 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Inference with A Chinese Entailment Graph
Mar 11, 2022
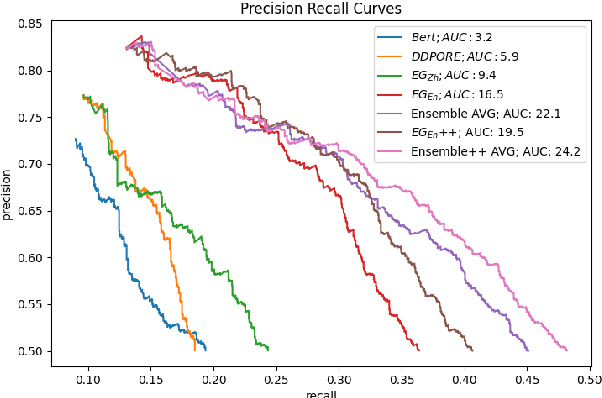
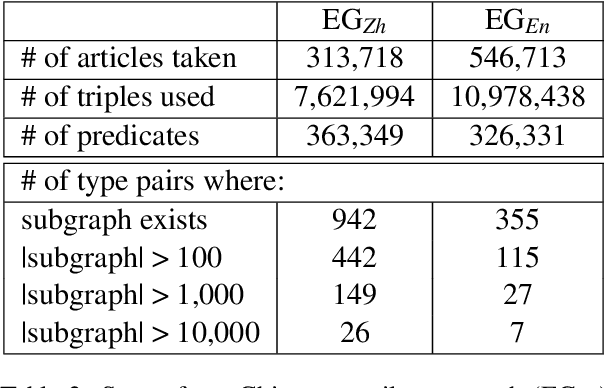
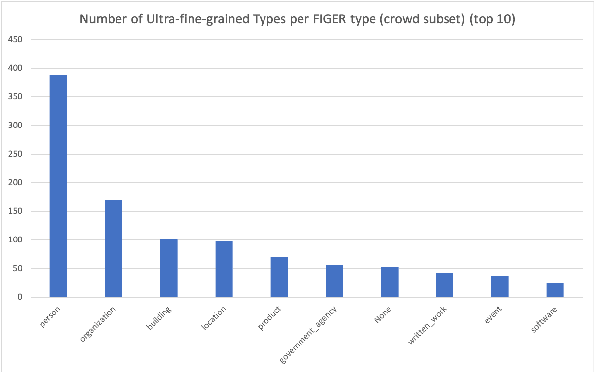
Predicate entailment detection is a crucial task for question-answering from text, where previous work has explored unsupervised learning of entailment graphs from typed open relation triples. In this paper, we present the first pipeline for building Chinese entailment graphs, which involves a novel high-recall open relation extraction (ORE) method and the first Chinese fine-grained entity typing dataset under the FIGER type ontology. Through experiments on the Levy-Holt dataset, we verify the strength of our Chinese entailment graph, and reveal the cross-lingual complementarity: on the parallel Levy-Holt dataset, an ensemble of Chinese and English entailment graphs outperforms both monolingual graphs, and raises unsupervised SOTA by 4.7 AUC points.
Cross-lingual Intermediate Fine-tuning improves Dialogue State Tracking
Sep 28, 2021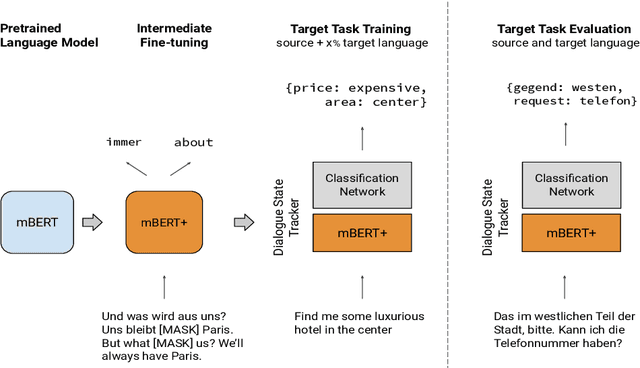

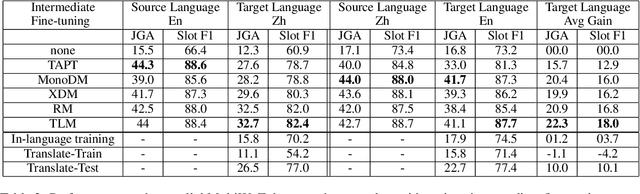
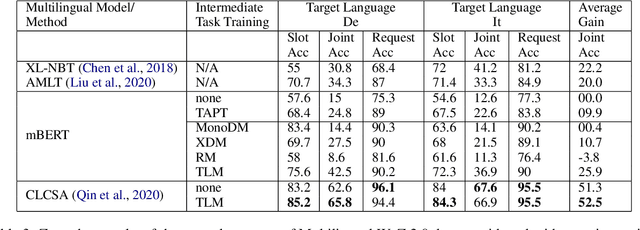
Recent progress in task-oriented neural dialogue systems is largely focused on a handful of languages, as annotation of training data is tedious and expensive. Machine translation has been used to make systems multilingual, but this can introduce a pipeline of errors. Another promising solution is using cross-lingual transfer learning through pretrained multilingual models. Existing methods train multilingual models with additional code-mixed task data or refine the cross-lingual representations through parallel ontologies. In this work, we enhance the transfer learning process by intermediate fine-tuning of pretrained multilingual models, where the multilingual models are fine-tuned with different but related data and/or tasks. Specifically, we use parallel and conversational movie subtitles datasets to design cross-lingual intermediate tasks suitable for downstream dialogue tasks. We use only 200K lines of parallel data for intermediate fine-tuning which is already available for 1782 language pairs. We test our approach on the cross-lingual dialogue state tracking task for the parallel MultiWoZ (English -> Chinese, Chinese -> English) and Multilingual WoZ (English -> German, English -> Italian) datasets. We achieve impressive improvements (> 20% on joint goal accuracy) on the parallel MultiWoZ dataset and the Multilingual WoZ dataset over the vanilla baseline with only 10% of the target language task data and zero-shot setup respectively.
Cross-linguistically Consistent Semantic and Syntactic Annotation of Child-directed Speech
Sep 22, 2021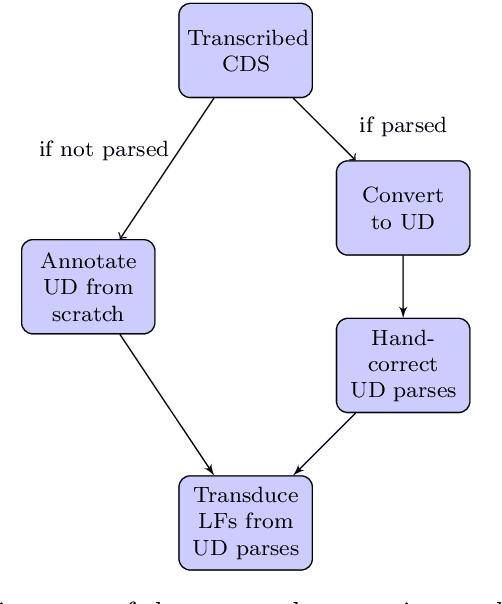
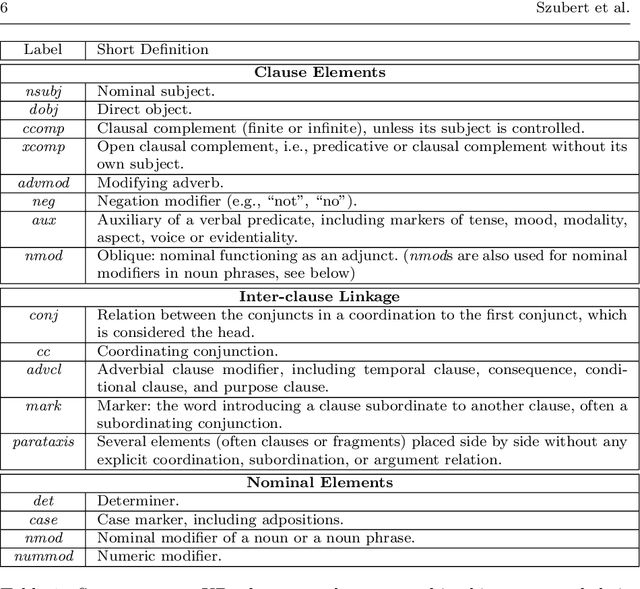
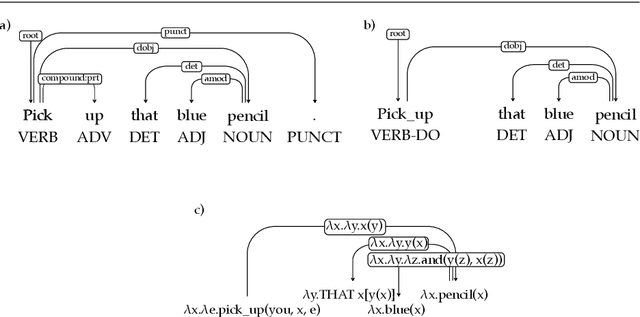
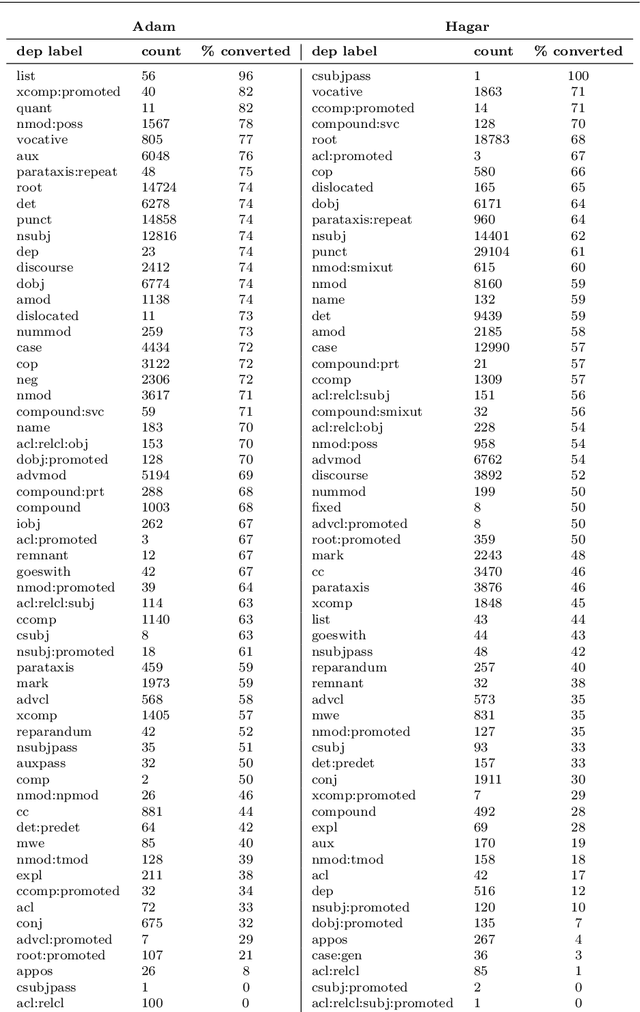
While corpora of child speech and child-directed speech (CDS) have enabled major contributions to the study of child language acquisition, semantic annotation for such corpora is still scarce and lacks a uniform standard. We compile two CDS corpora with sentential logical forms, one in English and the other in Hebrew. In compiling the corpora we employ a methodology that enforces a cross-linguistically consistent representation, building on recent advances in dependency representation and semantic parsing. The corpora are based on a sizable portion of Brown's Adam corpus from CHILDES (about 80% of its child-directed utterances), and to all child-directed utterances from Berman's Hebrew CHILDES corpus Hagar. We begin by annotating the corpora with the Universal Dependencies (UD) scheme for syntactic annotation, motivated by its applicability to a wide variety of domains and languages. We then proceed by applying an automatic method for transducing sentential logical forms (LFs) from UD structures. The two representations have complementary strengths: UD structures are language-neutral and support direct annotation, whereas LFs are neutral as to the interface between syntax and semantics, and transparently encode semantic distinctions. We verify the quality of the annotated UD annotation using an inter-annotator agreement study. We then demonstrate the utility of the compiled corpora through a longitudinal corpus study of the prevalence of different syntactic and semantic phenomena.
Blindness to Modality Helps Entailment Graph Mining
Sep 21, 2021
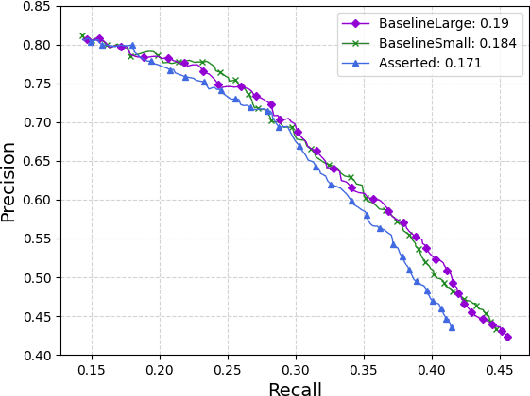
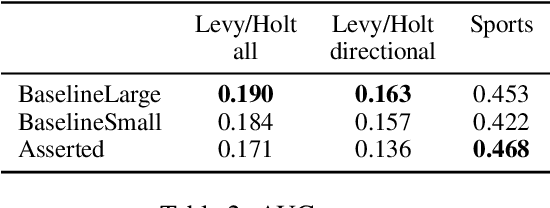
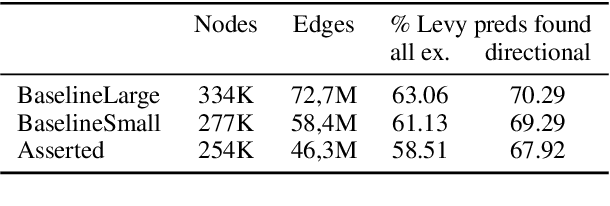
Understanding linguistic modality is widely seen as important for downstream tasks such as Question Answering and Knowledge Graph Population. Entailment Graph learning might also be expected to benefit from attention to modality. We build Entailment Graphs using a news corpus filtered with a modality parser, and show that stripping modal modifiers from predicates in fact increases performance. This suggests that for some tasks, the pragmatics of modal modification of predicates allows them to contribute as evidence of entailment.
Incorporating Temporal Information in Entailment Graph Mining
Sep 20, 2021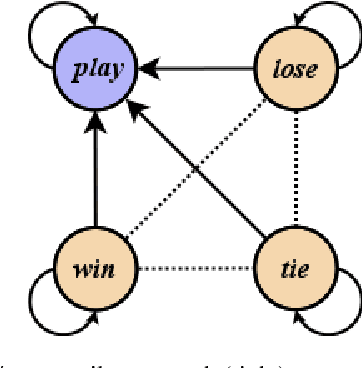
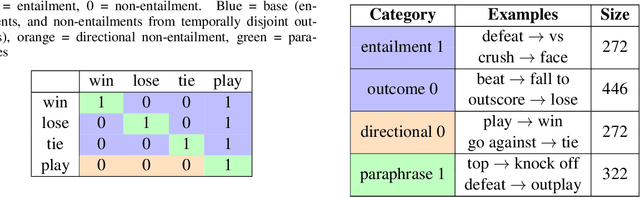
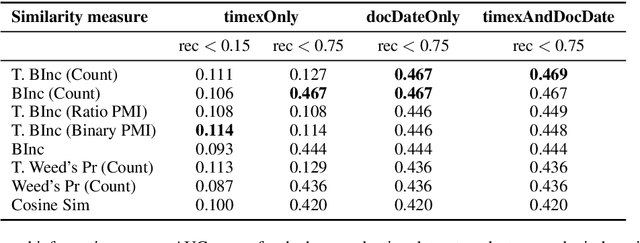
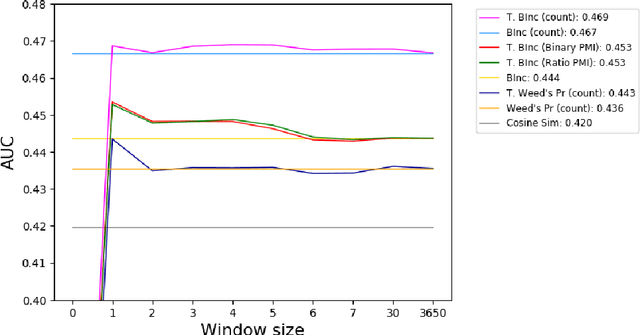
We present a novel method for injecting temporality into entailment graphs to address the problem of spurious entailments, which may arise from similar but temporally distinct events involving the same pair of entities. We focus on the sports domain in which the same pairs of teams play on different occasions, with different outcomes. We present an unsupervised model that aims to learn entailments such as win/lose $\rightarrow$ play, while avoiding the pitfall of learning non-entailments such as win $\not\rightarrow$ lose. We evaluate our model on a manually constructed dataset, showing that incorporating time intervals and applying a temporal window around them, are effective strategies.
* L. Guillou, S. Bijl de Vroe, M.J. Hosseini, M. Johnson, and M. Steedman. 2020. Incorporating temporal information in entailment graph mining. In Proceedings of the Graph-based Methods for Natural Language Processing (TextGraphs), pages 60-71, Barcelona, Spain (Online). Association for Computational Linguistics
Modality and Negation in Event Extraction
Sep 20, 2021
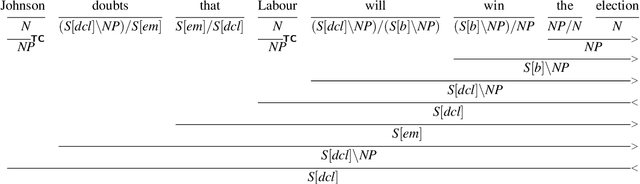
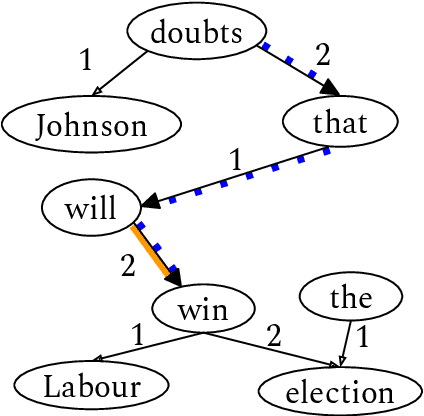
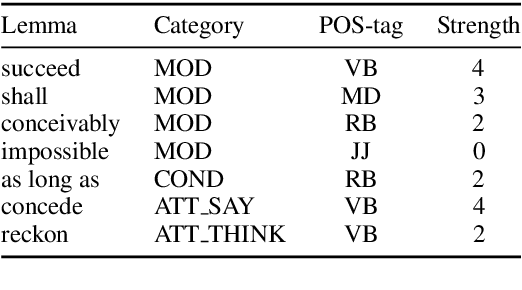
Language provides speakers with a rich system of modality for expressing thoughts about events, without being committed to their actual occurrence. Modality is commonly used in the political news domain, where both actual and possible courses of events are discussed. NLP systems struggle with these semantic phenomena, often incorrectly extracting events which did not happen, which can lead to issues in downstream applications. We present an open-domain, lexicon-based event extraction system that captures various types of modality. This information is valuable for Question Answering, Knowledge Graph construction and Fact-checking tasks, and our evaluation shows that the system is sufficiently strong to be used in downstream applications.
* S. Bijl de Vroe, L. Guillou, M. Stanojevi\'c, N. McKenna, and M. Steedman. 2021. Modality and Negation in Event Extraction. In Proceedings of the 4th Workshop on Challenges and Applications of Automated Extraction of Socio-political Events from Text (CASE 2021), pages 31-42, online. Association for Computational Linguistics
Prosodic segmentation for parsing spoken dialogue
May 26, 2021
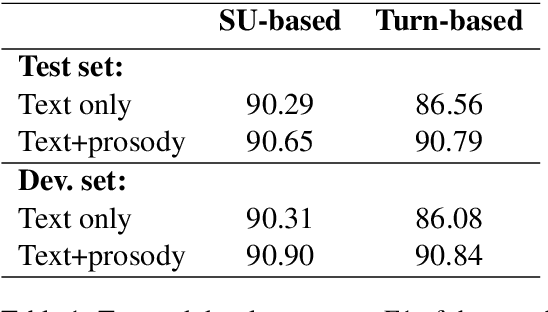
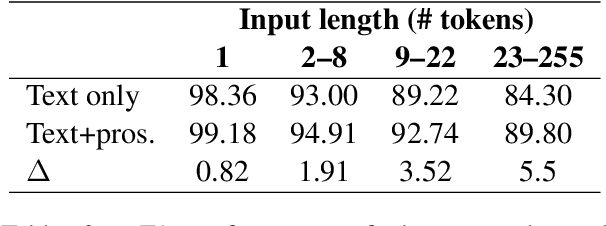
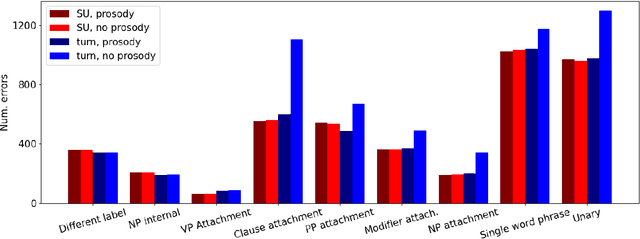
Parsing spoken dialogue poses unique difficulties, including disfluencies and unmarked boundaries between sentence-like units. Previous work has shown that prosody can help with parsing disfluent speech (Tran et al. 2018), but has assumed that the input to the parser is already segmented into sentence-like units (SUs), which isn't true in existing speech applications. We investigate how prosody affects a parser that receives an entire dialogue turn as input (a turn-based model), instead of gold standard pre-segmented SUs (an SU-based model). In experiments on the English Switchboard corpus, we find that when using transcripts alone, the turn-based model has trouble segmenting SUs, leading to worse parse performance than the SU-based model. However, prosody can effectively replace gold standard SU boundaries: with prosody, the turn-based model performs as well as the SU-based model (90.79 vs. 90.65 F1 score, respectively), despite performing two tasks (SU segmentation and parsing) rather than one (parsing alone). Analysis shows that pitch and intensity features are the most important for this corpus, since they allow the model to correctly distinguish an SU boundary from a speech disfluency -- a distinction that the model otherwise struggles to make.
Multivalent Entailment Graphs for Question Answering
Apr 16, 2021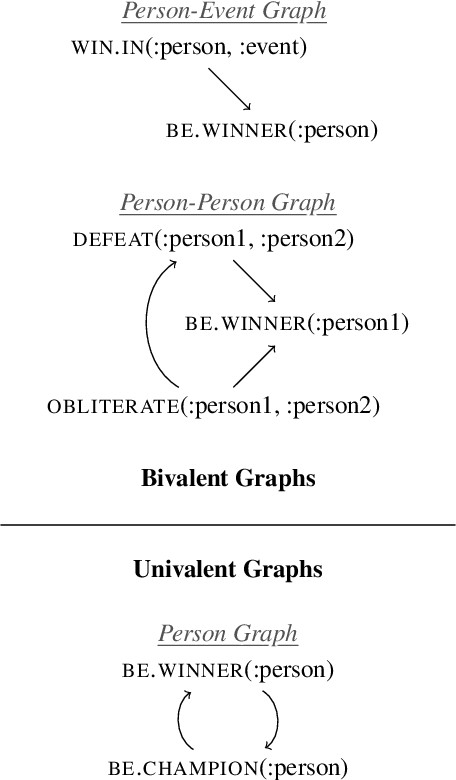
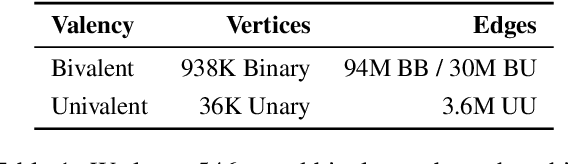

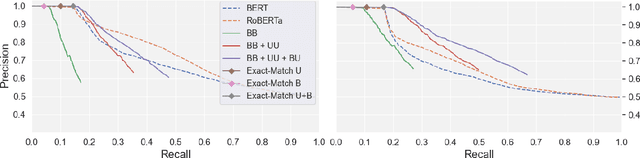
Drawing inferences between open-domain natural language predicates is a necessity for true language understanding. There has been much progress in unsupervised learning of entailment graphs for this purpose. We make three contributions: (1) we reinterpret the Distributional Inclusion Hypothesis to model entailment between predicates of different valencies, like DEFEAT(Biden, Trump) entails WIN(Biden); (2) we actualize this theory by learning unsupervised Multivalent Entailment Graphs of open-domain predicates; and (3) we demonstrate the capabilities of these graphs on a novel question answering task. We show that directional entailment is more helpful for inference than bidirectional similarity on questions of fine-grained semantics. We also show that drawing on evidence across valencies answers more questions than by using only the same valency evidence.
Aspectuality Across Genre: A Distributional Semantics Approach
Oct 31, 2020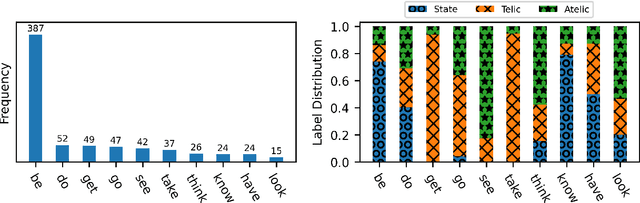
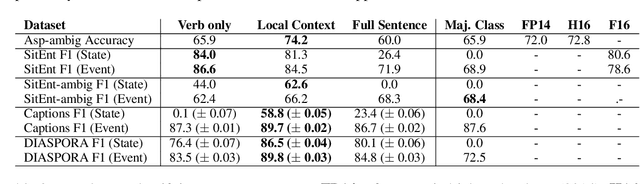
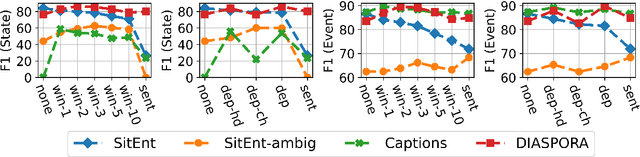
The interpretation of the lexical aspect of verbs in English plays a crucial role for recognizing textual entailment and learning discourse-level inferences. We show that two elementary dimensions of aspectual class, states vs. events, and telic vs. atelic events, can be modelled effectively with distributional semantics. We find that a verb's local context is most indicative of its aspectual class, and demonstrate that closed class words tend to be stronger discriminating contexts than content words. Our approach outperforms previous work on three datasets. Lastly, we contribute a dataset of human--human conversations annotated with lexical aspect and present experiments that show the correlation of telicity with genre and discourse goals.
The role of context in neural pitch accent detection in English
Apr 30, 2020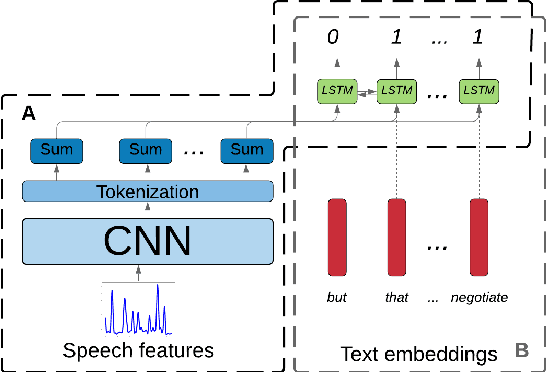
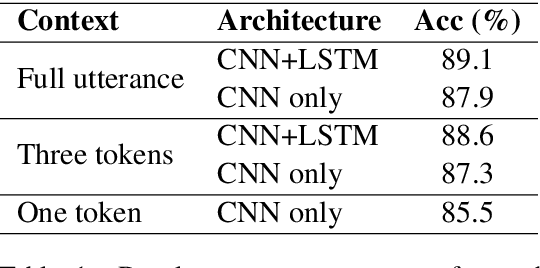
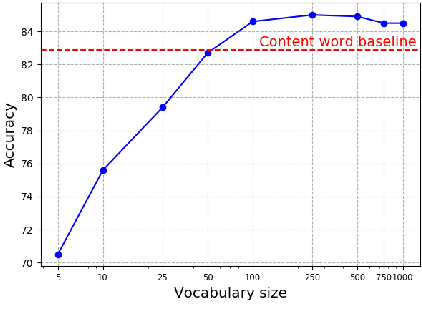
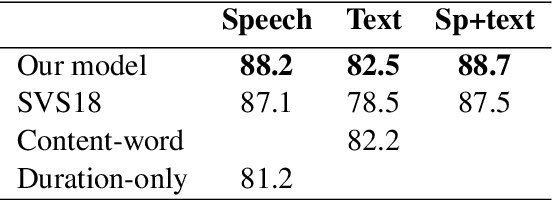
Prosody is a rich information source in natural language, serving as a marker for phenomena such as contrast. In order to make this information available to downstream tasks, we need a way to detect prosodic events in speech. We propose a new model for pitch accent detection, inspired by the work of Stehwien et al. (2018), who presented a CNN-based model for this task. Our model makes greater use of context by using full utterances as input and adding an LSTM layer. We find that these innovations lead to an improvement from 87.5% to 88.7% accuracy on pitch accent detection on American English speech in the Boston University Radio News Corpus, a state-of-the-art result. We also find that a simple baseline that just predicts a pitch accent on every content word yields 82.2% accuracy, and we suggest that this is the appropriate baseline for this task. Finally, we conduct ablation tests that show pitch is the most important acoustic feature for this task and this corpus.