 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunctional Tensors for Probabilistic Programming
Oct 23, 2019
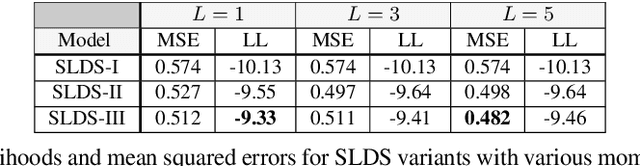
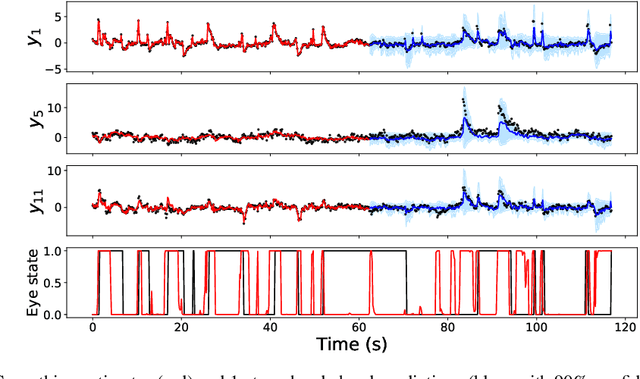
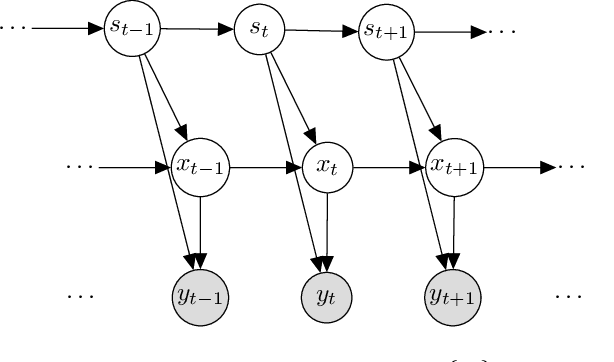
It is a significant challenge to design probabilistic programming systems that can accommodate a wide variety of inference strategies within a unified framework. Noting that the versatility of modern automatic differentiation frameworks is based in large part on the unifying concept of tensors, we describe a software abstraction --functional tensors-- that captures many of the benefits of tensors, while also being able to describe continuous probability distributions. Moreover, functional tensors are a natural candidate for generalized variable elimination and parallel-scan filtering algorithms that enable parallel exact inference for a large family of tractable modeling motifs. We demonstrate the versatility of functional tensors by integrating them into the modeling frontend and inference backend of the Pyro programming language. In experiments we show that the resulting framework enables a large variety of inference strategies, including those that mix exact and approximate inference.
Sparse Gaussian Process Regression Beyond Variational Inference
Oct 16, 2019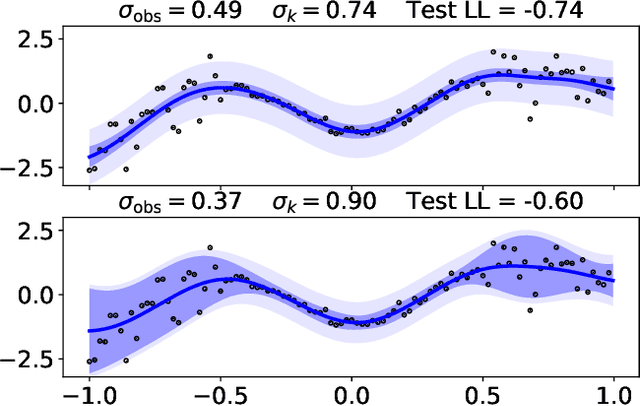
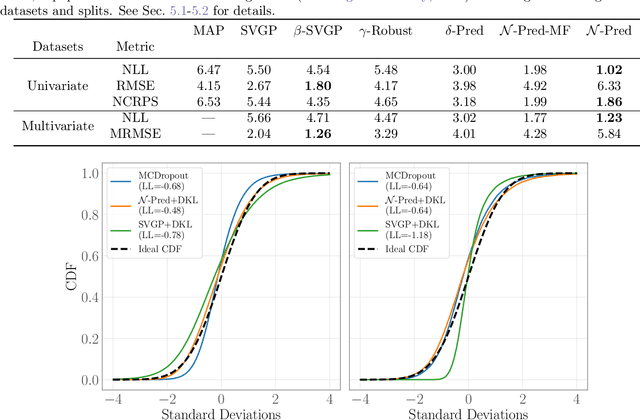
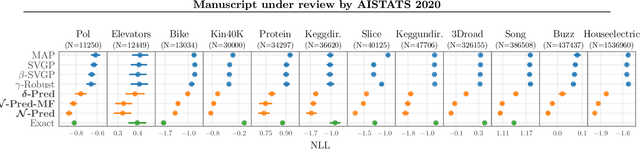

The combination of inducing point methods with stochastic variational inference has enabled approximate Gaussian Process (GP) inference on large datasets. Unfortunately, the resulting predictive distributions often exhibit substantially underestimated uncertainties. Worse still, in the regression case the predictive variance is typically dominated by observation noise, yielding uncertainty estimates that make little use of the input-dependent function uncertainty that makes GP priors attractive. In this work we propose a simple inference procedure that bypasses posterior approximations and instead directly targets the posterior predictive distribution. In an extensive empirical comparison with a number of alternative inference strategies on univariate and multivariate regression tasks, we find that the resulting predictive distributions exhibit significantly better calibrated uncertainties and higher log likelihoods--often by as much as half a nat or more per datapoint.
Neural Likelihoods for Multi-Output Gaussian Processes
May 31, 2019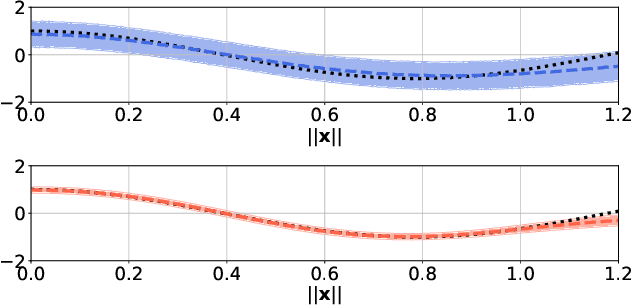
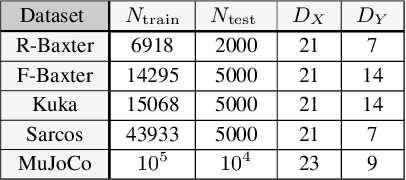
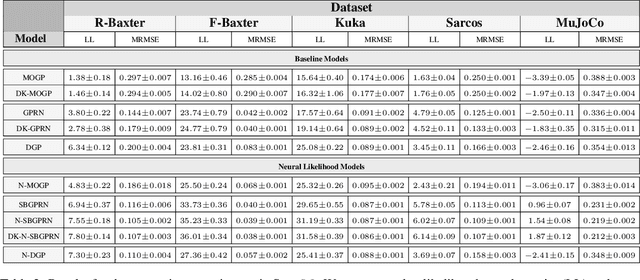
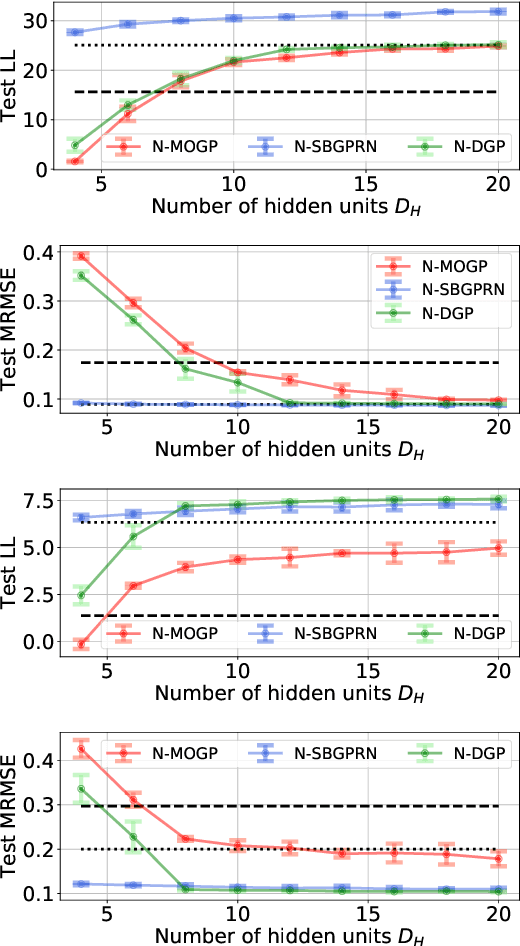
We construct flexible likelihoods for multi-output Gaussian process models that leverage neural networks as components. We make use of sparse variational inference methods to enable scalable approximate inference for the resulting class of models. An attractive feature of these models is that they can admit analytic predictive means even when the likelihood is non-linear and the predictive distributions are non-Gaussian. We validate the modeling potential of these models in a variety of experiments in both the supervised and unsupervised setting. We demonstrate that the flexibility of these `neural' likelihoods can improve prediction quality as compared to simpler Gaussian process models and that neural likelihoods can be readily combined with a variety of underlying Gaussian process models, including deep Gaussian processes.
Variational Estimators for Bayesian Optimal Experimental Design
Mar 13, 2019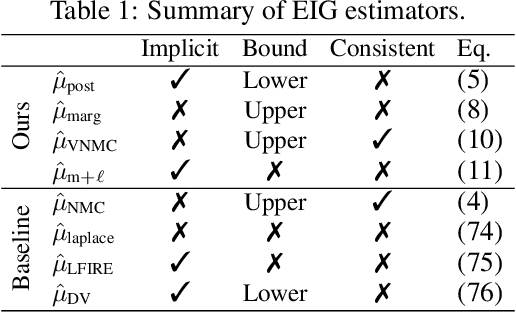
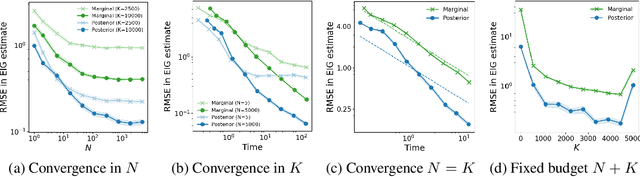
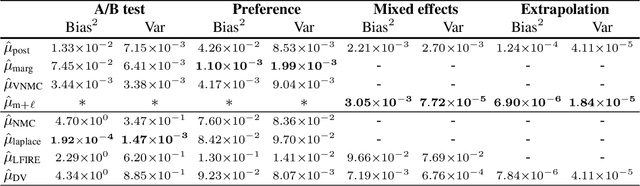
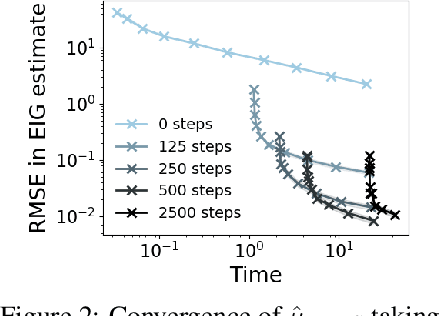
Bayesian optimal experimental design (BOED) is a principled framework for making efficient use of limited experimental resources. Unfortunately, its applicability is hampered by the difficulty of obtaining accurate estimates of the expected information gain (EIG) of an experiment. To address this, we introduce several classes of fast EIG estimators suited to the experiment design context by building on ideas from variational inference and mutual information estimation. We show theoretically and empirically that these estimators can provide significant gains in speed and accuracy over previous approaches. We demonstrate the practicality of our approach via a number of experiments, including an adaptive experiment with human participants.
Tensor Variable Elimination for Plated Factor Graphs
Feb 08, 2019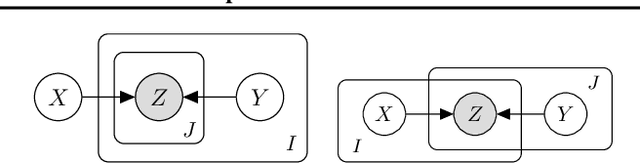
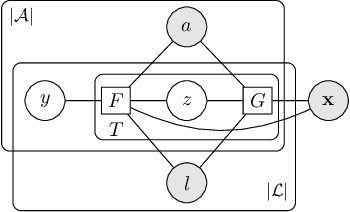
A wide class of machine learning algorithms can be reduced to variable elimination on factor graphs. While factor graphs provide a unifying notation for these algorithms, they do not provide a compact way to express repeated structure when compared to plate diagrams for directed graphical models. To exploit efficient tensor algebra in graphs with plates of variables, we generalize undirected factor graphs to plated factor graphs and variable elimination to a tensor variable elimination algorithm that operates directly on plated factor graphs. Moreover, we generalize complexity bounds based on treewidth and characterize the class of plated factor graphs for which inference is tractable. As an application, we integrate tensor variable elimination into the Pyro probabilistic programming language to enable exact inference in discrete latent variable models with repeated structure. We validate our methods with experiments on both directed and undirected graphical models, including applications to polyphonic music modeling, animal movement modeling, and latent sentiment analysis.
Closed Form Variational Objectives For Bayesian Neural Networks with a Single Hidden Layer
Nov 02, 2018


In this note we consider setups in which variational objectives for Bayesian neural networks can be computed in closed form. In particular we focus on single-layer networks in which the activation function is piecewise polynomial (e.g. ReLU). In this case we show that for a Normal likelihood and structured Normal variational distributions one can compute a variational lower bound in closed form. In addition we compute the predictive mean and variance in closed form. Finally, we also show how to compute approximate lower bounds for other likelihoods (e.g. softmax classification). In experiments we show how the resulting variational objectives can help improve training and provide fast test time predictions.
Pyro: Deep Universal Probabilistic Programming
Oct 18, 2018


Pyro is a probabilistic programming language built on Python as a platform for developing advanced probabilistic models in AI research. To scale to large datasets and high-dimensional models, Pyro uses stochastic variational inference algorithms and probability distributions built on top of PyTorch, a modern GPU-accelerated deep learning framework. To accommodate complex or model-specific algorithmic behavior, Pyro leverages Poutine, a library of composable building blocks for modifying the behavior of probabilistic programs.
Pathwise Derivatives Beyond the Reparameterization Trick
Jul 05, 2018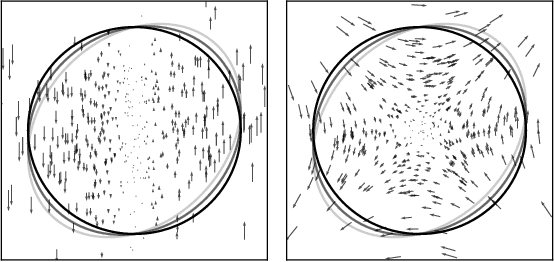
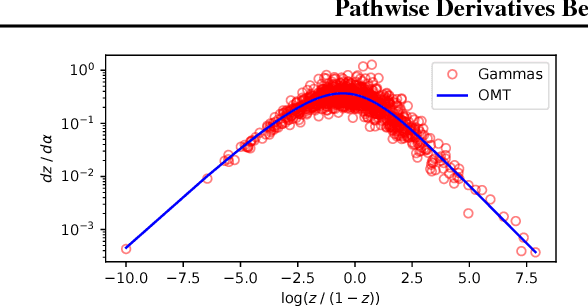
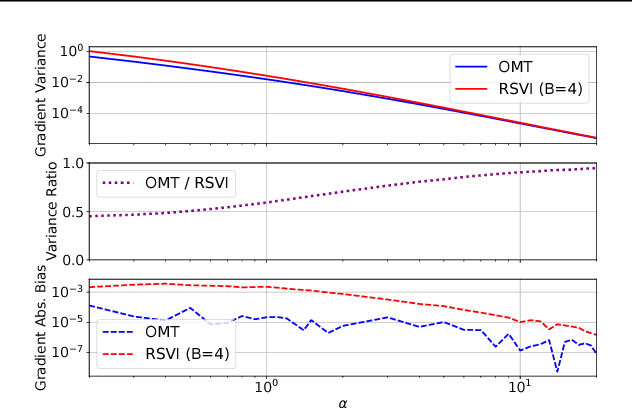
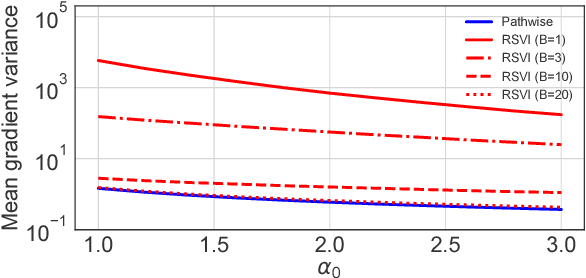
We observe that gradients computed via the reparameterization trick are in direct correspondence with solutions of the transport equation in the formalism of optimal transport. We use this perspective to compute (approximate) pathwise gradients for probability distributions not directly amenable to the reparameterization trick: Gamma, Beta, and Dirichlet. We further observe that when the reparameterization trick is applied to the Cholesky-factorized multivariate Normal distribution, the resulting gradients are suboptimal in the sense of optimal transport. We derive the optimal gradients and show that they have reduced variance in a Gaussian Process regression task. We demonstrate with a variety of synthetic experiments and stochastic variational inference tasks that our pathwise gradients are competitive with other methods.
Pathwise Derivatives for Multivariate Distributions
Jun 05, 2018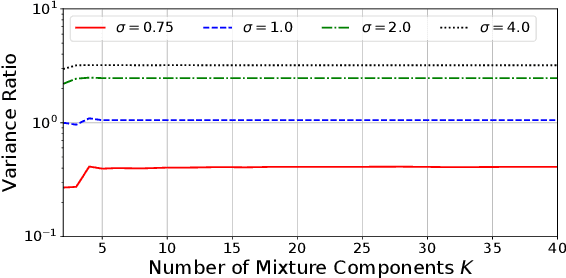
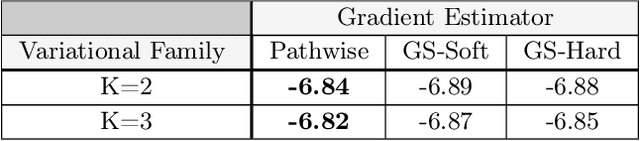
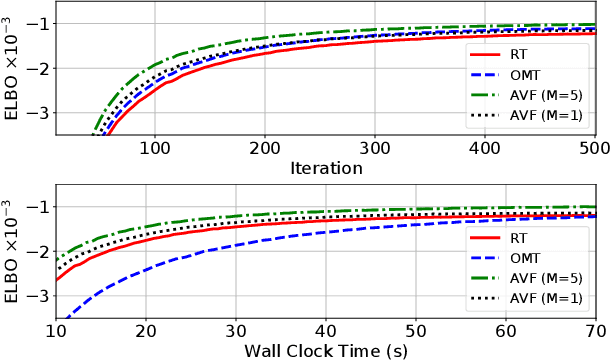
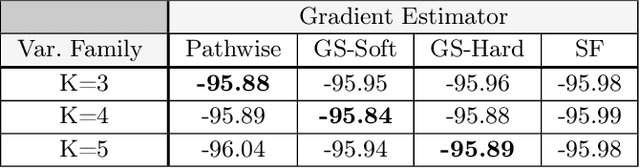
We exploit the link between the transport equation and derivatives of expectations to construct efficient pathwise gradient estimators for multivariate distributions. We focus on two main threads. First, we use null solutions of the transport equation to construct adaptive control variates that can be used to construct gradient estimators with reduced variance. Second, we consider the case of multivariate mixture distributions. In particular we show how to compute pathwise derivatives for mixtures of multivariate Normal distributions with arbitrary means and diagonal covariances. We demonstrate in a variety of experiments in the context of variational inference that our gradient estimators can outperform other methods, especially in high dimensions.