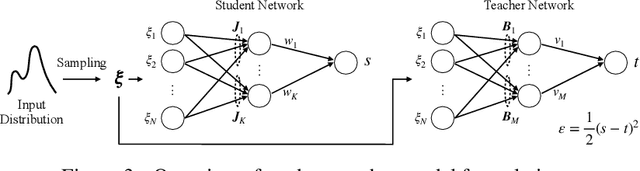
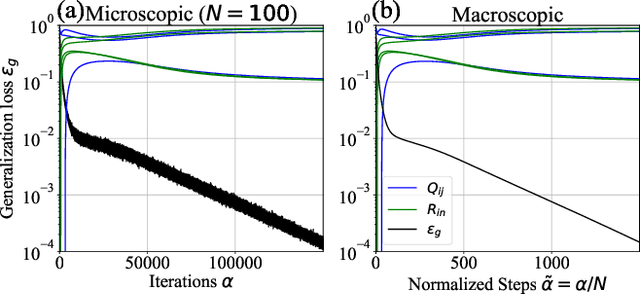
The plateau phenomenon, wherein the loss value stops decreasing during the process of learning, has been reported by various researchers. The phenomenon is actively inspected in the 1990s and found to be due to the fundamental hierarchical structure of neural network models. Then the phenomenon has been thought as inevitable. However, the phenomenon seldom occurs in the context of recent deep learning. There is a gap between theory and reality. In this paper, using statistical mechanical formulation, we clarified the relationship between the plateau phenomenon and the statistical property of the data learned. It is shown that the data whose covariance has small and dispersed eigenvalues tend to make the plateau phenomenon inconspicuous.
Bayesian Spectral Deconvolution Based on Poisson Distribution: Bayesian Measurement and Virtual Measurement Analytics (VMA)
Dec 11, 2018
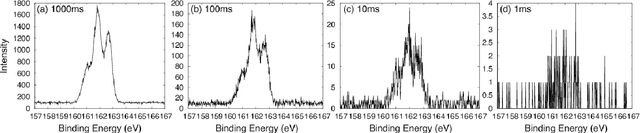
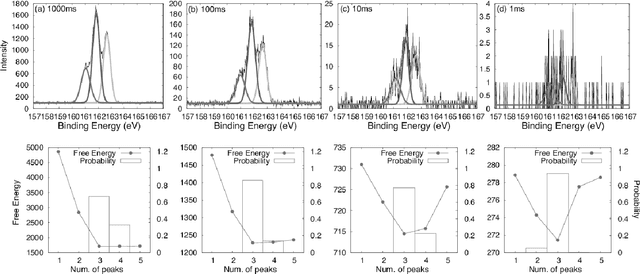
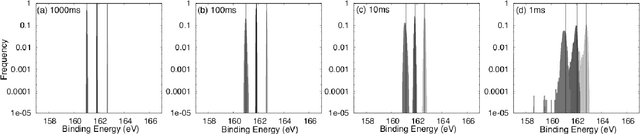
In this paper, we propose a new method of Bayesian measurement for spectral deconvolution, which regresses spectral data into the sum of unimodal basis function such as Gaussian or Lorentzian functions. Bayesian measurement is a framework for considering not only the target physical model but also the measurement model as a probabilistic model, and enables us to estimate the parameter of a physical model with its confidence interval through a Bayesian posterior distribution given a measurement data set. The measurement with Poisson noise is one of the most effective system to apply our proposed method. Since the measurement time is strongly related to the signal-to-noise ratio for the Poisson noise model, Bayesian measurement with Poisson noise model enables us to clarify the relationship between the measurement time and the limit of estimation. In this study, we establish the probabilistic model with Poisson noise for spectral deconvolution. Bayesian measurement enables us to perform virtual and computer simulation for a certain measurement through the established probabilistic model. This property is called "Virtual Measurement Analytics(VMA)" in this paper. We also show that the relationship between the measurement time and the limit of estimation can be extracted by using the proposed method in a simulation of synthetic data and real data for XPS measurement of MoS$_2$.
Statistical mechanical analysis of sparse linear regression as a variable selection problem
Sep 10, 2018
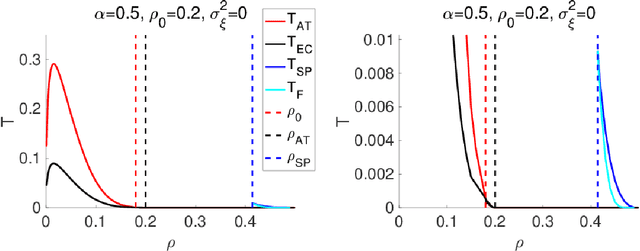
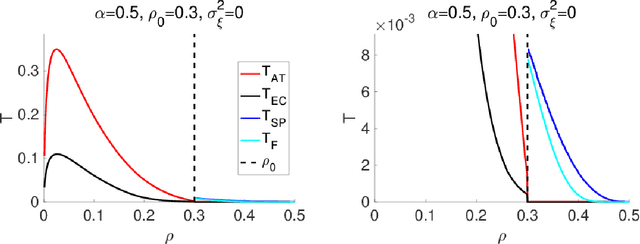
An algorithmic limit of compressed sensing or related variable-selection problems is analytically evaluated when a design matrix is given by an overcomplete random matrix. The replica method from statistical mechanics is employed to derive the result. The analysis is conducted through evaluation of the entropy, an exponential rate of the number of combinations of variables giving a specific value of fit error to given data which is assumed to be generated from a linear process using the design matrix. This yields the typical achievable limit of the fit error when solving a representative $\ell_0$ problem and includes the presence of unfavourable phase transitions preventing local search algorithms from reaching the minimum-error configuration. The associated phase diagrams are presented. A noteworthy outcome of the phase diagrams is that there exists a wide parameter region where any phase transition is absent from the high temperature to the lowest temperature at which the minimum-error configuration or the ground state is reached. This implies that certain local search algorithms can find the ground state with moderate computational costs in that region. Another noteworthy result is the presence of the random first-order transition in the strong noise case. The theoretical evaluation of the entropy is confirmed by extensive numerical methods using the exchange Monte Carlo and the multi-histogram methods. Another numerical test based on a metaheuristic optimisation algorithm called simulated annealing is conducted, which well supports the theoretical predictions on the local search algorithms. In the successful region with no phase transition, the computational cost of the simulated annealing to reach the ground state is estimated as the third order polynomial of the model dimensionality.
Concept Formation and Dynamics of Repeated Inference in Deep Generative Models
Dec 12, 2017
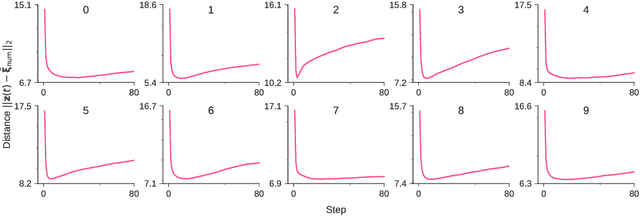
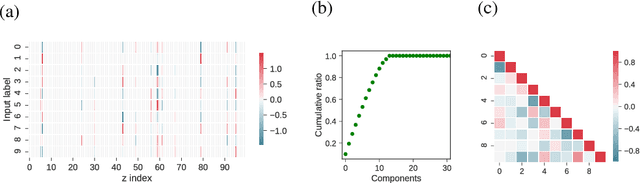
Deep generative models are reported to be useful in broad applications including image generation. Repeated inference between data space and latent space in these models can denoise cluttered images and improve the quality of inferred results. However, previous studies only qualitatively evaluated image outputs in data space, and the mechanism behind the inference has not been investigated. The purpose of the current study is to numerically analyze changes in activity patterns of neurons in the latent space of a deep generative model called a "variational auto-encoder" (VAE). What kinds of inference dynamics the VAE demonstrates when noise is added to the input data are identified. The VAE embeds a dataset with clear cluster structures in the latent space and the center of each cluster of multiple correlated data points (memories) is referred as the concept. Our study demonstrated that transient dynamics of inference first approaches a concept, and then moves close to a memory. Moreover, the VAE revealed that the inference dynamics approaches a more abstract concept to the extent that the uncertainty of input data increases due to noise. It was demonstrated that by increasing the number of the latent variables, the trend of the inference dynamics to approach a concept can be enhanced, and the generalization ability of the VAE can be improved.
Exhaustive search for sparse variable selection in linear regression
Jul 07, 2017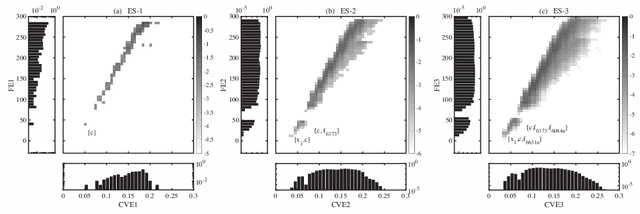
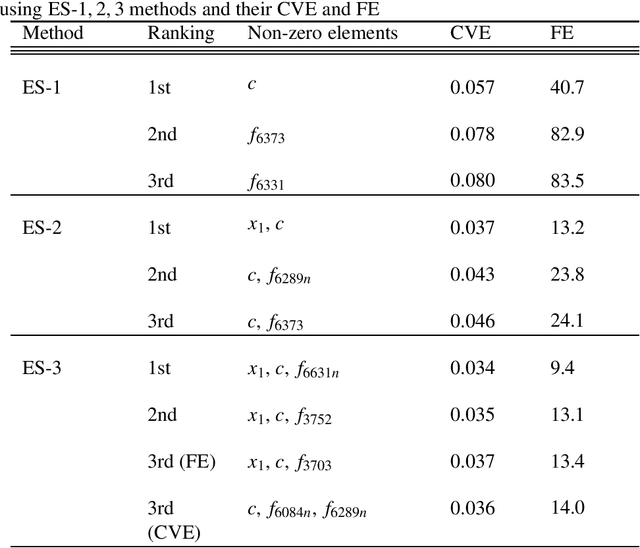
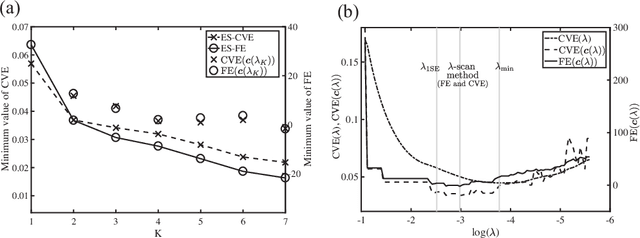

We propose a K-sparse exhaustive search (ES-K) method and a K-sparse approximate exhaustive search method (AES-K) for selecting variables in linear regression. With these methods, K-sparse combinations of variables are tested exhaustively assuming that the optimal combination of explanatory variables is K-sparse. By collecting the results of exhaustively computing ES-K, various approximate methods for selecting sparse variables can be summarized as density of states. With this density of states, we can compare different methods for selecting sparse variables such as relaxation and sampling. For large problems where the combinatorial explosion of explanatory variables is crucial, the AES-K method enables density of states to be effectively reconstructed by using the replica-exchange Monte Carlo method and the multiple histogram method. Applying the ES-K and AES-K methods to type Ia supernova data, we confirmed the conventional understanding in astronomy when an appropriate K is given beforehand. However, we found the difficulty to determine K from the data. Using virtual measurement and analysis, we argue that this is caused by data shortage.
Statistical Mechanics of Node-perturbation Learning with Noisy Baseline
Jun 20, 2017



Node-perturbation learning is a type of statistical gradient descent algorithm that can be applied to problems where the objective function is not explicitly formulated, including reinforcement learning. It estimates the gradient of an objective function by using the change in the object function in response to the perturbation. The value of the objective function for an unperturbed output is called a baseline. Cho et al. proposed node-perturbation learning with a noisy baseline. In this paper, we report on building the statistical mechanics of Cho's model and on deriving coupled differential equations of order parameters that depict learning dynamics. We also show how to derive the generalization error by solving the differential equations of order parameters. On the basis of the results, we show that Cho's results are also apply in general cases and show some general performances of Cho's model.
* 16 pages, 7 figures, submitted to JPSJ