 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVDistNet: Self-Supervised Near-Field Distance Estimation on Surround View Fisheye Cameras
Apr 09, 2021
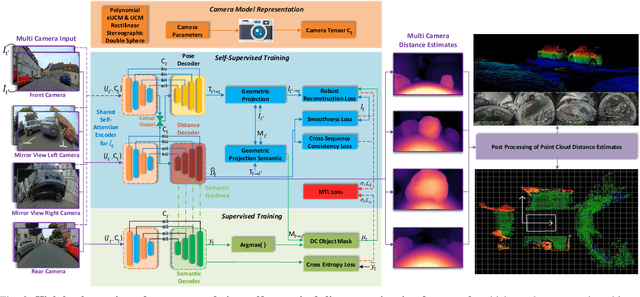
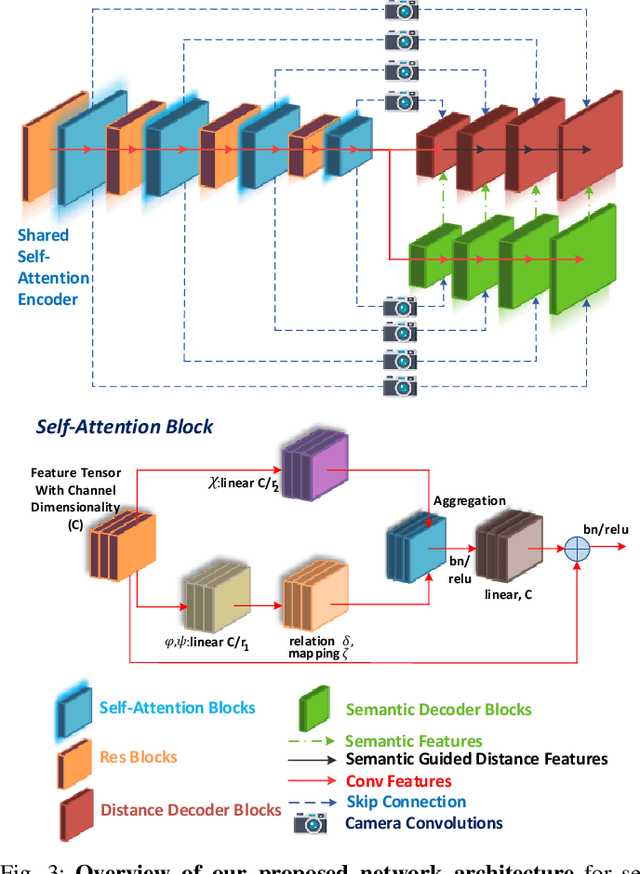

A 360{\deg} perception of scene geometry is essential for automated driving, notably for parking and urban driving scenarios. Typically, it is achieved using surround-view fisheye cameras, focusing on the near-field area around the vehicle. The majority of current depth estimation approaches focus on employing just a single camera, which cannot be straightforwardly generalized to multiple cameras. The depth estimation model must be tested on a variety of cameras equipped to millions of cars with varying camera geometries. Even within a single car, intrinsics vary due to manufacturing tolerances. Deep learning models are sensitive to these changes, and it is practically infeasible to train and test on each camera variant. As a result, we present novel camera-geometry adaptive multi-scale convolutions which utilize the camera parameters as a conditional input, enabling the model to generalize to previously unseen fisheye cameras. Additionally, we improve the distance estimation by pairwise and patchwise vector-based self-attention encoder networks. We evaluate our approach on the Fisheye WoodScape surround-view dataset, significantly improving over previous approaches. We also show a generalization of our approach across different camera viewing angles and perform extensive experiments to support our contributions. To enable comparison with other approaches, we evaluate the front camera data on the KITTI dataset (pinhole camera images) and achieve state-of-the-art performance among self-supervised monocular methods. An overview video with qualitative results is provided at https://youtu.be/bmX0UcU9wtA. Baseline code and dataset will be made public.
Unsupervised BatchNorm Adaptation (UBNA): A Domain Adaptation Method for Semantic Segmentation Without Using Source Domain Representations
Nov 17, 2020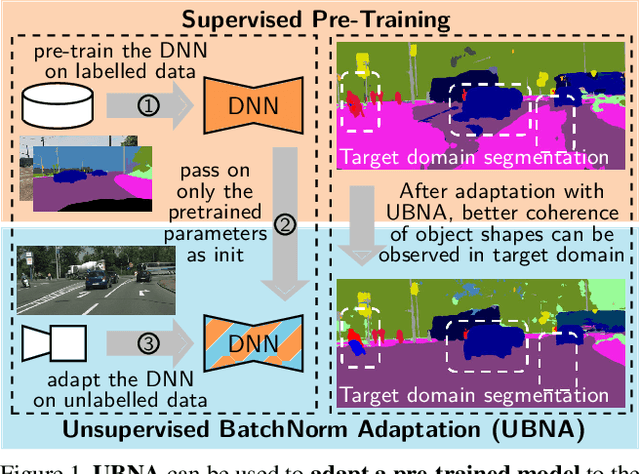
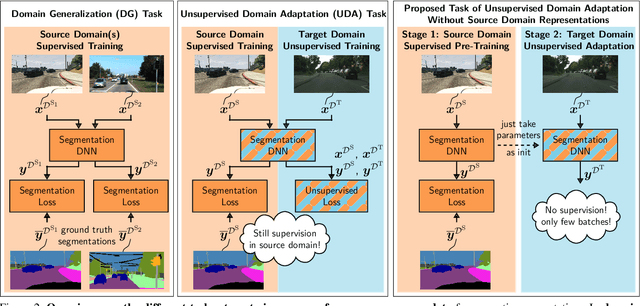
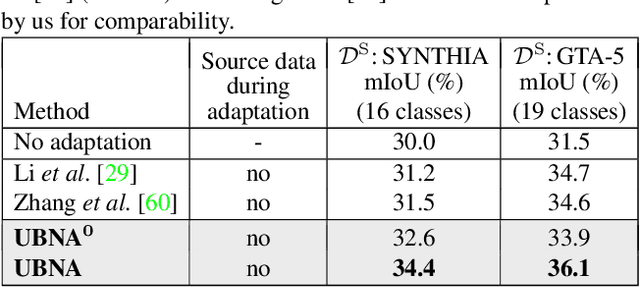
In this paper we present a solution to the task of "unsupervised domain adaptation (UDA) of a pre-trained semantic segmentation model without relying on any source domain representations". Previous UDA approaches for semantic segmentation either employed simultaneous training of the model in the source and target domains, or they relied on a generator network, replaying source domain data to the model during adaptation. In contrast, we present our novel Unsupervised BatchNorm Adaptation (UBNA) method, which adapts a pre-trained model to an unseen target domain without using---beyond the existing model parameters from pre-training---any source domain representations (neither data, nor generators) and which can also be applied in an online setting or using just a few unlabeled images from the target domain in a few-shot manner. Specifically, we partially adapt the normalization layer statistics to the target domain using an exponentially decaying momentum factor, thereby mixing the statistics from both domains. By evaluation on standard UDA benchmarks for semantic segmentation we show that this is superior to a model without adaptation and to baseline approaches using statistics from the target domain only. Compared to standard UDA approaches we report a trade-off between performance and usage of source domain representations.
SynDistNet: Self-Supervised Monocular Fisheye Camera Distance Estimation Synergized with Semantic Segmentation for Autonomous Driving
Aug 10, 2020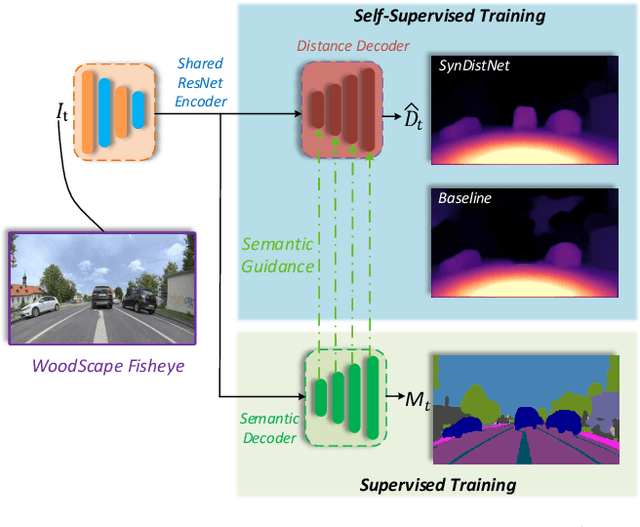
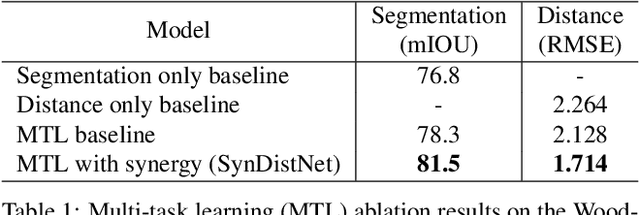
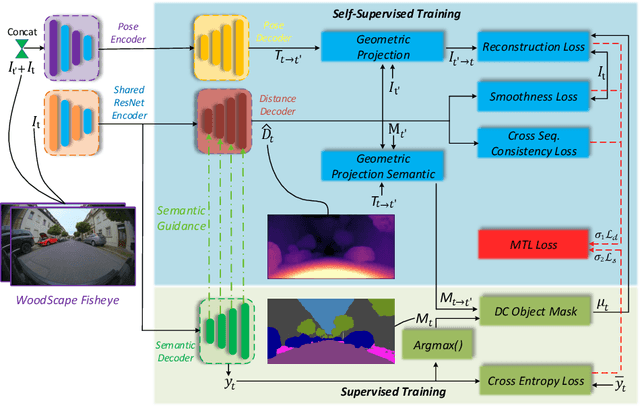
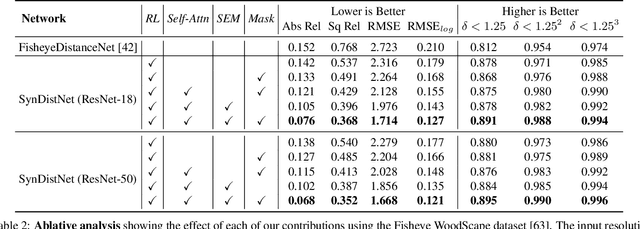
State-of-the-art self-supervised learning approaches for monocular depth estimation usually suffer from scale ambiguity. They do not generalize well when applied on distance estimation for complex projection models such as in fisheye and omnidirectional cameras. In this paper, we introduce a novel multi-task learning strategy to improve self-supervised monocular distance estimation on fisheye and pinhole camera images. Our contribution to this work is threefold: Firstly, we introduce a novel distance estimation network architecture using a self-attention based encoder coupled with robust semantic feature guidance to the decoder that can be trained in a one-stage fashion. Secondly, we integrate a generalized robust loss function, which improves performance significantly while removing the need for hyperparameter tuning with the reprojection loss. Finally, we reduce the artifacts caused by dynamic objects violating static world assumption by using a semantic masking strategy. We significantly improve upon the RMSE of previous work on fisheye by 25% reduction in RMSE. As there is limited work on fisheye cameras, we evaluated the proposed method on KITTI using a pinhole model.We achieved state-of-the-art performance among self-supervised methods without requiring an external scale estimation.
Self-Supervised Monocular Depth Estimation: Solving the Dynamic Object Problem by Semantic Guidance
Jul 21, 2020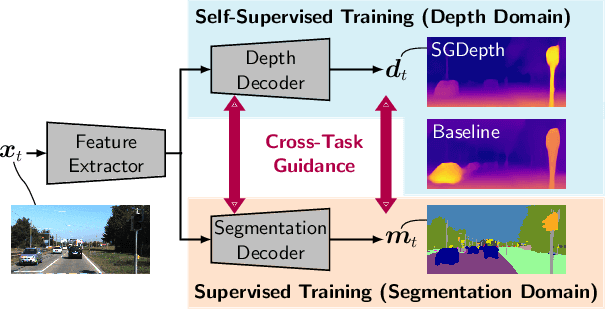
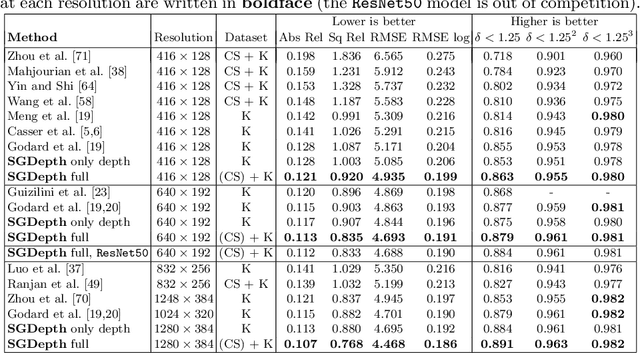
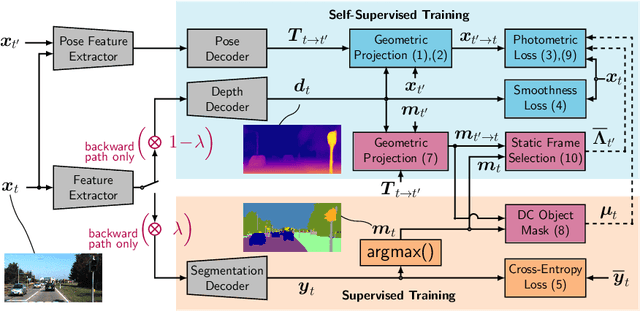
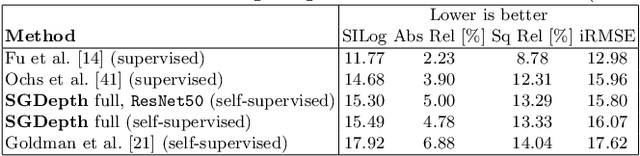
Self-supervised monocular depth estimation presents a powerful method to obtain 3D scene information from single camera images, which is trainable on arbitrary image sequences without requiring depth labels, e.g., from a LiDAR sensor. In this work we present a new self-supervised semantically-guided depth estimation (SGDepth) method to deal with moving dynamic-class (DC) objects, such as moving cars and pedestrians, which violate the static-world assumptions typically made during training of such models. Specifically, we propose (i) mutually beneficial cross-domain training of (supervised) semantic segmentation and self-supervised depth estimation with task-specific network heads, (ii) a semantic masking scheme providing guidance to prevent moving DC objects from contaminating the photometric loss, and (iii) a detection method for frames with non-moving DC objects, from which the depth of DC objects can be learned. We demonstrate the performance of our method on several benchmarks, in particular on the Eigen split, where we exceed all baselines without test-time refinement.
Self-Supervised Domain Mismatch Estimation for Autonomous Perception
Jun 15, 2020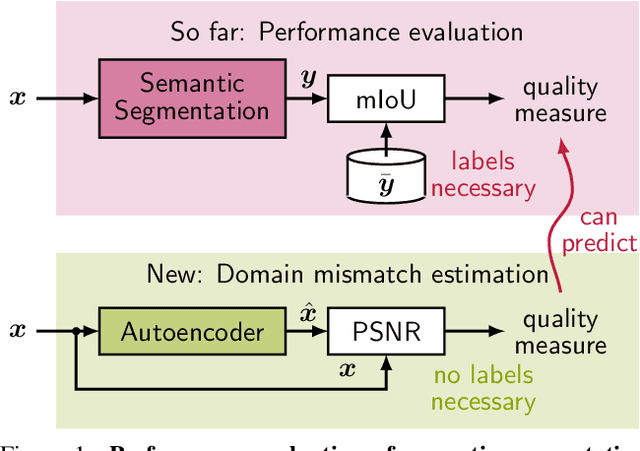
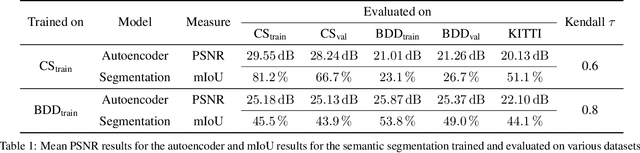
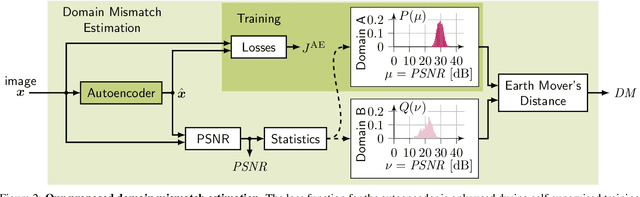
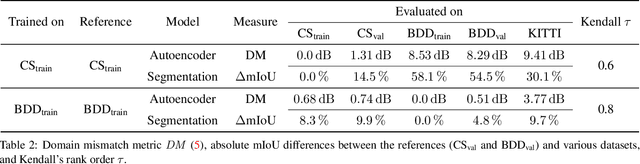
Autonomous driving requires self awareness of its perception functions. Technically spoken, this can be realized by observers, which monitor the performance indicators of various perception modules. In this work we choose, exemplarily, a semantic segmentation to be monitored, and propose an autoencoder, trained in a self-supervised fashion on the very same training data as the semantic segmentation to be monitored. While the autoencoder's image reconstruction performance (PSNR) during online inference shows already a good predictive power w.r.t. semantic segmentation performance, we propose a novel domain mismatch metric DM as the earth mover's distance between a pre-stored PSNR distribution on training (source) data, and an online-acquired PSNR distribution on any inference (target) data. We are able to show by experiments that the DM metric has a strong rank order correlation with the semantic segmentation within its functional scope. We also propose a training domain-dependent threshold for the DM metric to define this functional scope.
Class-Incremental Learning for Semantic Segmentation Re-Using Neither Old Data Nor Old Labels
May 12, 2020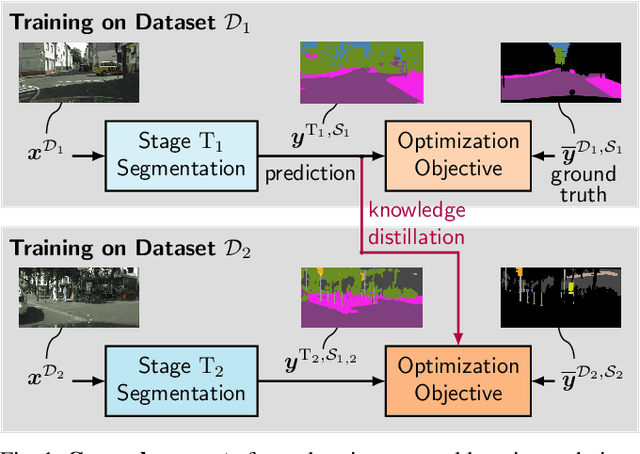
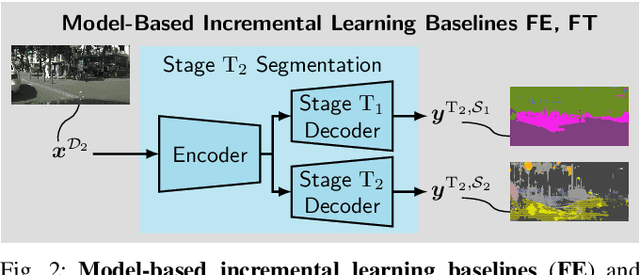
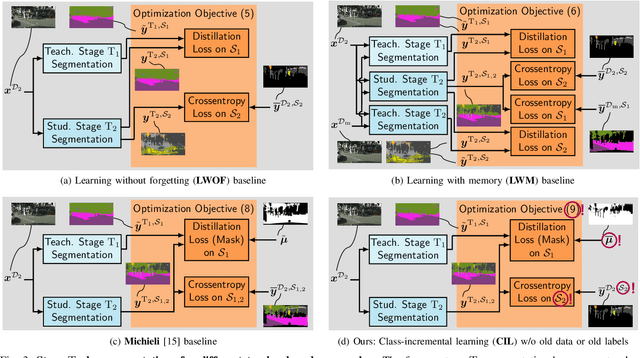
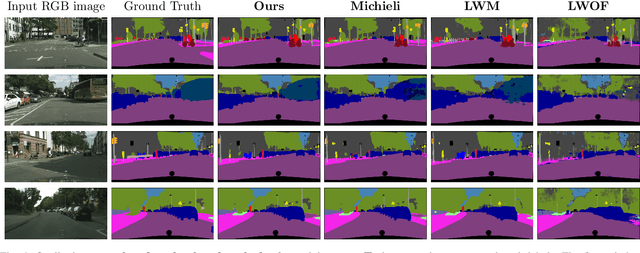
While neural networks trained for semantic segmentation are essential for perception in autonomous driving, most current algorithms assume a fixed number of classes, presenting a major limitation when developing new autonomous driving systems with the need of additional classes. In this paper we present a technique implementing class-incremental learning for semantic segmentation without using the labeled data the model was initially trained on. Previous approaches still either rely on labels for both old and new classes, or fail to properly distinguish between them. We show how to overcome these problems with a novel class-incremental learning technique, which nonetheless requires labels only for the new classes. Specifically, (i) we introduce a new loss function that neither relies on old data nor on old labels, (ii) we show how new classes can be integrated in a modular fashion into pretrained semantic segmentation models, and finally (iii) we re-implement previous approaches in a unified setting to compare them to ours. We evaluate our method on the Cityscapes dataset, where we exceed the mIoU performance of all baselines by 3.5% absolute reaching a result, which is only 2.2% absolute below the upper performance limit of single-stage training, relying on all data and labels simultaneously.
Improved Noise and Attack Robustness for Semantic Segmentation by Using Multi-Task Training with Self-Supervised Depth Estimation
Apr 23, 2020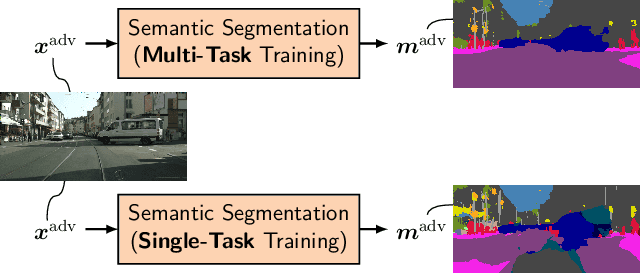
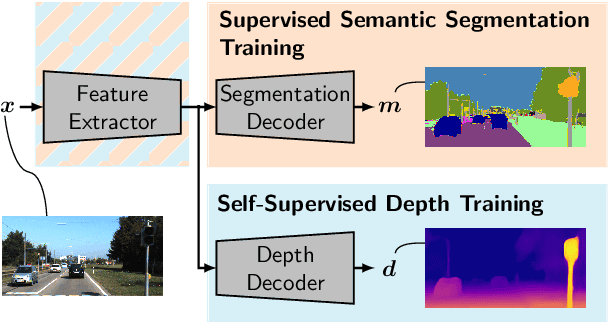
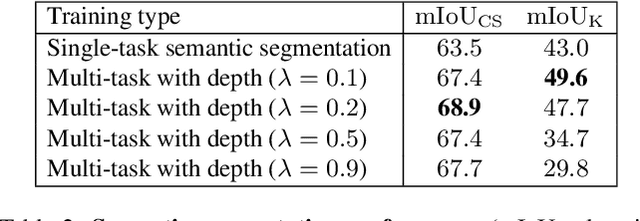
While current approaches for neural network training often aim at improving performance, less focus is put on training methods aiming at robustness towards varying noise conditions or directed attacks by adversarial examples. In this paper, we propose to improve robustness by a multi-task training, which extends supervised semantic segmentation by a self-supervised monocular depth estimation on unlabeled videos. This additional task is only performed during training to improve the semantic segmentation model's robustness at test time under several input perturbations. Moreover, we even find that our joint training approach also improves the performance of the model on the original (supervised) semantic segmentation task. Our evaluation exhibits a particular novelty in that it allows to mutually compare the effect of input noises and adversarial attacks on the robustness of the semantic segmentation. We show the effectiveness of our method on the Cityscapes dataset, where our multi-task training approach consistently outperforms the single-task semantic segmentation baseline in terms of both robustness vs. noise and in terms of adversarial attacks, without the need for depth labels in training.