 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrimality Testing via Circulant Matrix Eigenvalue Structure: A Novel Approach Using Cyclotomic Field Theory
Apr 28, 2025This paper presents a novel primality test based on the eigenvalue structure of circulant matrices constructed from roots of unity. We prove that an integer $n > 2$ is prime if and only if the minimal polynomial of the circulant matrix $C_n = W_n + W_n^2$ has exactly two irreducible factors over $\mathbb{Q}$. This characterization connects cyclotomic field theory with matrix algebra, providing both theoretical insights and practical applications. We demonstrate that the eigenvalue patterns of these matrices reveal fundamental distinctions between prime and composite numbers, leading to a deterministic primality test. Our approach leverages the relationship between primitive roots of unity, Galois theory, and the factorization of cyclotomic polynomials. We provide comprehensive experimental validation across various ranges of integers, discuss practical implementation considerations, and analyze the computational complexity of our method in comparison with established primality tests. The visual interpretation of our mathematical framework provides intuitive understanding of the algebraic structures that distinguish prime numbers. Our experimental validation demonstrates that our approach offers a deterministic alternative to existing methods, with performance characteristics reflecting its algebraic foundations.
Parameter Choice and Neuro-Symbolic Approaches for Deep Domain-Invariant Learning
Oct 08, 2024



As artificial intelligence (AI) systems advance, we move towards broad AI: systems capable of performing well on diverse tasks, understanding context, and adapting rapidly to new scenarios. A central challenge for broad AI systems is to generalize over tasks in related domains and being robust to distribution shifts. Neuro-symbolic (NeSy) AI bridges the gap between symbolic and sub-symbolic paradigms to address these challenges, enabling adaptable, generalizable, and more interpretable systems. The development of broad AI requires advancements in domain adaptation (DA), enabling models trained on source domains to effectively generalize to unseen target domains. Traditional approaches often rely on parameter optimization and fine-tuning, which can be impractical due to high costs and risks of catastrophic forgetting. NeSy AI systems use multiple models and methods to generalize to unseen domains and maintain performance across varying conditions. We analyze common DA and NeSy approaches with a focus on deep domain-invariant learning, extending to real-world challenges such as adapting to continuously changing domains and handling large domain gaps. We showcase state-of-the-art model-selection methods for scenarios with limited samples and introduce domain-specific adaptations without gradient-based updates for cases where model tuning is infeasible. This work establishes a framework for scalable and generalizable broad AI systems applicable across various problem settings, demonstrating how symbolic reasoning and large language models can build universal computational graphs that generalize across domains and problems, contributing to more adaptable AI approaches for real-world applications.
Large Language Models Can Self-Improve At Web Agent Tasks
May 30, 2024



Training models to act as agents that can effectively navigate and perform actions in a complex environment, such as a web browser, has typically been challenging due to lack of training data. Large language models (LLMs) have recently demonstrated some capability to navigate novel environments as agents in a zero-shot or few-shot fashion, purely guided by natural language instructions as prompts. Recent research has also demonstrated LLMs have the capability to exceed their base performance through self-improvement, i.e. fine-tuning on data generated by the model itself. In this work, we explore the extent to which LLMs can self-improve their performance as agents in long-horizon tasks in a complex environment using the WebArena benchmark. In WebArena, an agent must autonomously navigate and perform actions on web pages to achieve a specified objective. We explore fine-tuning on three distinct synthetic training data mixtures and achieve a 31\% improvement in task completion rate over the base model on the WebArena benchmark through a self-improvement procedure. We additionally contribute novel evaluation metrics for assessing the performance, robustness, capabilities, and quality of trajectories of our fine-tuned agent models to a greater degree than simple, aggregate-level benchmark scores currently used to measure self-improvement.
SymbolicAI: A framework for logic-based approaches combining generative models and solvers
Feb 05, 2024We introduce SymbolicAI, a versatile and modular framework employing a logic-based approach to concept learning and flow management in generative processes. SymbolicAI enables the seamless integration of generative models with a diverse range of solvers by treating large language models (LLMs) as semantic parsers that execute tasks based on both natural and formal language instructions, thus bridging the gap between symbolic reasoning and generative AI. We leverage probabilistic programming principles to tackle complex tasks, and utilize differentiable and classical programming paradigms with their respective strengths. The framework introduces a set of polymorphic, compositional, and self-referential operations for data stream manipulation, aligning LLM outputs with user objectives. As a result, we can transition between the capabilities of various foundation models endowed with zero- and few-shot learning capabilities and specialized, fine-tuned models or solvers proficient in addressing specific problems. In turn, the framework facilitates the creation and evaluation of explainable computational graphs. We conclude by introducing a quality measure and its empirical score for evaluating these computational graphs, and propose a benchmark that compares various state-of-the-art LLMs across a set of complex workflows. We refer to the empirical score as the "Vector Embedding for Relational Trajectory Evaluation through Cross-similarity", or VERTEX score for short. The framework codebase and benchmark are linked below.
Addressing Parameter Choice Issues in Unsupervised Domain Adaptation by Aggregation
May 02, 2023



We study the problem of choosing algorithm hyper-parameters in unsupervised domain adaptation, i.e., with labeled data in a source domain and unlabeled data in a target domain, drawn from a different input distribution. We follow the strategy to compute several models using different hyper-parameters, and, to subsequently compute a linear aggregation of the models. While several heuristics exist that follow this strategy, methods are still missing that rely on thorough theories for bounding the target error. In this turn, we propose a method that extends weighted least squares to vector-valued functions, e.g., deep neural networks. We show that the target error of the proposed algorithm is asymptotically not worse than twice the error of the unknown optimal aggregation. We also perform a large scale empirical comparative study on several datasets, including text, images, electroencephalogram, body sensor signals and signals from mobile phones. Our method outperforms deep embedded validation (DEV) and importance weighted validation (IWV) on all datasets, setting a new state-of-the-art performance for solving parameter choice issues in unsupervised domain adaptation with theoretical error guarantees. We further study several competitive heuristics, all outperforming IWV and DEV on at least five datasets. However, our method outperforms each heuristic on at least five of seven datasets.
* Oral talk (notable-top-5%) at International Conference On Learning Representations (ICLR), 2023
Reactive Exploration to Cope with Non-Stationarity in Lifelong Reinforcement Learning
Jul 12, 2022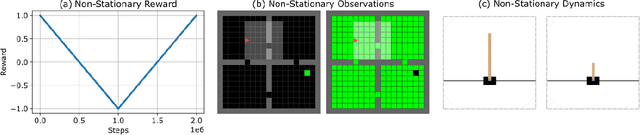
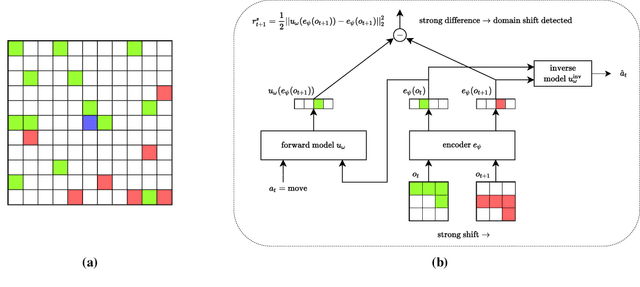
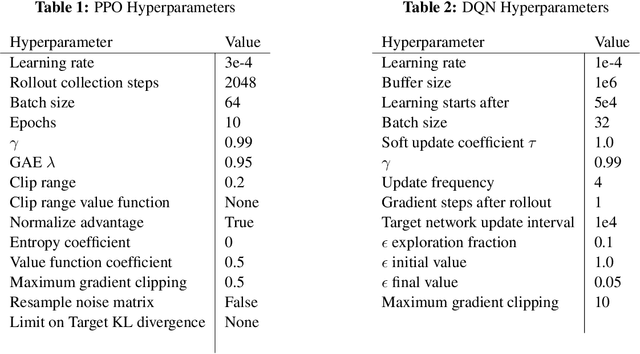
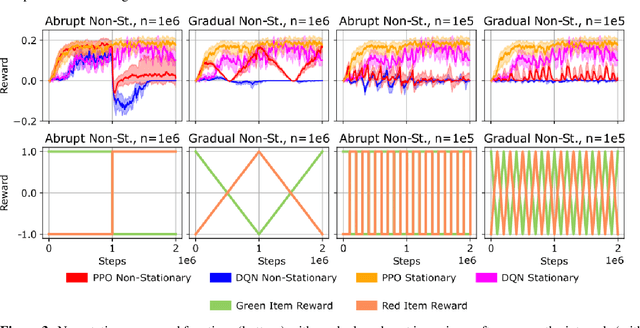
In lifelong learning, an agent learns throughout its entire life without resets, in a constantly changing environment, as we humans do. Consequently, lifelong learning comes with a plethora of research problems such as continual domain shifts, which result in non-stationary rewards and environment dynamics. These non-stationarities are difficult to detect and cope with due to their continuous nature. Therefore, exploration strategies and learning methods are required that are capable of tracking the steady domain shifts, and adapting to them. We propose Reactive Exploration to track and react to continual domain shifts in lifelong reinforcement learning, and to update the policy correspondingly. To this end, we conduct experiments in order to investigate different exploration strategies. We empirically show that representatives of the policy-gradient family are better suited for lifelong learning, as they adapt more quickly to distribution shifts than Q-learning. Thereby, policy-gradient methods profit the most from Reactive Exploration and show good results in lifelong learning with continual domain shifts. Our code is available at: https://github.com/ml-jku/reactive-exploration.
Understanding the Effects of Dataset Characteristics on Offline Reinforcement Learning
Nov 08, 2021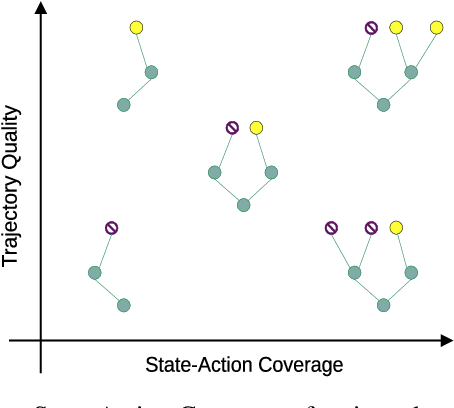
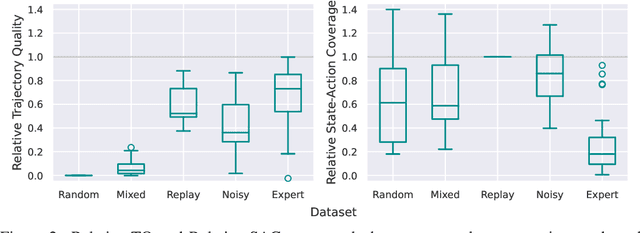
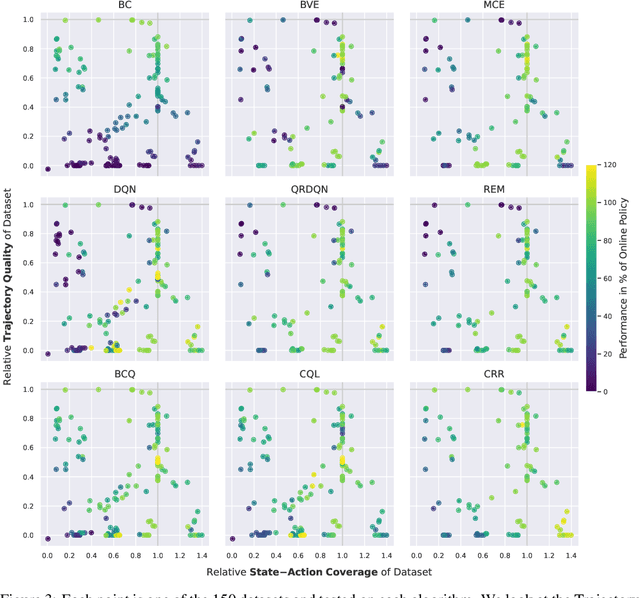

In real world, affecting the environment by a weak policy can be expensive or very risky, therefore hampers real world applications of reinforcement learning. Offline Reinforcement Learning (RL) can learn policies from a given dataset without interacting with the environment. However, the dataset is the only source of information for an Offline RL algorithm and determines the performance of the learned policy. We still lack studies on how dataset characteristics influence different Offline RL algorithms. Therefore, we conducted a comprehensive empirical analysis of how dataset characteristics effect the performance of Offline RL algorithms for discrete action environments. A dataset is characterized by two metrics: (1) the average dataset return measured by the Trajectory Quality (TQ) and (2) the coverage measured by the State-Action Coverage (SACo). We found that variants of the off-policy Deep Q-Network family require datasets with high SACo to perform well. Algorithms that constrain the learned policy towards the given dataset perform well for datasets with high TQ or SACo. For datasets with high TQ, Behavior Cloning outperforms or performs similarly to the best Offline RL algorithms.
Align-RUDDER: Learning From Few Demonstrations by Reward Redistribution
Sep 29, 2020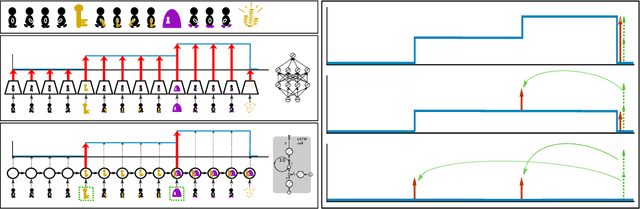

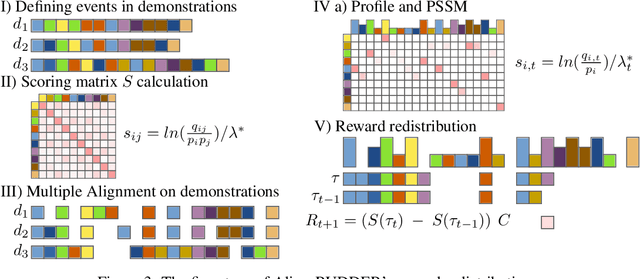
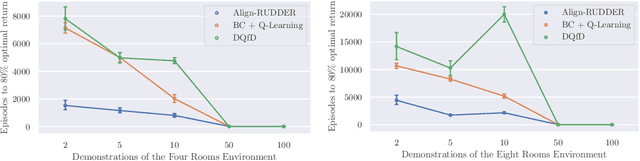
Reinforcement Learning algorithms require a large number of samples to solve complex tasks with sparse and delayed rewards. Complex tasks can often be hierarchically decomposed into sub-tasks. A step in the Q-function can be associated with solving a sub-task, where the expectation of the return increases. RUDDER has been introduced to identify these steps and then redistribute reward to them, thus immediately giving reward if sub-tasks are solved. Since the problem of delayed rewards is mitigated, learning is considerably sped up. However, for complex tasks, current exploration strategies as deployed in RUDDER struggle with discovering episodes with high rewards. Therefore, we assume that episodes with high rewards are given as demonstrations and do not have to be discovered by exploration. Typically the number of demonstrations is small and RUDDER's LSTM model as a deep learning method does not learn well. Hence, we introduce Align-RUDDER, which is RUDDER with two major modifications. First, Align-RUDDER assumes that episodes with high rewards are given as demonstrations, replacing RUDDER's safe exploration and lessons replay buffer. Second, we replace RUDDER's LSTM model by a profile model that is obtained from multiple sequence alignment of demonstrations. Profile models can be constructed from as few as two demonstrations as known from bioinformatics. Align-RUDDER inherits the concept of reward redistribution, which considerably reduces the delay of rewards, thus speeding up learning. Align-RUDDER outperforms competitors on complex artificial tasks with delayed reward and few demonstrations. On the MineCraft ObtainDiamond task, Align-RUDDER is able to mine a diamond, though not frequently. Github: https://github.com/ml-jku/align-rudder, YouTube: https://youtu.be/HO-_8ZUl-UY