 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKrylov-Bellman boosting: Super-linear policy evaluation in general state spaces
Oct 20, 2022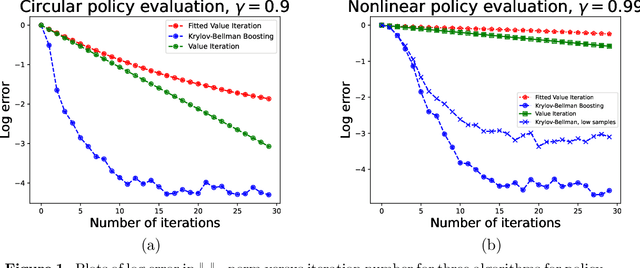
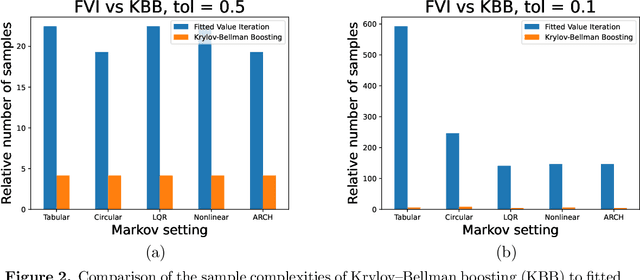
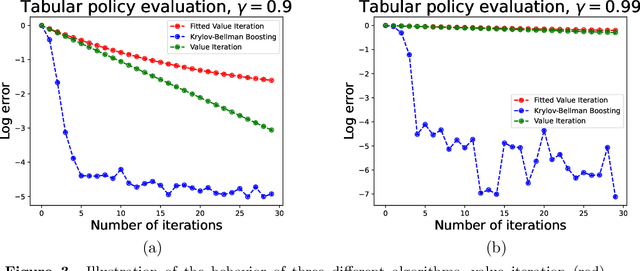
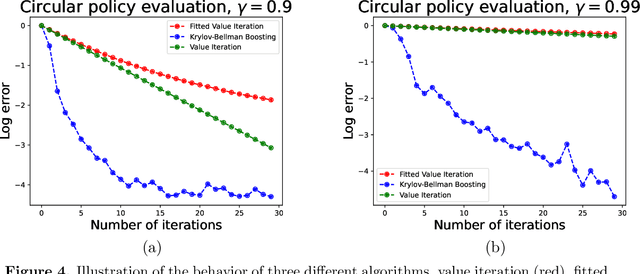
We present and analyze the Krylov-Bellman Boosting (KBB) algorithm for policy evaluation in general state spaces. It alternates between fitting the Bellman residual using non-parametric regression (as in boosting), and estimating the value function via the least-squares temporal difference (LSTD) procedure applied with a feature set that grows adaptively over time. By exploiting the connection to Krylov methods, we equip this method with two attractive guarantees. First, we provide a general convergence bound that allows for separate estimation errors in residual fitting and LSTD computation. Consistent with our numerical experiments, this bound shows that convergence rates depend on the restricted spectral structure, and are typically super-linear. Second, by combining this meta-result with sample-size dependent guarantees for residual fitting and LSTD computation, we obtain concrete statistical guarantees that depend on the sample size along with the complexity of the function class used to fit the residuals. We illustrate the behavior of the KBB algorithm for various types of policy evaluation problems, and typically find large reductions in sample complexity relative to the standard approach of fitted value iterationn.
QuTE: decentralized multiple testing on sensor networks with false discovery rate control
Oct 09, 2022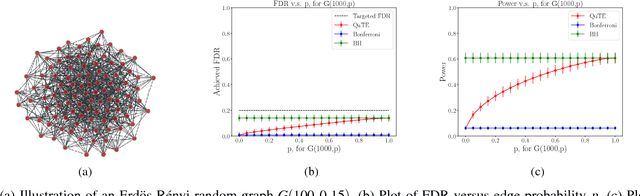
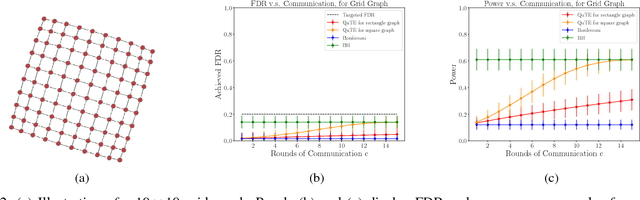
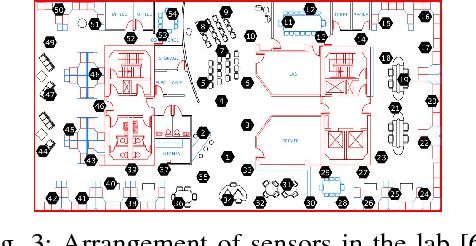
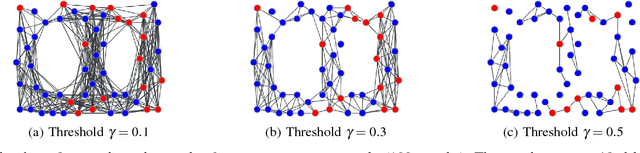
This paper designs methods for decentralized multiple hypothesis testing on graphs that are equipped with provable guarantees on the false discovery rate (FDR). We consider the setting where distinct agents reside on the nodes of an undirected graph, and each agent possesses p-values corresponding to one or more hypotheses local to its node. Each agent must individually decide whether to reject one or more of its local hypotheses by only communicating with its neighbors, with the joint aim that the global FDR over the entire graph must be controlled at a predefined level. We propose a simple decentralized family of Query-Test-Exchange (QuTE) algorithms and prove that they can control FDR under independence or positive dependence of the p-values. Our algorithm reduces to the Benjamini-Hochberg (BH) algorithm when after graph-diameter rounds of communication, and to the Bonferroni procedure when no communication has occurred or the graph is empty. To avoid communicating real-valued p-values, we develop a quantized BH procedure, and extend it to a quantized QuTE procedure. QuTE works seamlessly in streaming data settings, where anytime-valid p-values may be continually updated at each node. Last, QuTE is robust to arbitrary dropping of packets, or a graph that changes at every step, making it particularly suitable to mobile sensor networks involving drones or other multi-agent systems. We study the power of our procedure using a simulation suite of different levels of connectivity and communication on a variety of graph structures, and also provide an illustrative real-world example.
Off-policy estimation of linear functionals: Non-asymptotic theory for semi-parametric efficiency
Sep 26, 2022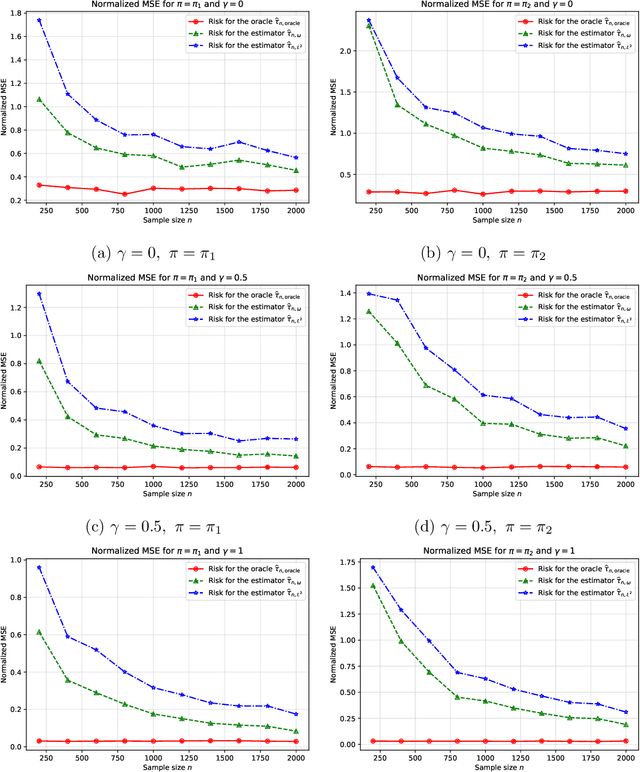
The problem of estimating a linear functional based on observational data is canonical in both the causal inference and bandit literatures. We analyze a broad class of two-stage procedures that first estimate the treatment effect function, and then use this quantity to estimate the linear functional. We prove non-asymptotic upper bounds on the mean-squared error of such procedures: these bounds reveal that in order to obtain non-asymptotically optimal procedures, the error in estimating the treatment effect should be minimized in a certain weighted $L^2$-norm. We analyze a two-stage procedure based on constrained regression in this weighted norm, and establish its instance-dependent optimality in finite samples via matching non-asymptotic local minimax lower bounds. These results show that the optimal non-asymptotic risk, in addition to depending on the asymptotically efficient variance, depends on the weighted norm distance between the true outcome function and its approximation by the richest function class supported by the sample size.
Stabilizing Q-learning with Linear Architectures for Provably Efficient Learning
Jun 01, 2022The $Q$-learning algorithm is a simple and widely-used stochastic approximation scheme for reinforcement learning, but the basic protocol can exhibit instability in conjunction with function approximation. Such instability can be observed even with linear function approximation. In practice, tools such as target networks and experience replay appear to be essential, but the individual contribution of each of these mechanisms is not well understood theoretically. This work proposes an exploration variant of the basic $Q$-learning protocol with linear function approximation. Our modular analysis illustrates the role played by each algorithmic tool that we adopt: a second order update rule, a set of target networks, and a mechanism akin to experience replay. Together, they enable state of the art regret bounds on linear MDPs while preserving the most prominent feature of the algorithm, namely a space complexity independent of the number of step elapsed. We show that the performance of the algorithm degrades very gracefully under a novel and more permissive notion of approximation error. The algorithm also exhibits a form of instance-dependence, in that its performance depends on the "effective" feature dimension.
Optimally tackling covariate shift in RKHS-based nonparametric regression
May 06, 2022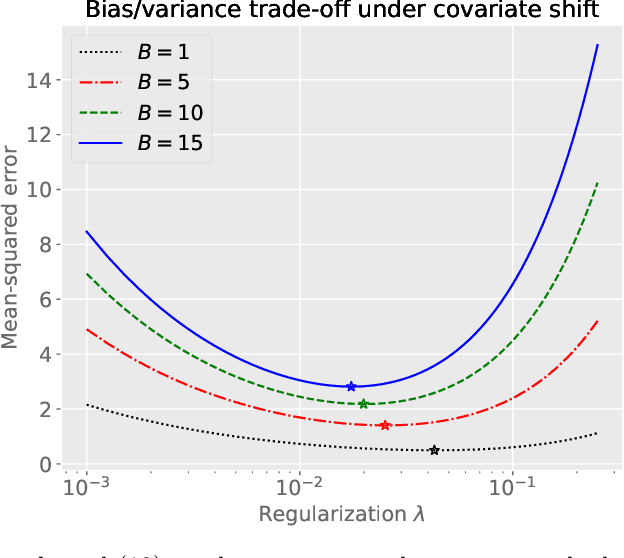
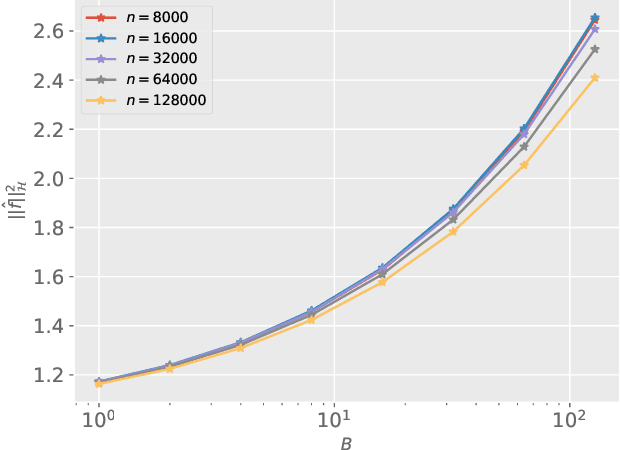
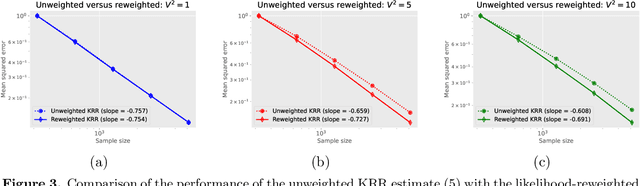
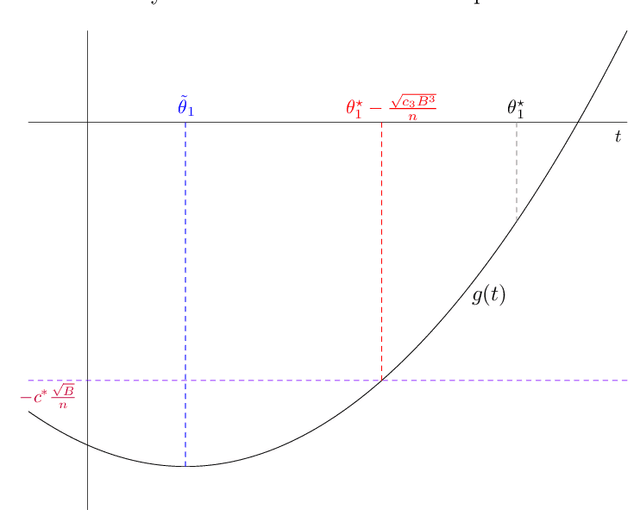
We study the covariate shift problem in the context of nonparametric regression over a reproducing kernel Hilbert space (RKHS). We focus on two natural families of covariate shift problems defined using the likelihood ratios between the source and target distributions. When the likelihood ratios are uniformly bounded, we prove that the kernel ridge regression (KRR) estimator with a carefully chosen regularization parameter is minimax rate-optimal (up to a log factor) for a large family of RKHSs with regular kernel eigenvalues. Interestingly, KRR does not require full knowledge of the likelihood ratio apart from an upper bound on it. In striking contrast to the standard statistical setting without covariate shift, we also demonstrate that a na\"\i ve estimator, which minimizes the empirical risk over the function class, is strictly suboptimal under covariate shift as compared to KRR. We then address the larger class of covariate shift problems where likelihood ratio is possibly unbounded yet has a finite second moment. Here, we show via careful simulations that KRR fails to attain the optimal rate. Instead, we propose a reweighted KRR estimator that weights samples based on a careful truncation of the likelihood ratios. Again, we are able to show that this estimator is minimax optimal, up to logarithmic factors.
Bellman Residual Orthogonalization for Offline Reinforcement Learning
Mar 24, 2022We introduce a new reinforcement learning principle that approximates the Bellman equations by enforcing their validity only along an user-defined space of test functions. Focusing on applications to model-free offline RL with function approximation, we exploit this principle to derive confidence intervals for off-policy evaluation, as well as to optimize over policies within a prescribed policy class. We prove an oracle inequality on our policy optimization procedure in terms of a trade-off between the value and uncertainty of an arbitrary comparator policy. Different choices of test function spaces allow us to tackle different problems within a common framework. We characterize the loss of efficiency in moving from on-policy to off-policy data using our procedures, and establish connections to concentrability coefficients studied in past work. We examine in depth the implementation of our methods with linear function approximation, and provide theoretical guarantees with polynomial-time implementations even when Bellman closure does not hold.
A new similarity measure for covariate shift with applications to nonparametric regression
Feb 06, 2022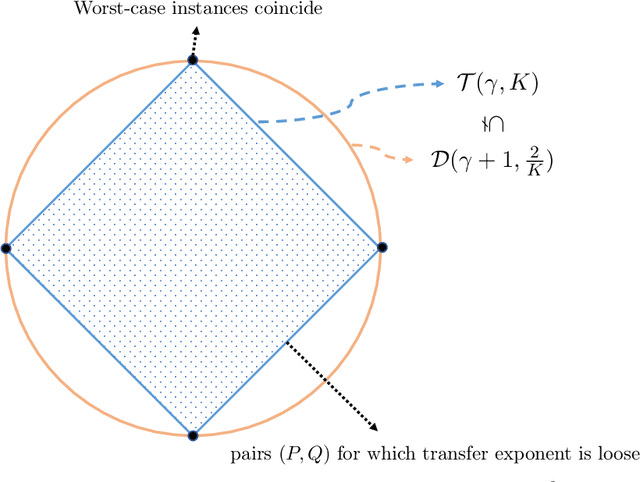
We study covariate shift in the context of nonparametric regression. We introduce a new measure of distribution mismatch between the source and target distributions that is based on the integrated ratio of probabilities of balls at a given radius. We use the scaling of this measure with respect to the radius to characterize the minimax rate of estimation over a family of H\"older continuous functions under covariate shift. In comparison to the recently proposed notion of transfer exponent, this measure leads to a sharper rate of convergence and is more fine-grained. We accompany our theory with concrete instances of covariate shift that illustrate this sharp difference.
Instance-Dependent Confidence and Early Stopping for Reinforcement Learning
Jan 21, 2022



Various algorithms for reinforcement learning (RL) exhibit dramatic variation in their convergence rates as a function of problem structure. Such problem-dependent behavior is not captured by worst-case analyses and has accordingly inspired a growing effort in obtaining instance-dependent guarantees and deriving instance-optimal algorithms for RL problems. This research has been carried out, however, primarily within the confines of theory, providing guarantees that explain \textit{ex post} the performance differences observed. A natural next step is to convert these theoretical guarantees into guidelines that are useful in practice. We address the problem of obtaining sharp instance-dependent confidence regions for the policy evaluation problem and the optimal value estimation problem of an MDP, given access to an instance-optimal algorithm. As a consequence, we propose a data-dependent stopping rule for instance-optimal algorithms. The proposed stopping rule adapts to the instance-specific difficulty of the problem and allows for early termination for problems with favorable structure.
Optimal variance-reduced stochastic approximation in Banach spaces
Jan 21, 2022We study the problem of estimating the fixed point of a contractive operator defined on a separable Banach space. Focusing on a stochastic query model that provides noisy evaluations of the operator, we analyze a variance-reduced stochastic approximation scheme, and establish non-asymptotic bounds for both the operator defect and the estimation error, measured in an arbitrary semi-norm. In contrast to worst-case guarantees, our bounds are instance-dependent, and achieve the local asymptotic minimax risk non-asymptotically. For linear operators, contractivity can be relaxed to multi-step contractivity, so that the theory can be applied to problems like average reward policy evaluation problem in reinforcement learning. We illustrate the theory via applications to stochastic shortest path problems, two-player zero-sum Markov games, as well as policy evaluation and $Q$-learning for tabular Markov decision processes.
Optimal and instance-dependent guarantees for Markovian linear stochastic approximation
Dec 23, 2021We study stochastic approximation procedures for approximately solving a $d$-dimensional linear fixed point equation based on observing a trajectory of length $n$ from an ergodic Markov chain. We first exhibit a non-asymptotic bound of the order $t_{\mathrm{mix}} \tfrac{d}{n}$ on the squared error of the last iterate of a standard scheme, where $t_{\mathrm{mix}}$ is a mixing time. We then prove a non-asymptotic instance-dependent bound on a suitably averaged sequence of iterates, with a leading term that matches the local asymptotic minimax limit, including sharp dependence on the parameters $(d, t_{\mathrm{mix}})$ in the higher order terms. We complement these upper bounds with a non-asymptotic minimax lower bound that establishes the instance-optimality of the averaged SA estimator. We derive corollaries of these results for policy evaluation with Markov noise -- covering the TD($\lambda$) family of algorithms for all $\lambda \in [0, 1)$ -- and linear autoregressive models. Our instance-dependent characterizations open the door to the design of fine-grained model selection procedures for hyperparameter tuning (e.g., choosing the value of $\lambda$ when running the TD($\lambda$) algorithm).