 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast mixing of Metropolized Hamiltonian Monte Carlo: Benefits of multi-step gradients
May 29, 2019
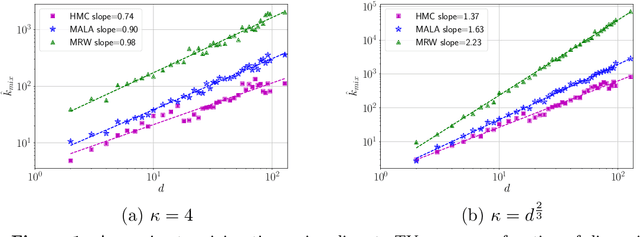


Hamiltonian Monte Carlo (HMC) is a state-of-the-art Markov chain Monte Carlo sampling algorithm for drawing samples from smooth probability densities over continuous spaces. We study the variant most widely used in practice, Metropolized HMC with the St\"{o}rmer-Verlet or leapfrog integrator, and make two primary contributions. First, we provide a non-asymptotic upper bound on the mixing time of the Metropolized HMC with explicit choices of stepsize and number of leapfrog steps. This bound gives a precise quantification of the faster convergence of Metropolized HMC relative to simpler MCMC algorithms such as the Metropolized random walk, or Metropolized Langevin algorithm. Second, we provide a general framework for sharpening mixing time bounds Markov chains initialized at a substantial distance from the target distribution over continuous spaces. We apply this sharpening device to the Metropolized random walk and Langevin algorithms, thereby obtaining improved mixing time bounds from a non-warm initial distribution.
Stochastic approximation with cone-contractive operators: Sharp $\ell_\infty$-bounds for $Q$-learning
May 15, 2019
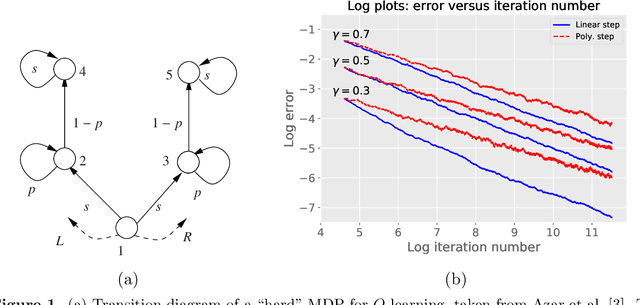
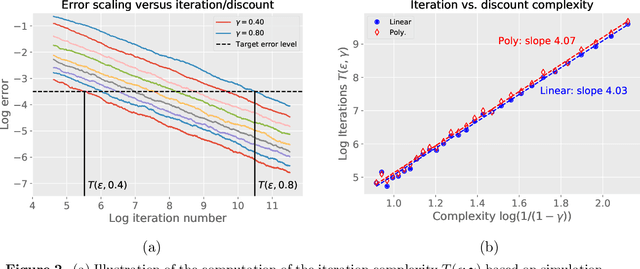
Motivated by the study of $Q$-learning algorithms in reinforcement learning, we study a class of stochastic approximation procedures based on operators that satisfy monotonicity and quasi-contractivity conditions with respect to an underlying cone. We prove a general sandwich relation on the iterate error at each time, and use it to derive non-asymptotic bounds on the error in terms of a cone-induced gauge norm. These results are derived within a deterministic framework, requiring no assumptions on the noise. We illustrate these general bounds in application to synchronous $Q$-learning for discounted Markov decision processes with discrete state-action spaces, in particular by deriving non-asymptotic bounds on the $\ell_\infty$-norm for a range of stepsizes. These results are the sharpest known to date, and we show via simulation that the dependence of our bounds cannot be improved in a worst-case sense. These results show that relative to a model-based $Q$-iteration, the $\ell_\infty$-based sample complexity of $Q$-learning is suboptimal in terms of the discount factor $\gamma$.
Challenges with EM in application to weakly identifiable mixture models
Feb 01, 2019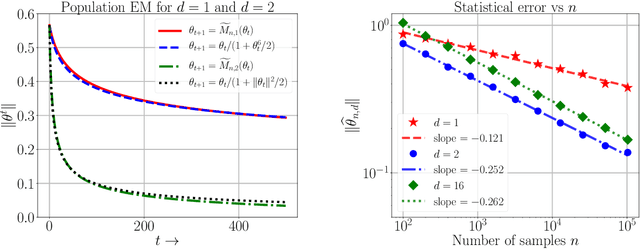

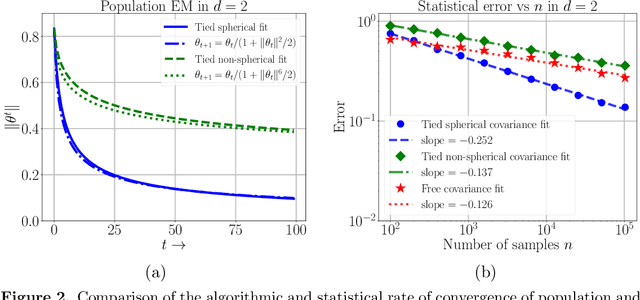
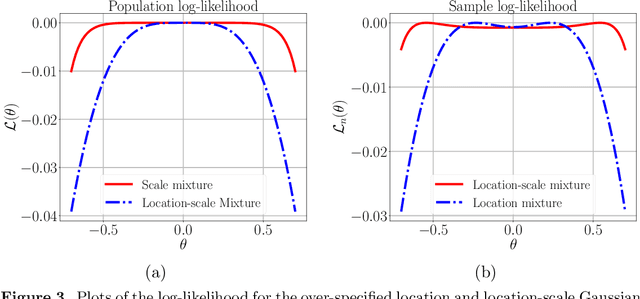
We study a class of weakly identifiable location-scale mixture models for which the maximum likelihood estimates based on $n$ i.i.d. samples are known to have lower accuracy than the classical $n^{- \frac{1}{2}}$ error. We investigate whether the Expectation-Maximization (EM) algorithm also converges slowly for these models. We first demonstrate via simulation studies a broad range of over-specified mixture models for which the EM algorithm converges very slowly, both in one and higher dimensions. We provide a complete analytical characterization of this behavior for fitting data generated from a multivariate standard normal distribution using two-component Gaussian mixture with varying location and scale parameters. Our results reveal distinct regimes in the convergence behavior of EM as a function of the dimension $d$. In the multivariate setting ($d \geq 2$), when the covariance matrix is constrained to a multiple of the identity matrix, the EM algorithm converges in order $(n/d)^{\frac{1}{2}}$ steps and returns estimates that are at a Euclidean distance of order ${(n/d)^{-\frac{1}{4}}}$ and ${ (n d)^{- \frac{1}{2}}}$ from the true location and scale parameter respectively. On the other hand, in the univariate setting ($d = 1$), the EM algorithm converges in order $n^{\frac{3}{4} }$ steps and returns estimates that are at a Euclidean distance of order ${ n^{- \frac{1}{8}}}$ and ${ n^{-\frac{1} {4}}}$ from the true location and scale parameter respectively. Establishing the slow rates in the univariate setting requires a novel localization argument with two stages, with each stage involving an epoch-based argument applied to a different surrogate EM operator at the population level. We also show multivariate ($d \geq 2$) examples, involving more general covariance matrices, that exhibit the same slow rates as the univariate case.
Derivative-Free Methods for Policy Optimization: Guarantees for Linear Quadratic Systems
Dec 20, 2018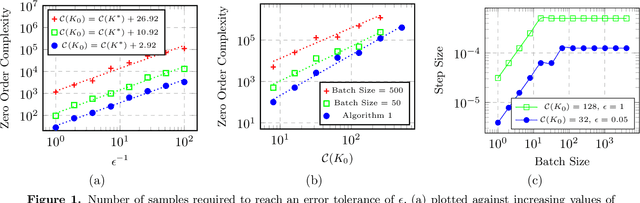
We study derivative-free methods for policy optimization over the class of linear policies. We focus on characterizing the convergence rate of these methods when applied to linear-quadratic systems, and study various settings of driving noise and reward feedback. We show that these methods provably converge to within any pre-specified tolerance of the optimal policy with a number of zero-order evaluations that is an explicit polynomial of the error tolerance, dimension, and curvature properties of the problem. Our analysis reveals some interesting differences between the settings of additive driving noise and random initialization, as well as the settings of one-point and two-point reward feedback. Our theory is corroborated by extensive simulations of derivative-free methods on these systems. Along the way, we derive convergence rates for stochastic zero-order optimization algorithms when applied to a certain class of non-convex problems.
Kernel Feature Selection via Conditional Covariance Minimization
Oct 20, 2018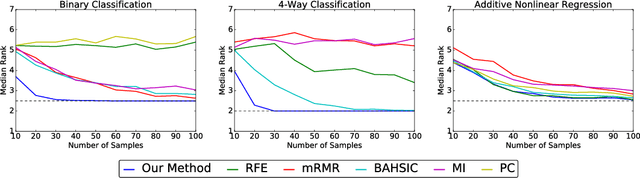

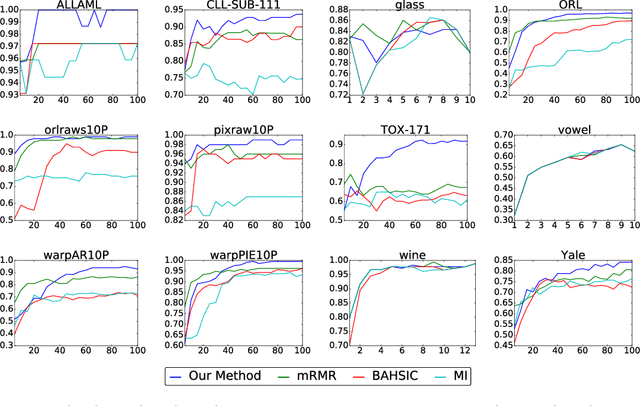
We propose a method for feature selection that employs kernel-based measures of independence to find a subset of covariates that is maximally predictive of the response. Building on past work in kernel dimension reduction, we show how to perform feature selection via a constrained optimization problem involving the trace of the conditional covariance operator. We prove various consistency results for this procedure, and also demonstrate that our method compares favorably with other state-of-the-art algorithms on a variety of synthetic and real data sets.
Singularity, Misspecification, and the Convergence Rate of EM
Oct 01, 2018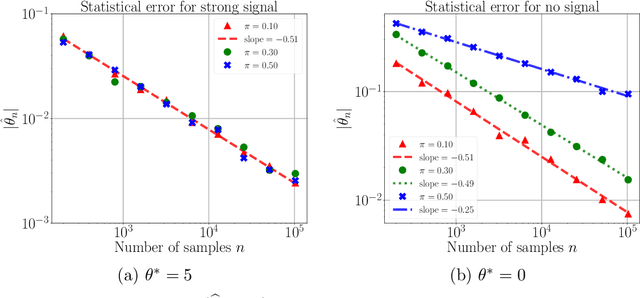
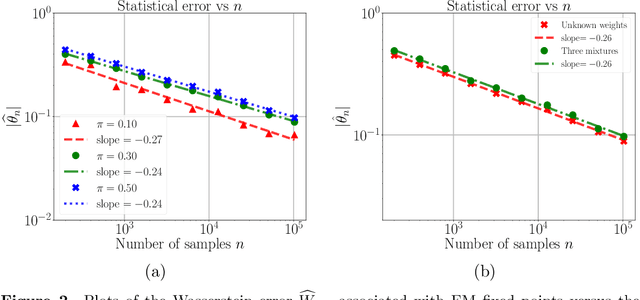
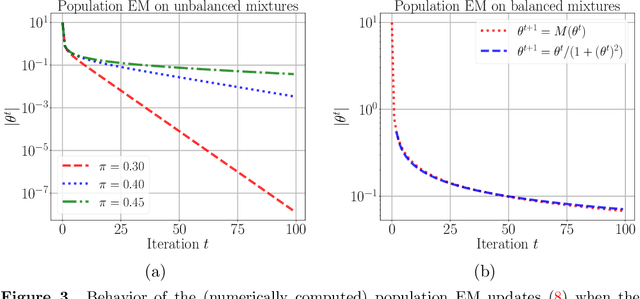
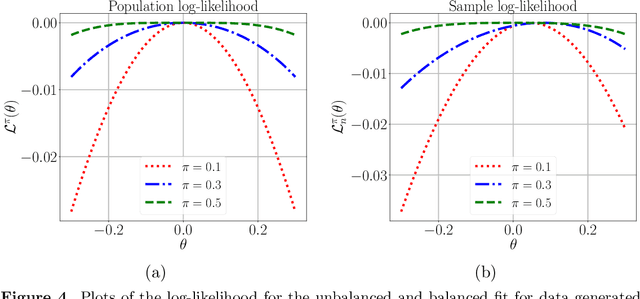
A line of recent work has characterized the behavior of the EM algorithm in favorable settings in which the population likelihood is locally strongly concave around its maximizing argument. Examples include suitably separated Gaussian mixture models and mixtures of linear regressions. We consider instead over-fitted settings in which the likelihood need not be strongly concave, or, equivalently, when the Fisher information matrix might be singular. In such settings, it is known that a global maximum of the MLE based on $n$ samples can have a non-standard $n^{-1/4}$ rate of convergence. How does the EM algorithm behave in such settings? Focusing on the simple setting of a two-component mixture fit to a multivariate Gaussian distribution, we study the behavior of the EM algorithm both when the mixture weights are different (unbalanced case), and are equal (balanced case). Our analysis reveals a sharp distinction between these cases: in the former, the EM algorithm converges geometrically to a point at Euclidean distance $O((d/n)^{1/2})$ from the true parameter, whereas in the latter case, the convergence rate is exponentially slower, and the fixed point has a much lower $O((d/n)^{1/4})$ accuracy. The slower convergence in the balanced over-fitted case arises from the singularity of the Fisher information matrix. Analysis of this singular case requires the introduction of some novel analysis techniques, in particular we make use of a careful form of localization in the associated empirical process, and develop a recursive argument to progressively sharpen the statistical rate.
L-Shapley and C-Shapley: Efficient Model Interpretation for Structured Data
Aug 08, 2018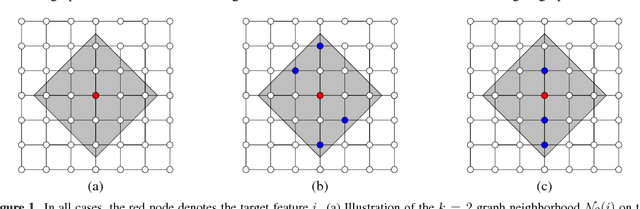

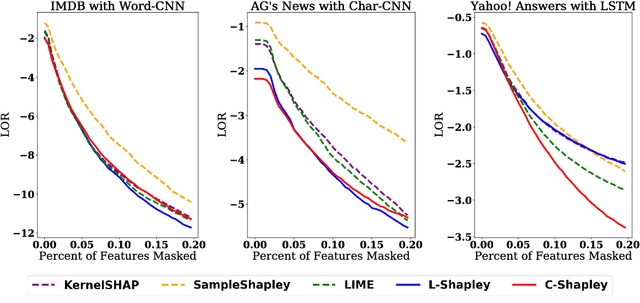

We study instancewise feature importance scoring as a method for model interpretation. Any such method yields, for each predicted instance, a vector of importance scores associated with the feature vector. Methods based on the Shapley score have been proposed as a fair way of computing feature attributions of this kind, but incur an exponential complexity in the number of features. This combinatorial explosion arises from the definition of the Shapley value and prevents these methods from being scalable to large data sets and complex models. We focus on settings in which the data have a graph structure, and the contribution of features to the target variable is well-approximated by a graph-structured factorization. In such settings, we develop two algorithms with linear complexity for instancewise feature importance scoring. We establish the relationship of our methods to the Shapley value and another closely related concept known as the Myerson value from cooperative game theory. We demonstrate on both language and image data that our algorithms compare favorably with other methods for model interpretation.
Fast MCMC sampling algorithms on polytopes
Jul 08, 2018

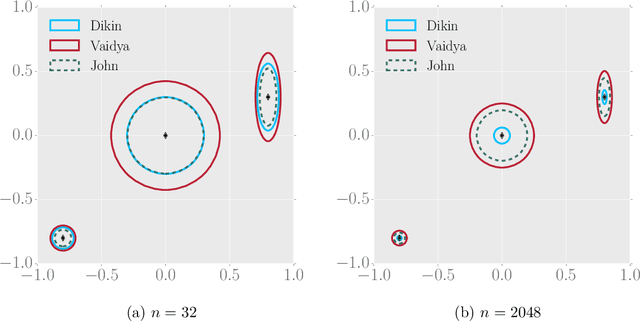
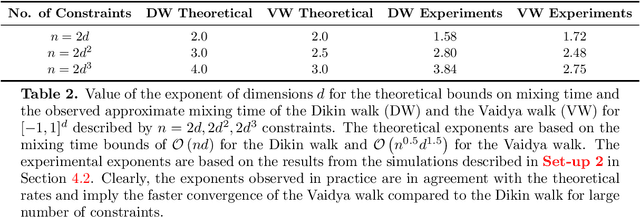
We propose and analyze two new MCMC sampling algorithms, the Vaidya walk and the John walk, for generating samples from the uniform distribution over a polytope. Both random walks are sampling algorithms derived from interior point methods. The former is based on volumetric-logarithmic barrier introduced by Vaidya whereas the latter uses John's ellipsoids. We show that the Vaidya walk mixes in significantly fewer steps than the logarithmic-barrier based Dikin walk studied in past work. For a polytope in $\mathbb{R}^d$ defined by $n >d$ linear constraints, we show that the mixing time from a warm start is bounded as $\mathcal{O}(n^{0.5}d^{1.5})$, compared to the $\mathcal{O}(nd)$ mixing time bound for the Dikin walk. The cost of each step of the Vaidya walk is of the same order as the Dikin walk, and at most twice as large in terms of constant pre-factors. For the John walk, we prove an $\mathcal{O}(d^{2.5}\cdot\log^4(n/d))$ bound on its mixing time and conjecture that an improved variant of it could achieve a mixing time of $\mathcal{O}(d^2\cdot\text{polylog}(n/d))$. Additionally, we propose variants of the Vaidya and John walks that mix in polynomial time from a deterministic starting point. We illustrate the speed-up of the Vaidya walk over the Dikin walk via several numerical examples.
Log-concave sampling: Metropolis-Hastings algorithms are fast!
Jul 08, 2018
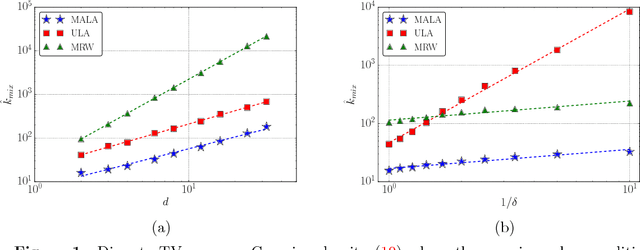
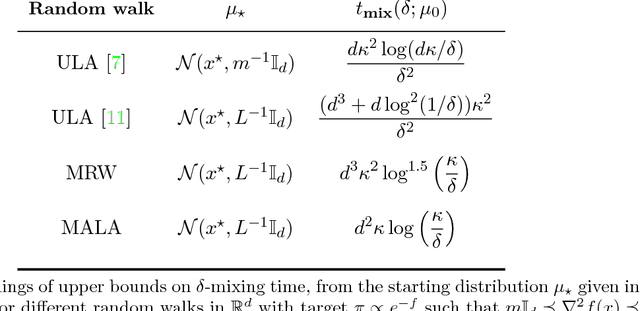
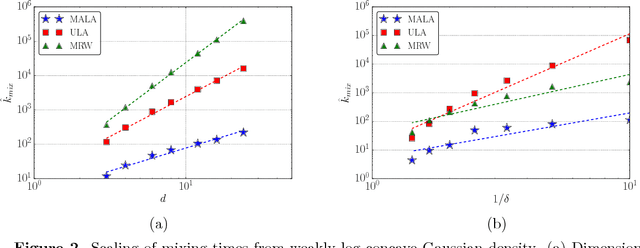
We consider the problem of sampling from a strongly log-concave density in $\mathbb{R}^d$, and prove a non-asymptotic upper bound on the mixing time of the Metropolis-adjusted Langevin algorithm (MALA). The method draws samples by running a Markov chain obtained from the discretization of an appropriate Langevin diffusion, combined with an accept-reject step to ensure the correct stationary distribution. Relative to known guarantees for the unadjusted Langevin algorithm (ULA), our bounds show that the use of an accept-reject step in MALA leads to an exponentially improved dependence on the error-tolerance. Concretely, in order to obtain samples with TV error at most $\delta$ for a density with condition number $\kappa$, we show that MALA requires $\mathcal{O} \big(\kappa d \log(1/\delta) \big)$ steps, as compared to the $\mathcal{O} \big(\kappa^2 d/\delta^2 \big)$ steps established in past work on ULA. We also demonstrate the gains of MALA over ULA for weakly log-concave densities. Furthermore, we derive mixing time bounds for a zeroth-order method Metropolized random walk (MRW) and show that it mixes $\mathcal{O}(\kappa d)$ slower than MALA. We provide numerical examples that support our theoretical findings, and demonstrate the potential gains of Metropolis-Hastings adjustment for Langevin-type algorithms.
Towards Optimal Estimation of Bivariate Isotonic Matrices with Unknown Permutations
Jun 25, 2018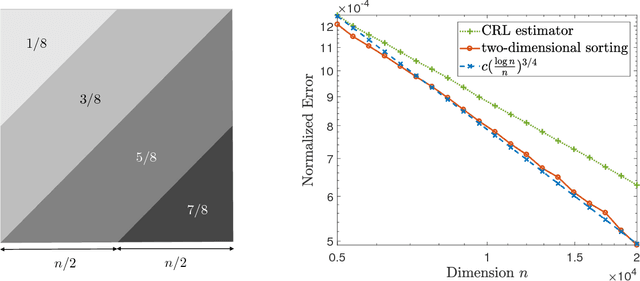
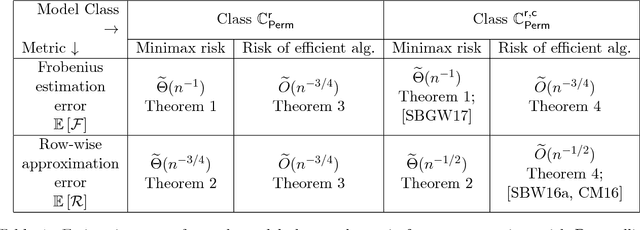
Many applications, including rank aggregation, crowd-labeling, and graphon estimation, can be modeled in terms of a bivariate isotonic matrix with unknown permutations acting on its rows and columns. We consider the problem of estimating such a matrix based on noisy observations of a subset of its entries, and design and analyze polynomial-time algorithms that improve upon the state of the art. In particular, our results imply that any such $n \times n$ matrix can be estimated efficiently in the normalized, squared Frobenius norm at rate $\widetilde{\mathcal O}(n^{-3/4})$, thus narrowing the gap between $\widetilde{\mathcal O}(n^{-1})$ and $\widetilde{\mathcal O}(n^{-1/2})$, hitherto the rates of the most statistically and computationally efficient methods, respectively. Additionally, our algorithms are minimax optimal in another natural metric that measures how well an estimate captures each row of the matrix. Along the way, we prove matching upper and lower bounds on the minimax radii of certain cone testing problems, which may be of independent interest.