 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Differentially Private Models with Secure Multiparty Computation
Feb 05, 2022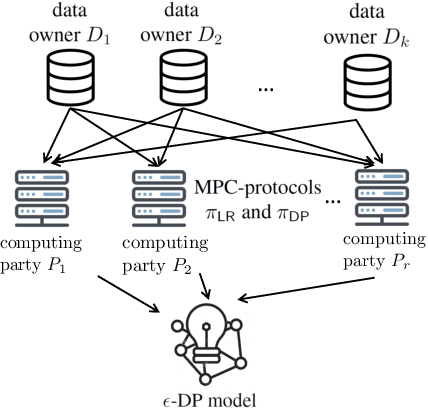

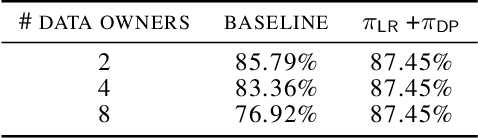

We address the problem of learning a machine learning model from training data that originates at multiple data owners while providing formal privacy guarantees regarding the protection of each owner's data. Existing solutions based on Differential Privacy (DP) achieve this at the cost of a drop in accuracy. Solutions based on Secure Multiparty Computation (MPC) do not incur such accuracy loss but leak information when the trained model is made publicly available. We propose an MPC solution for training DP models. Our solution relies on an MPC protocol for model training, and an MPC protocol for perturbing the trained model coefficients with Laplace noise in a privacy-preserving manner. The resulting MPC+DP approach achieves higher accuracy than a pure DP approach while providing the same formal privacy guarantees. Our work obtained first place in the iDASH2021 Track III competition on confidential computing for secure genome analysis.
Privacy-Preserving Training of Tree Ensembles over Continuous Data
Jun 05, 2021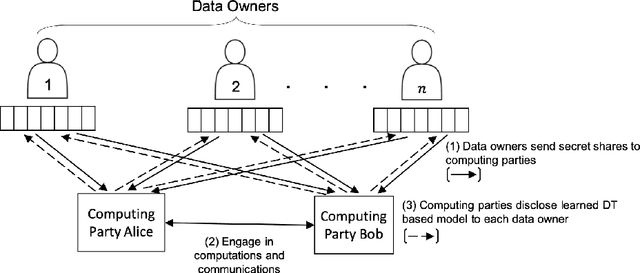
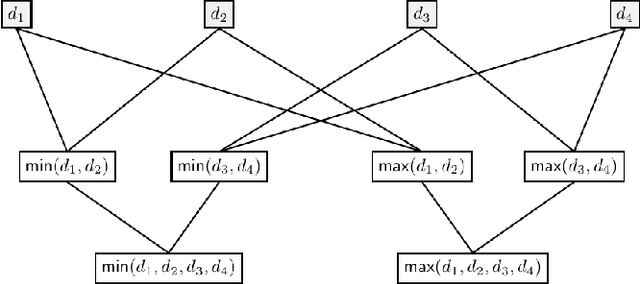
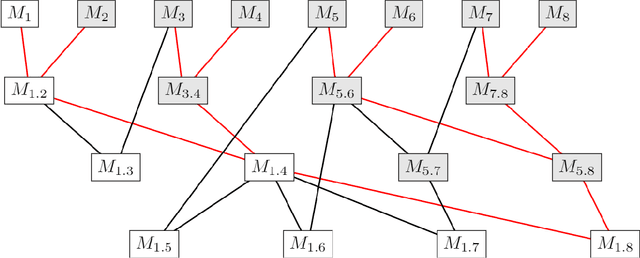
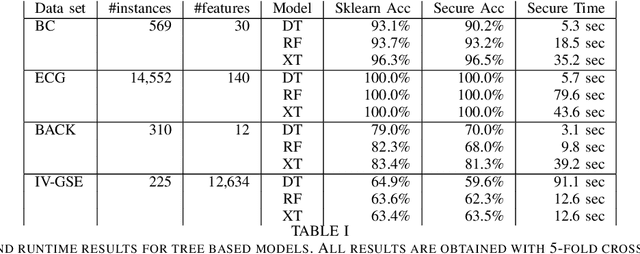
Most existing Secure Multi-Party Computation (MPC) protocols for privacy-preserving training of decision trees over distributed data assume that the features are categorical. In real-life applications, features are often numerical. The standard ``in the clear'' algorithm to grow decision trees on data with continuous values requires sorting of training examples for each feature in the quest for an optimal cut-point in the range of feature values in each node. Sorting is an expensive operation in MPC, hence finding secure protocols that avoid such an expensive step is a relevant problem in privacy-preserving machine learning. In this paper we propose three more efficient alternatives for secure training of decision tree based models on data with continuous features, namely: (1) secure discretization of the data, followed by secure training of a decision tree over the discretized data; (2) secure discretization of the data, followed by secure training of a random forest over the discretized data; and (3) secure training of extremely randomized trees (``extra-trees'') on the original data. Approaches (2) and (3) both involve randomizing feature choices. In addition, in approach (3) cut-points are chosen randomly as well, thereby alleviating the need to sort or to discretize the data up front. We implemented all proposed solutions in the semi-honest setting with additive secret sharing based MPC. In addition to mathematically proving that all proposed approaches are correct and secure, we experimentally evaluated and compared them in terms of classification accuracy and runtime. We privately train tree ensembles over data sets with 1000s of instances or features in a few minutes, with accuracies that are at par with those obtained in the clear. This makes our solution orders of magnitude more efficient than the existing approaches, which are based on oblivious sorting.
Privacy-Preserving Feature Selection with Secure Multiparty Computation
Feb 06, 2021

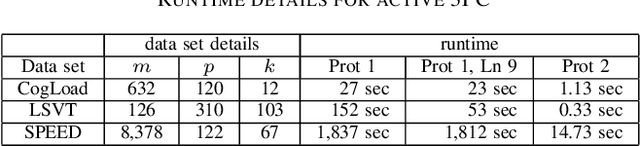
Existing work on privacy-preserving machine learning with Secure Multiparty Computation (MPC) is almost exclusively focused on model training and on inference with trained models, thereby overlooking the important data pre-processing stage. In this work, we propose the first MPC based protocol for private feature selection based on the filter method, which is independent of model training, and can be used in combination with any MPC protocol to rank features. We propose an efficient feature scoring protocol based on Gini impurity to this end. To demonstrate the feasibility of our approach for practical data science, we perform experiments with the proposed MPC protocols for feature selection in a commonly used machine-learning-as-a-service configuration where computations are outsourced to multiple servers, with semi-honest and with malicious adversaries. Regarding effectiveness, we show that secure feature selection with the proposed protocols improves the accuracy of classifiers on a variety of real-world data sets, without leaking information about the feature values or even which features were selected. Regarding efficiency, we document runtimes ranging from several seconds to an hour for our protocols to finish, depending on the size of the data set and the security settings.
Privacy-Preserving Video Classification with Convolutional Neural Networks
Feb 06, 2021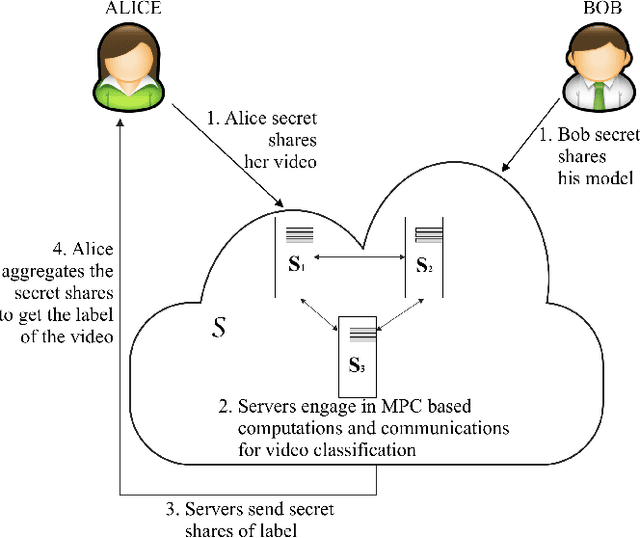
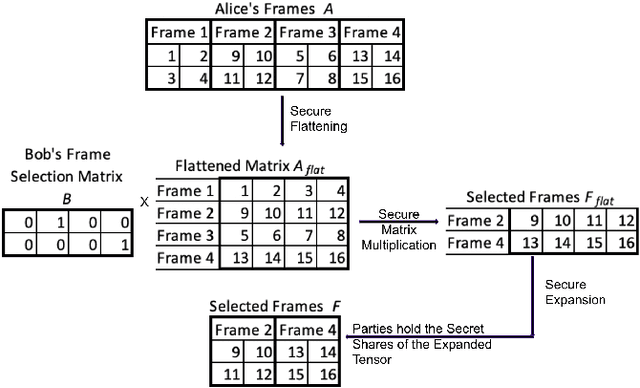


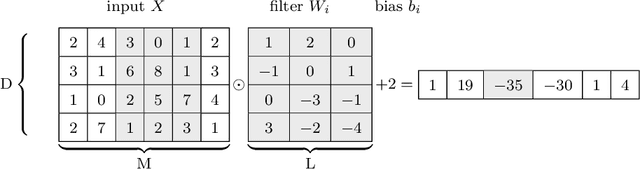
Many video classification applications require access to personal data, thereby posing an invasive security risk to the users' privacy. We propose a privacy-preserving implementation of single-frame method based video classification with convolutional neural networks that allows a party to infer a label from a video without necessitating the video owner to disclose their video to other entities in an unencrypted manner. Similarly, our approach removes the requirement of the classifier owner from revealing their model parameters to outside entities in plaintext. To this end, we combine existing Secure Multi-Party Computation (MPC) protocols for private image classification with our novel MPC protocols for oblivious single-frame selection and secure label aggregation across frames. The result is an end-to-end privacy-preserving video classification pipeline. We evaluate our proposed solution in an application for private human emotion recognition. Our results across a variety of security settings, spanning honest and dishonest majority configurations of the computing parties, and for both passive and active adversaries, demonstrate that videos can be classified with state-of-the-art accuracy, and without leaking sensitive user information.
Private Speech Characterization with Secure Multiparty Computation
Jul 01, 2020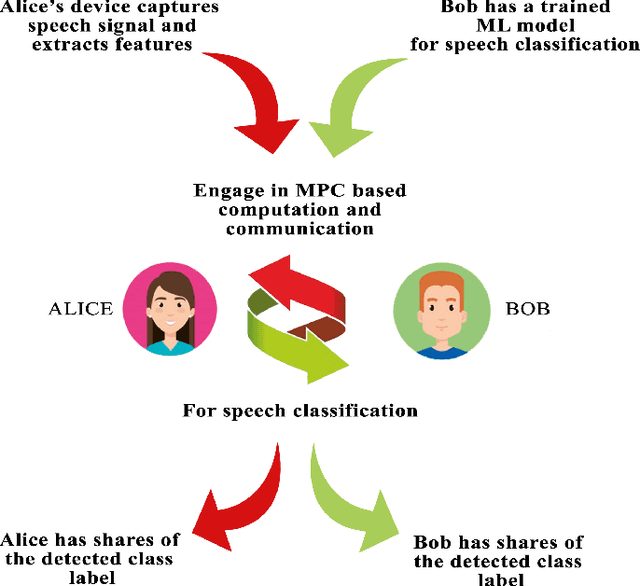

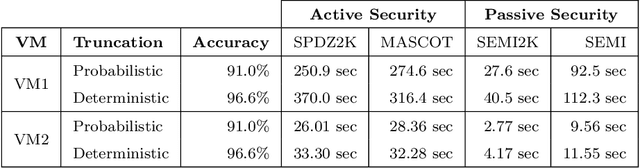
Deep learning in audio signal processing, such as human voice audio signal classification, is a rich application area of machine learning. Legitimate use cases include voice authentication, gunfire detection, and emotion recognition. While there are clear advantages to automated human speech classification, application developers can gain knowledge beyond the professed scope from unprotected audio signal processing. In this paper we propose the first privacy-preserving solution for deep learning-based audio classification that is provably secure. Our approach, which is based on Secure Multiparty Computation, allows to classify a speech signal of one party (Alice) with a deep neural network of another party (Bob) without Bob ever seeing Alice's speech signal in an unencrypted manner. As threat models, we consider both passive security, i.e. with semi-honest parties who follow the instructions of the cryptographic protocols, as well as active security, i.e. with malicious parties who deviate from the protocols. We evaluate the efficiency-security-accuracy trade-off of the proposed solution in a use case for privacy-preserving emotion detection from speech with a convolutional neural network. In the semi-honest case we can classify a speech signal in under 0.3 sec; in the malicious case it takes $\sim$1.6 sec. In both cases there is no leakage of information, and we achieve classification accuracies that are the same as when computations are done on unencrypted data.
Inline Detection of DGA Domains Using Side Information
Mar 12, 2020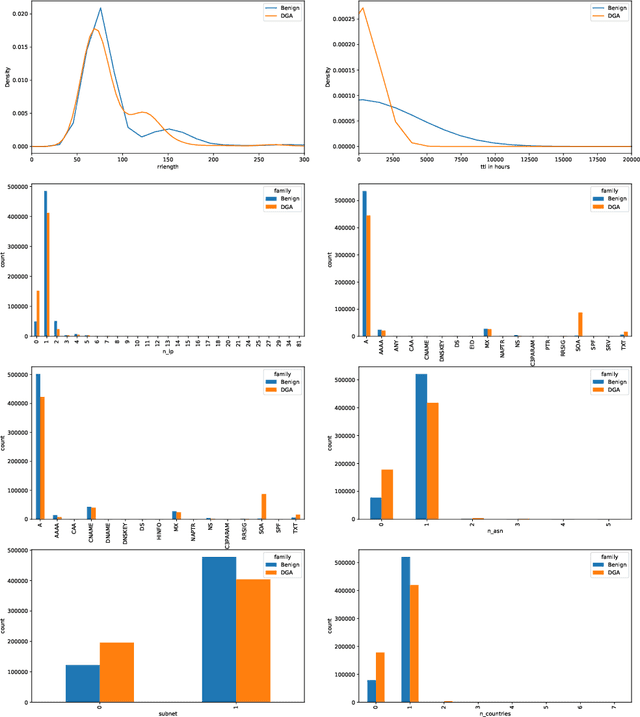

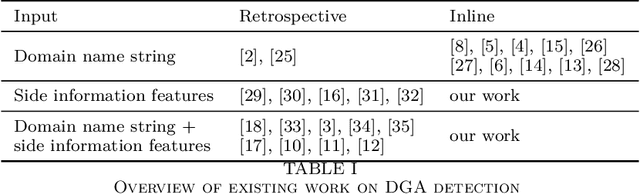

Malware applications typically use a command and control (C&C) server to manage bots to perform malicious activities. Domain Generation Algorithms (DGAs) are popular methods for generating pseudo-random domain names that can be used to establish a communication between an infected bot and the C&C server. In recent years, machine learning based systems have been widely used to detect DGAs. There are several well known state-of-the-art classifiers in the literature that can detect DGA domain names in real-time applications with high predictive performance. However, these DGA classifiers are highly vulnerable to adversarial attacks in which adversaries purposely craft domain names to evade DGA detection classifiers. In our work, we focus on hardening DGA classifiers against adversarial attacks. To this end, we train and evaluate state-of-the-art deep learning and random forest (RF) classifiers for DGA detection using side information that is harder for adversaries to manipulate than the domain name itself. Additionally, the side information features are selected such that they are easily obtainable in practice to perform inline DGA detection. The performance and robustness of these models is assessed by exposing them to one day of real-traffic data as well as domains generated by adversarial attack algorithms. We found that the DGA classifiers that rely on both the domain name and side information have high performance and are more robust against adversaries.
High Performance Logistic Regression for Privacy-Preserving Genome Analysis
Mar 03, 2020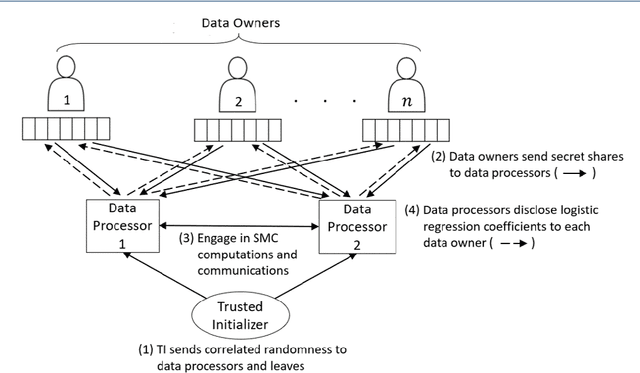
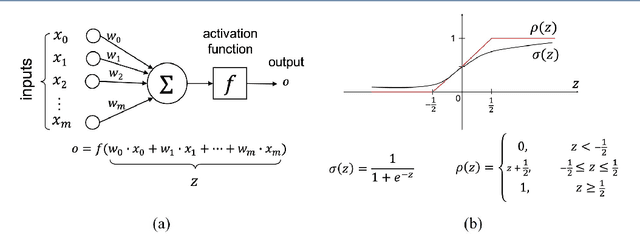
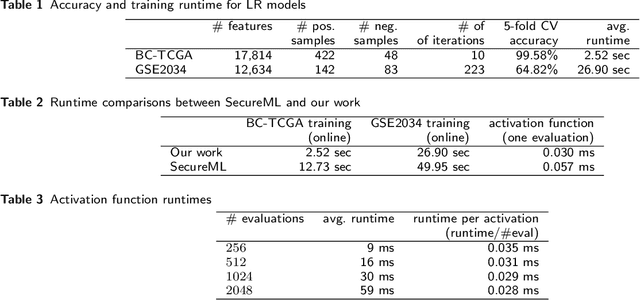
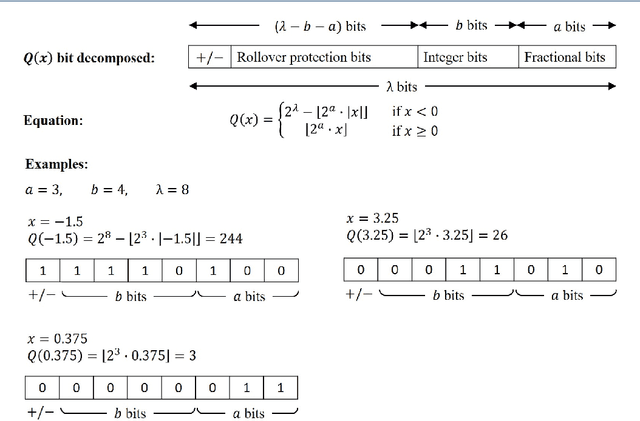
In this paper, we present a secure logistic regression training protocol and its implementation, with a new subprotocol to securely compute the activation function. To the best of our knowledge, we present the fastest existing secure Multi-Party Computation implementation for training logistic regression models on high dimensional genome data distributed across a local area network.
User Profiling Using Hinge-loss Markov Random Fields
Jan 05, 2020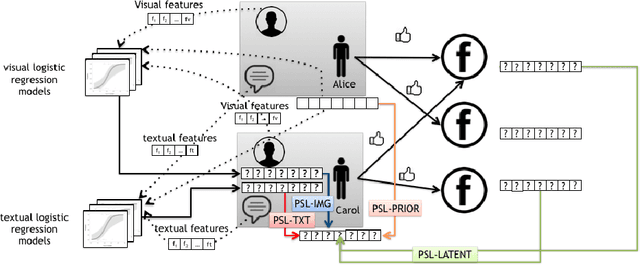
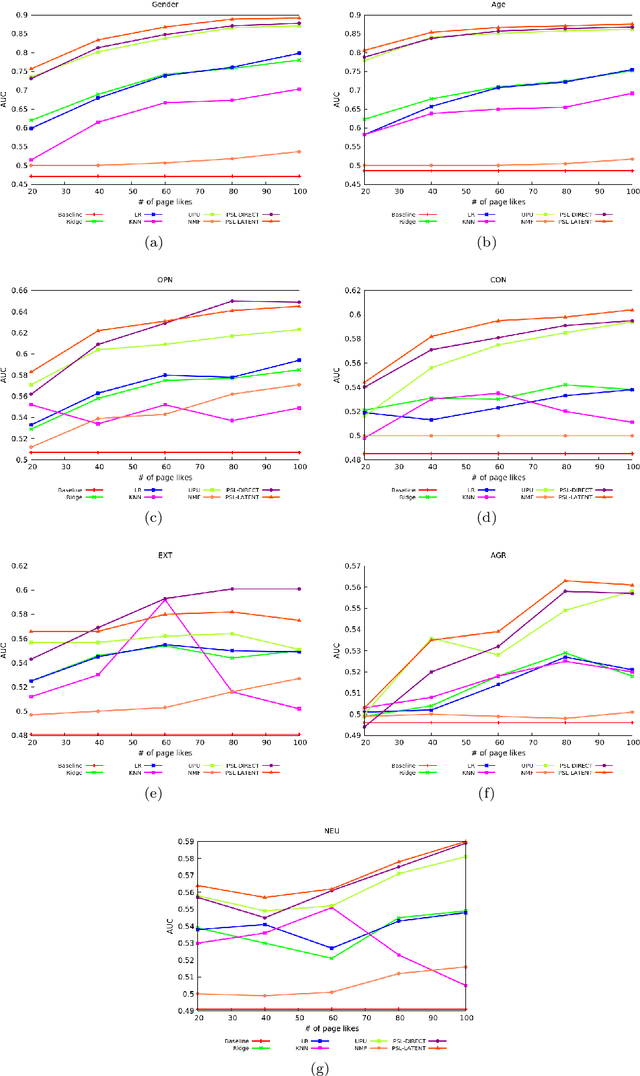
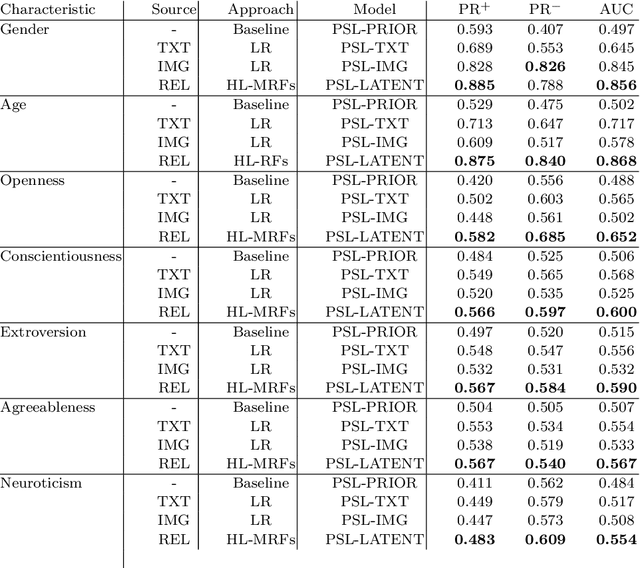
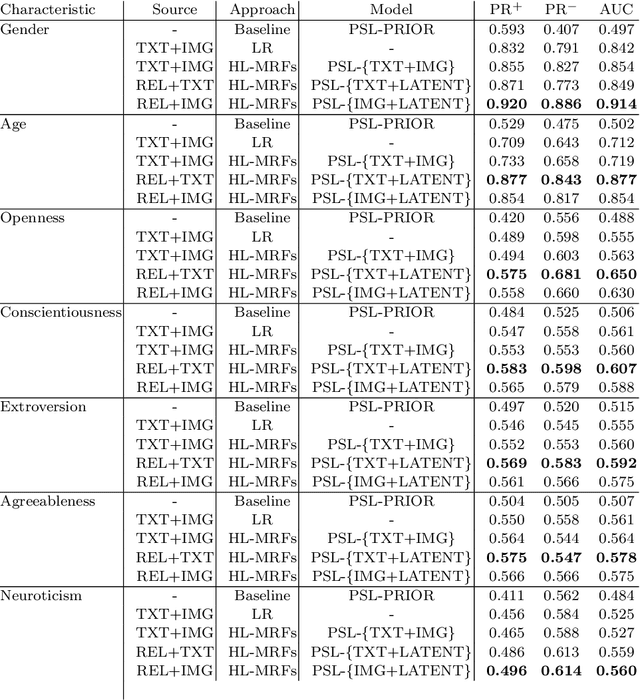
A variety of approaches have been proposed to automatically infer the profiles of users from their digital footprint in social media. Most of the proposed approaches focus on mining a single type of information, while ignoring other sources of available user-generated content (UGC). In this paper, we propose a mechanism to infer a variety of user characteristics, such as, age, gender and personality traits, which can then be compiled into a user profile. To this end, we model social media users by incorporating and reasoning over multiple sources of UGC as well as social relations. Our model is based on a statistical relational learning framework using Hinge-loss Markov Random Fields (HL-MRFs), a class of probabilistic graphical models that can be defined using a set of first-order logical rules. We validate our approach on data from Facebook with more than 5k users and almost 725k relations. We show how HL-MRFs can be used to develop a generic and extensible user profiling framework by leveraging textual, visual, and relational content in the form of status updates, profile pictures and Facebook page likes. Our experimental results demonstrate that our proposed model successfully incorporates multiple sources of information and outperforms competing methods that use only one source of information or an ensemble method across the different sources for modeling of users in social media.
Protecting Privacy of Users in Brain-Computer Interface Applications
Jul 02, 2019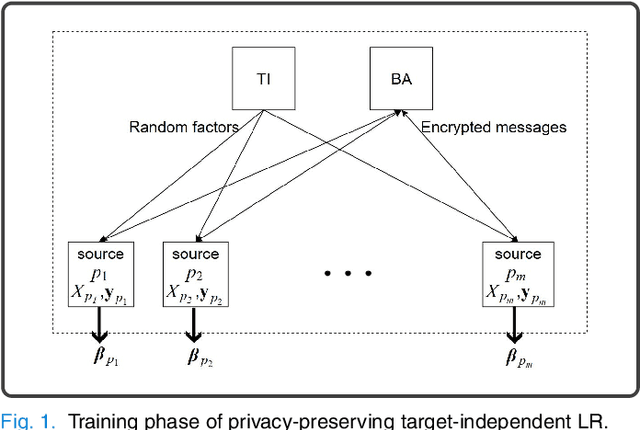
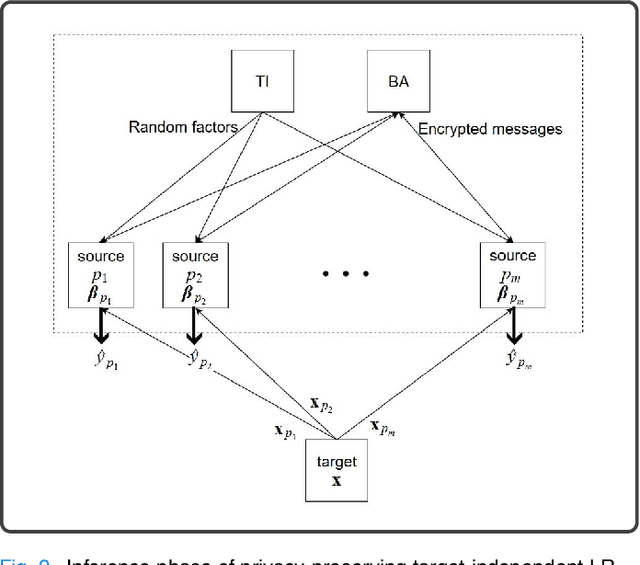
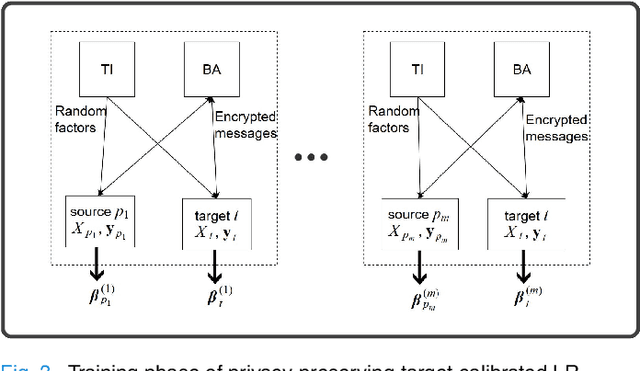
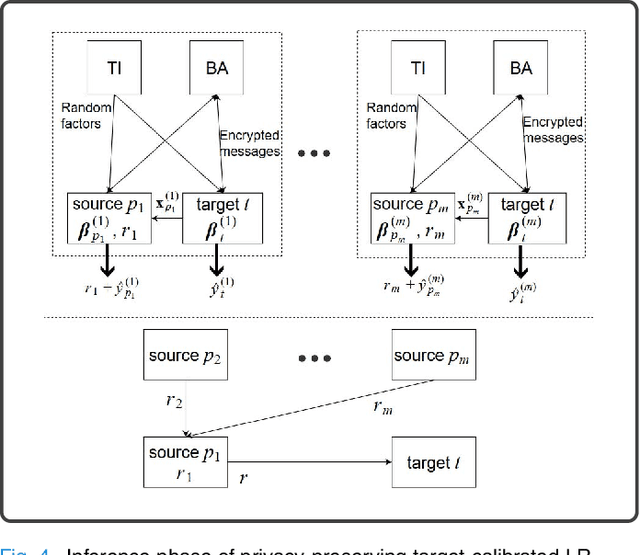
Machine learning (ML) is revolutionizing research and industry. Many ML applications rely on the use of large amounts of personal data for training and inference. Among the most intimate exploited data sources is electroencephalogram (EEG) data, a kind of data that is so rich with information that application developers can easily gain knowledge beyond the professed scope from unprotected EEG signals, including passwords, ATM PINs, and other intimate data. The challenge we address is how to engage in meaningful ML with EEG data while protecting the privacy of users. Hence, we propose cryptographic protocols based on Secure Multiparty Computation (SMC) to perform linear regression over EEG signals from many users in a fully privacy-preserving (PP) fashion, i.e.~such that each individual's EEG signals are not revealed to anyone else. To illustrate the potential of our secure framework, we show how it allows estimating the drowsiness of drivers from their EEG signals as would be possible in the unencrypted case, and at a very reasonable computational cost. Our solution is the first application of commodity-based SMC to EEG data, as well as the largest documented experiment of secret sharing based SMC in general, namely with 15 players involved in all the computations.
Privacy-Preserving Classification of Personal Text Messages with Secure Multi-Party Computation: An Application to Hate-Speech Detection
Jun 05, 2019
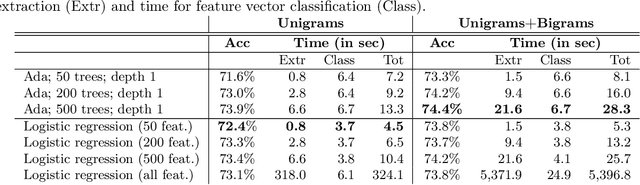

Classification of personal text messages has many useful applications in surveillance, e-commerce, and mental health care, to name a few. Giving applications access to personal texts can easily lead to (un)intentional privacy violations. We propose the first privacy-preserving solution for text classification that is provably secure. Our method, which is based on Secure Multiparty Computation (SMC), encompasses both feature extraction from texts, and subsequent classification with logistic regression and tree ensembles. We prove that when using our secure text classification method, the application does not learn anything about the text, and the author of the text does not learn anything about the text classification model used by the application beyond what is given by the classification result itself. We perform end-to-end experiments with an application for detecting hate speech against women and immigrants, demonstrating excellent runtime results without loss of accuracy.