 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Scalable Bayesian Deep Learning Methods for Robust Computer Vision
Jun 04, 2019
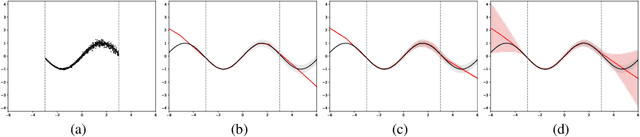
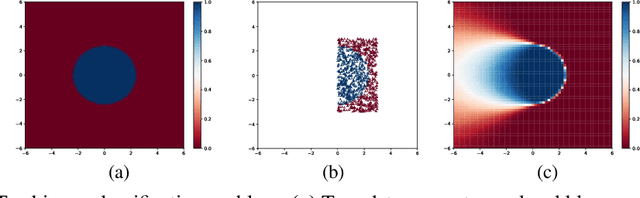
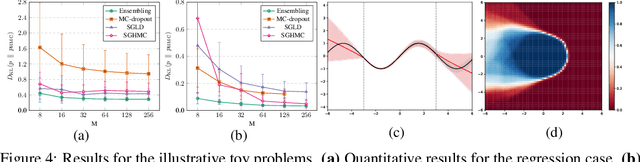
While Deep Neural Networks (DNNs) have become the go-to approach in computer vision, the vast majority of these models fail to properly capture the uncertainty inherent in their predictions. Estimating this predictive uncertainty can be crucial, for instance in automotive applications. In Bayesian deep learning, predictive uncertainty is often decomposed into the distinct types of aleatoric and epistemic uncertainty. The former can be estimated by letting a DNN output the parameters of a probability distribution. Epistemic uncertainty estimation is a more challenging problem, and while different scalable methods recently have emerged, no comprehensive comparison has been performed in a real-world setting. We therefore accept this task and propose an evaluation framework for predictive uncertainty estimation that is specifically designed to test the robustness required in real-world computer vision applications. Using the proposed framework, we perform an extensive comparison of the popular ensembling and MC-dropout methods on the tasks of depth completion and street-scene semantic segmentation. Our comparison suggests that ensembling consistently provides more reliable uncertainty estimates. Code is available at https://github.com/fregu856/evaluating_bdl.
Discriminative Online Learning for Fast Video Object Segmentation
Apr 18, 2019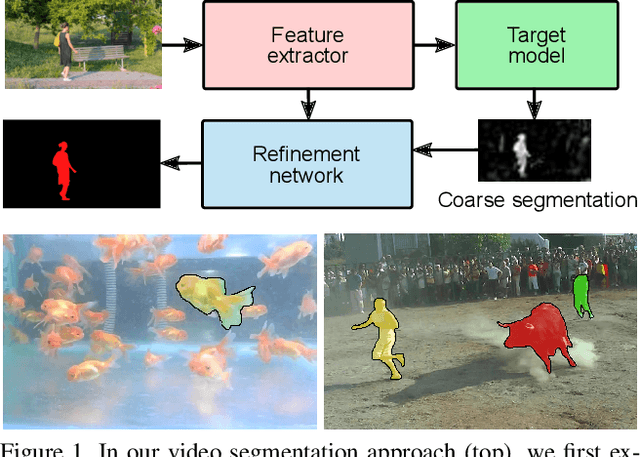

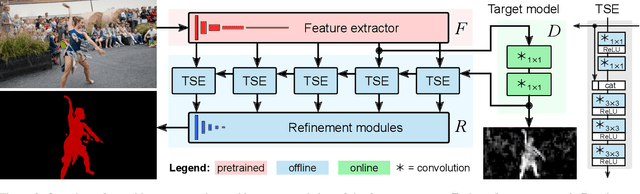
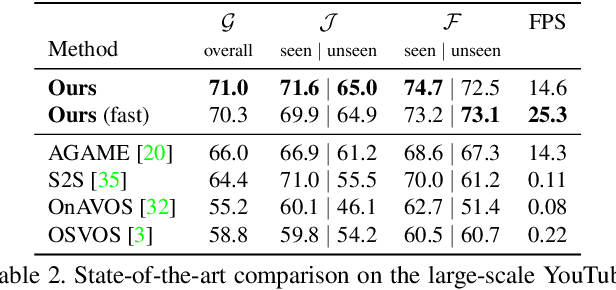
We address the highly challenging problem of video object segmentation. Given only the initial mask, the task is to segment the target in the subsequent frames. In order to effectively handle appearance changes and similar background objects, a robust representation of the target is required. Previous approaches either rely on fine-tuning a segmentation network on the first frame, or employ generative appearance models. Although partially successful, these methods often suffer from impractically low frame rates or unsatisfactory robustness. We propose a novel approach, based on a dedicated target appearance model that is exclusively learned online to discriminate between the target and background image regions. Importantly, we design a specialized loss and customized optimization techniques to enable highly efficient online training. Our light-weight target model is integrated into a carefully designed segmentation network, trained offline to enhance the predictions generated by the target model. Extensive experiments are performed on three datasets. Our approach achieves an overall score of over 70 on YouTube-VOS, while operating at 25 frames per second.
Learning Discriminative Model Prediction for Tracking
Apr 15, 2019

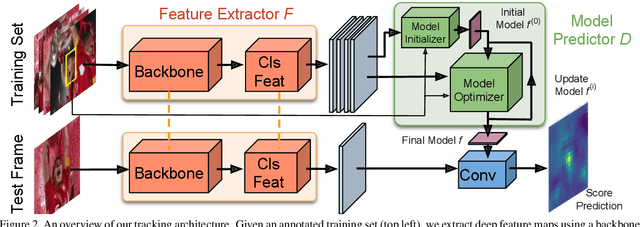
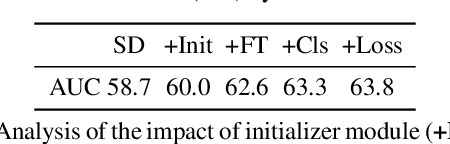
The current strive towards end-to-end trainable computer vision systems imposes major challenges for the task of visual tracking. In contrast to most other vision problems, tracking requires the learning of a robust target-specific appearance model online, during the inference stage. To be end-to-end trainable, the online learning of the target model thus needs to be embedded in the tracking architecture itself. Due to these difficulties, the popular Siamese paradigm simply predicts a target feature template. However, such a model possesses limited discriminative power due to its inability of integrating background information. We develop an end-to-end tracking architecture, capable of fully exploiting both target and background appearance information for target model prediction. Our architecture is derived from a discriminative learning loss by designing a dedicated optimization process that is capable of predicting a powerful model in only a few iterations. Furthermore, our approach is able to learn key aspects of the discriminative loss itself. The proposed tracker sets a new state-of-the-art on 6 tracking benchmarks, achieving an EAO score of 0.440 on VOT2018, while running at over 40 FPS.
A Generative Appearance Model for End-to-end Video Object Segmentation
Dec 07, 2018
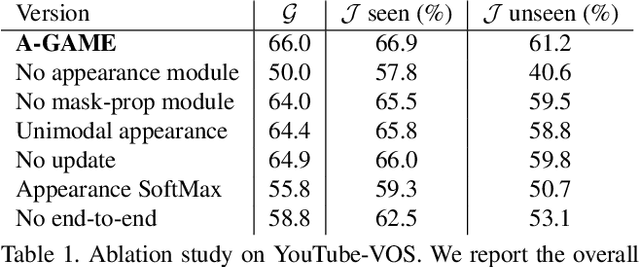
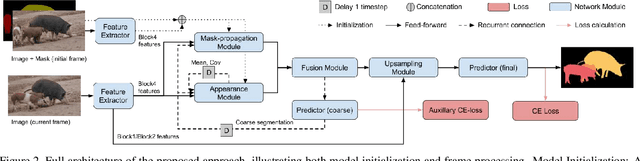
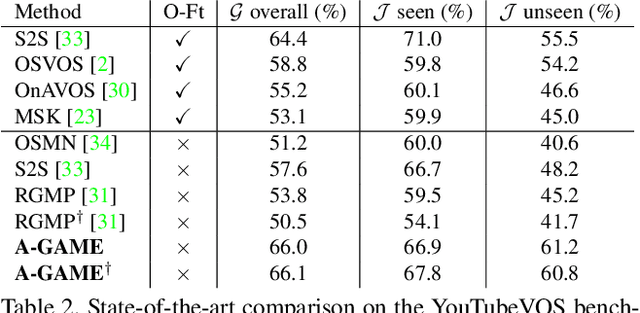
One of the fundamental challenges in video object segmentation is to find an effective representation of the target and background appearance. The best performing approaches resort to extensive fine-tuning of a convolutional neural network for this purpose. Besides being prohibitively expensive, this strategy cannot be truly trained end-to-end since the online fine-tuning procedure is not integrated into the offline training of the network. To address these issues, we propose a network architecture that learns a powerful representation of the target and background appearance in a single forward pass. The introduced appearance module learns a probabilistic generative model of target and background feature distributions. Given a new image, it predicts the posterior class probabilities, providing a highly discriminative cue, which is processed in later network modules. Both the learning and prediction stages of our appearance module are fully differentiable, enabling true end-to-end training of the entire segmentation pipeline. Comprehensive experiments demonstrate the effectiveness of the proposed approach on three video object segmentation benchmarks. We close the gap to approaches based on online fine-tuning on DAVIS17, while operating at 15 FPS on a single GPU. Furthermore, our method outperforms all published approaches on the large-scale YouTube-VOS dataset.
ATOM: Accurate Tracking by Overlap Maximization
Nov 19, 2018
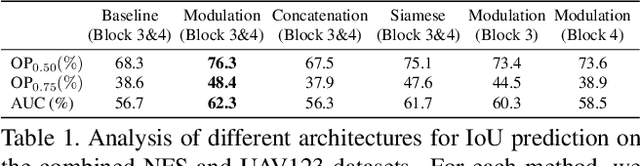
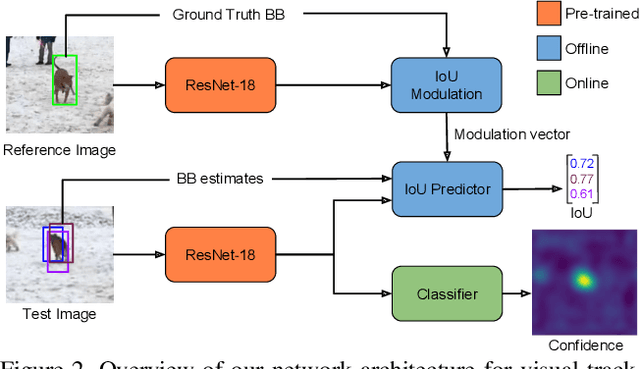
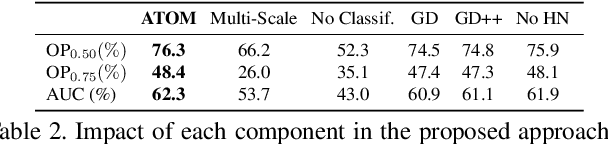
While recent years have witnessed astonishing improvements in visual tracking robustness, the advancements in tracking accuracy have been severely limited. As the focus has been directed towards the development of powerful classifiers, the problem of accurate target state estimation has been largely overlooked. Instead, the majority of methods resort to simple multi-scale search in order to estimate the target bounding box. We argue that this approach is fundamentally limited as target estimation is a complex task, requiring high-level knowledge about the object. We thus address the problem of target state estimation in tracking. We propose a novel tracking architecture consisting of dedicated target estimation and classification components. Due to the complex nature of target estimation, we propose a component that can be entirely trained offline on large-scale datasets. Our target estimation component is trained to predict the overlap between the target object and an estimated bounding box. By carefully integrating target-specific information in the prediction, our approach achieves previously unseen bounding box accuracy. Furthermore, we integrate a classification component that is trained online to guarantee high discriminative power in the presence of distractors. Our final tracking framework, comprised of a unified multi-task architecture, sets a new state-of-the-art on four challenging benchmarks. On the large-scale TrackingNet dataset, our tracker ATOM achieves a relative gain of 15%, while running at over 30 FPS.
Density Adaptive Point Set Registration
Oct 23, 2018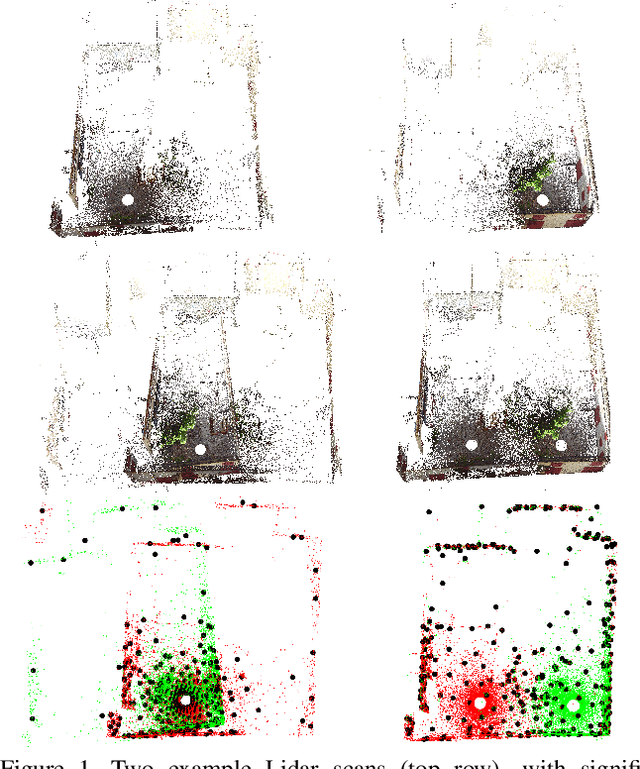
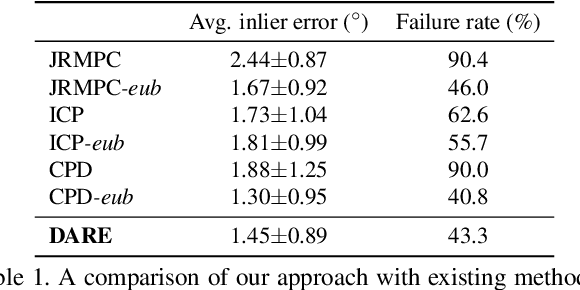
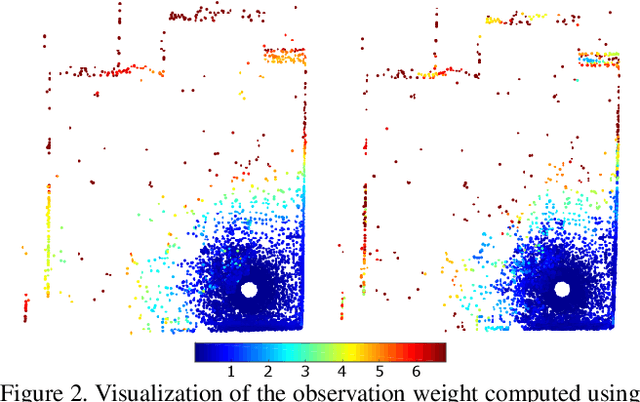
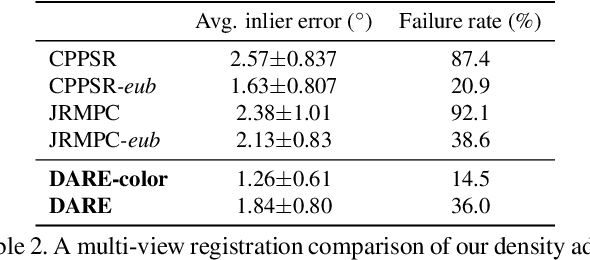
Probabilistic methods for point set registration have demonstrated competitive results in recent years. These techniques estimate a probability distribution model of the point clouds. While such a representation has shown promise, it is highly sensitive to variations in the density of 3D points. This fundamental problem is primarily caused by changes in the sensor location across point sets. We revisit the foundations of the probabilistic registration paradigm. Contrary to previous works, we model the underlying structure of the scene as a latent probability distribution, and thereby induce invariance to point set density changes. Both the probabilistic model of the scene and the registration parameters are inferred by minimizing the Kullback-Leibler divergence in an Expectation Maximization based framework. Our density-adaptive registration successfully handles severe density variations commonly encountered in terrestrial Lidar applications. We perform extensive experiments on several challenging real-world Lidar datasets. The results demonstrate that our approach outperforms state-of-the-art probabilistic methods for multi-view registration, without the need of re-sampling. Code is available at https://github.com/felja633/DARE.
* CVPR 2018 (Oral)
Synthetic data generation for end-to-end thermal infrared tracking
Sep 26, 2018

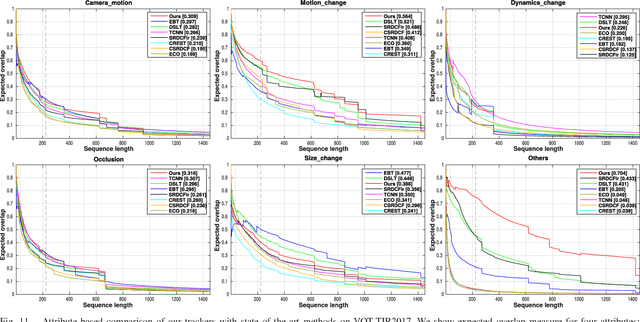
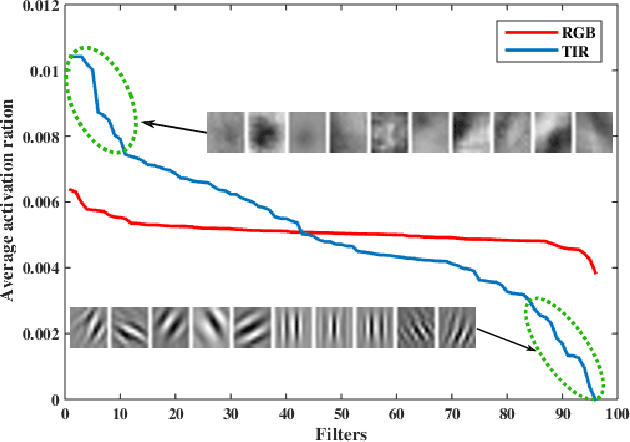
The usage of both off-the-shelf and end-to-end trained deep networks have significantly improved performance of visual tracking on RGB videos. However, the lack of large labeled datasets hampers the usage of convolutional neural networks for tracking in thermal infrared (TIR) images. Therefore, most state of the art methods on tracking for TIR data are still based on handcrafted features. To address this problem, we propose to use image-to-image translation models. These models allow us to translate the abundantly available labeled RGB data to synthetic TIR data. We explore both the usage of paired and unpaired image translation models for this purpose. These methods provide us with a large labeled dataset of synthetic TIR sequences, on which we can train end-to-end optimal features for tracking. To the best of our knowledge we are the first to train end-to-end features for TIR tracking. We perform extensive experiments on VOT-TIR2017 dataset. We show that a network trained on a large dataset of synthetic TIR data obtains better performance than one trained on the available real TIR data. Combining both data sources leads to further improvement. In addition, when we combine the network with motion features we outperform the state of the art with a relative gain of over 10%, clearly showing the efficiency of using synthetic data to train end-to-end TIR trackers.
Unveiling the Power of Deep Tracking
Apr 18, 2018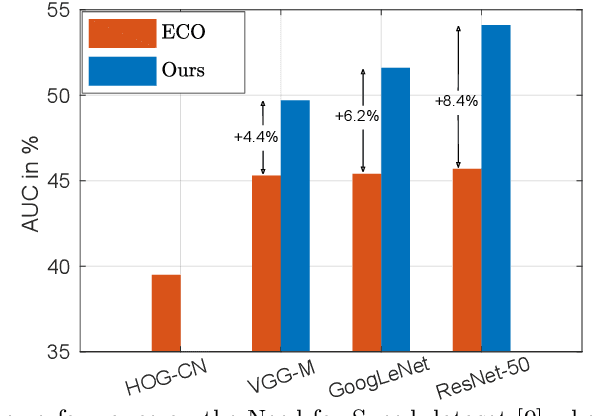

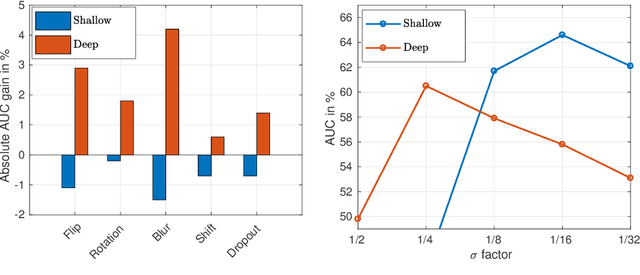
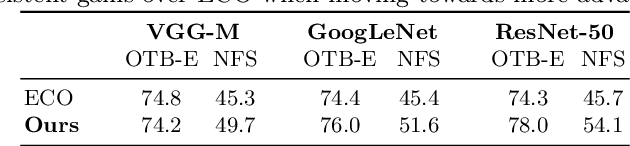
In the field of generic object tracking numerous attempts have been made to exploit deep features. Despite all expectations, deep trackers are yet to reach an outstanding level of performance compared to methods solely based on handcrafted features. In this paper, we investigate this key issue and propose an approach to unlock the true potential of deep features for tracking. We systematically study the characteristics of both deep and shallow features, and their relation to tracking accuracy and robustness. We identify the limited data and low spatial resolution as the main challenges, and propose strategies to counter these issues when integrating deep features for tracking. Furthermore, we propose a novel adaptive fusion approach that leverages the complementary properties of deep and shallow features to improve both robustness and accuracy. Extensive experiments are performed on four challenging datasets. On VOT2017, our approach significantly outperforms the top performing tracker from the challenge with a relative gain of 17% in EAO.
DCCO: Towards Deformable Continuous Convolution Operators
Jun 09, 2017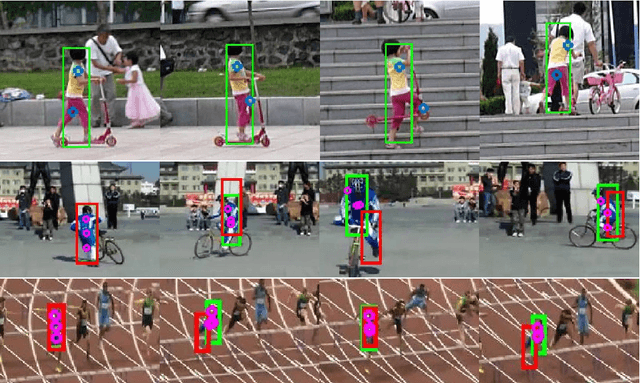


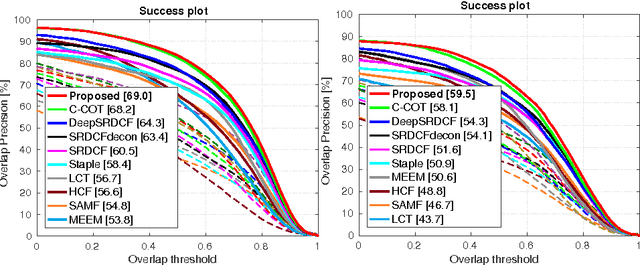
Discriminative Correlation Filter (DCF) based methods have shown competitive performance on tracking benchmarks in recent years. Generally, DCF based trackers learn a rigid appearance model of the target. However, this reliance on a single rigid appearance model is insufficient in situations where the target undergoes non-rigid transformations. In this paper, we propose a unified formulation for learning a deformable convolution filter. In our framework, the deformable filter is represented as a linear combination of sub-filters. Both the sub-filter coefficients and their relative locations are inferred jointly in our formulation. Experiments are performed on three challenging tracking benchmarks: OTB- 2015, TempleColor and VOT2016. Our approach improves the baseline method, leading to performance comparable to state-of-the-art.
Deep Projective 3D Semantic Segmentation
May 09, 2017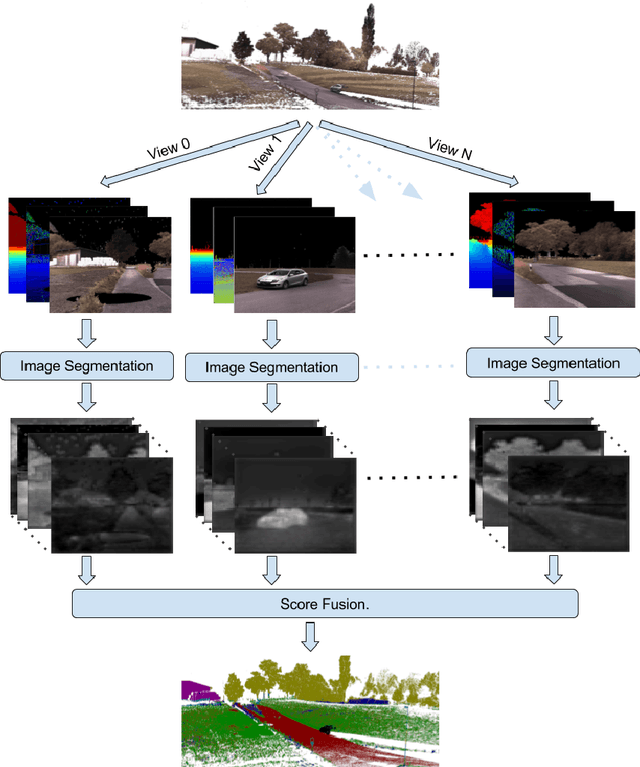


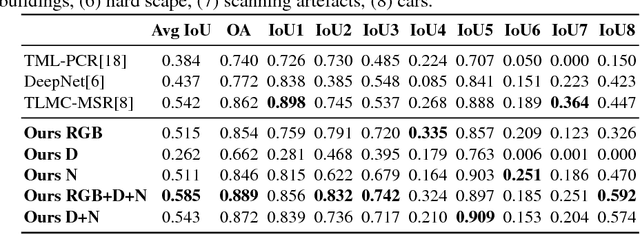
Semantic segmentation of 3D point clouds is a challenging problem with numerous real-world applications. While deep learning has revolutionized the field of image semantic segmentation, its impact on point cloud data has been limited so far. Recent attempts, based on 3D deep learning approaches (3D-CNNs), have achieved below-expected results. Such methods require voxelizations of the underlying point cloud data, leading to decreased spatial resolution and increased memory consumption. Additionally, 3D-CNNs greatly suffer from the limited availability of annotated datasets. In this paper, we propose an alternative framework that avoids the limitations of 3D-CNNs. Instead of directly solving the problem in 3D, we first project the point cloud onto a set of synthetic 2D-images. These images are then used as input to a 2D-CNN, designed for semantic segmentation. Finally, the obtained prediction scores are re-projected to the point cloud to obtain the segmentation results. We further investigate the impact of multiple modalities, such as color, depth and surface normals, in a multi-stream network architecture. Experiments are performed on the recent Semantic3D dataset. Our approach sets a new state-of-the-art by achieving a relative gain of 7.9 %, compared to the previous best approach.