 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeML-Doctor: Holistic Risk Assessment of Inference Attacks Against Machine Learning Models
Feb 04, 2021
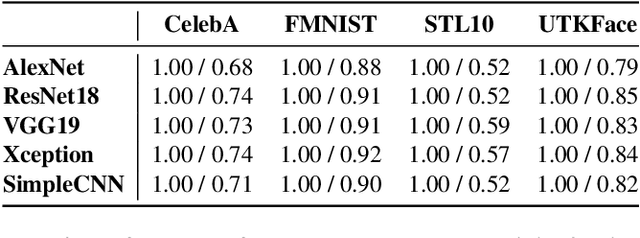
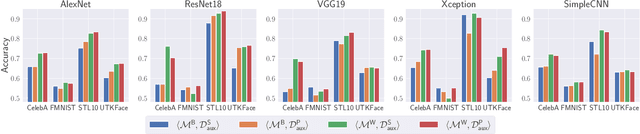
Inference attacks against Machine Learning (ML) models allow adversaries to learn information about training data, model parameters, etc. While researchers have studied these attacks thoroughly, they have done so in isolation. We lack a comprehensive picture of the risks caused by the attacks, such as the different scenarios they can be applied to, the common factors that influence their performance, the relationship among them, or the effectiveness of defense techniques. In this paper, we fill this gap by presenting a first-of-its-kind holistic risk assessment of different inference attacks against machine learning models. We concentrate on four attacks - namely, membership inference, model inversion, attribute inference, and model stealing - and establish a threat model taxonomy. Our extensive experimental evaluation conducted over five model architectures and four datasets shows that the complexity of the training dataset plays an important role with respect to the attack's performance, while the effectiveness of model stealing and membership inference attacks are negatively correlated. We also show that defenses like DP-SGD and Knowledge Distillation can only hope to mitigate some of the inference attacks. Our analysis relies on a modular re-usable software, ML-Doctor, which enables ML model owners to assess the risks of deploying their models, and equally serves as a benchmark tool for researchers and practitioners.
Responsible Disclosure of Generative Models Using Scalable Fingerprinting
Dec 16, 2020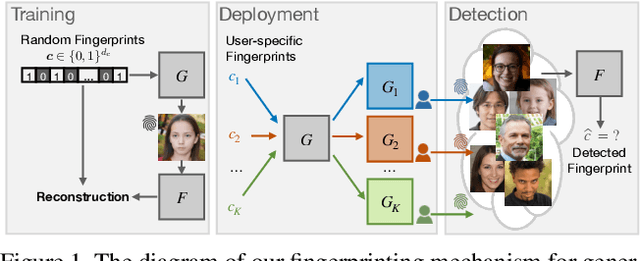
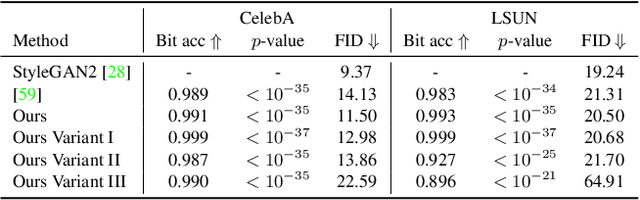
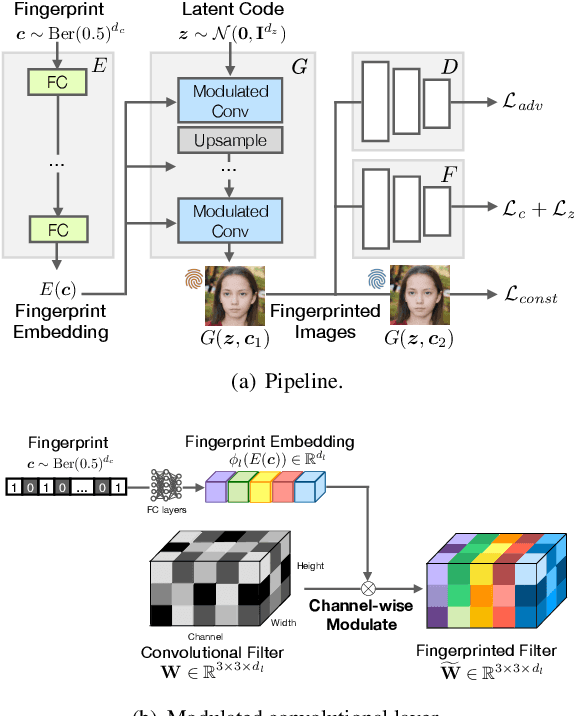
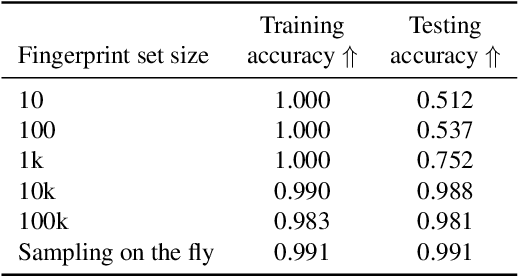
Over the past five years, deep generative models have achieved a qualitative new level of performance. Generated data has become difficult, if not impossible, to be distinguished from real data. While there are plenty of use cases that benefit from this technology, there are also strong concerns on how this new technology can be misused to spoof sensors, generate deep fakes, and enable misinformation at scale. Unfortunately, current deep fake detection methods are not sustainable, as the gap between real and fake continues to close. In contrast, our work enables a responsible disclosure of such state-of-the-art generative models, that allows researchers and companies to fingerprint their models, so that the generated samples containing a fingerprint can be accurately detected and attributed to a source. Our technique achieves this by an efficient and scalable ad-hoc generation of a large population of models with distinct fingerprints. Our recommended operation point uses a 128-bit fingerprint which in principle results in more than $10^{36}$ identifiable models. Experimental results show that our method fulfills key properties of a fingerprinting mechanism and achieves effectiveness in deep fake detection and attribution.
CosSGD: Nonlinear Quantization for Communication-efficient Federated Learning
Dec 15, 2020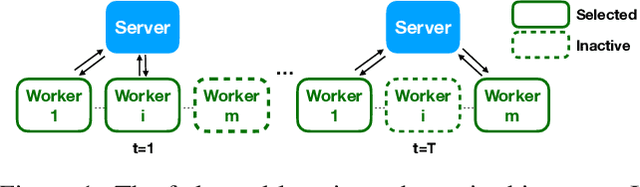
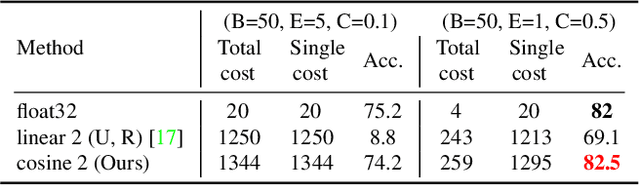
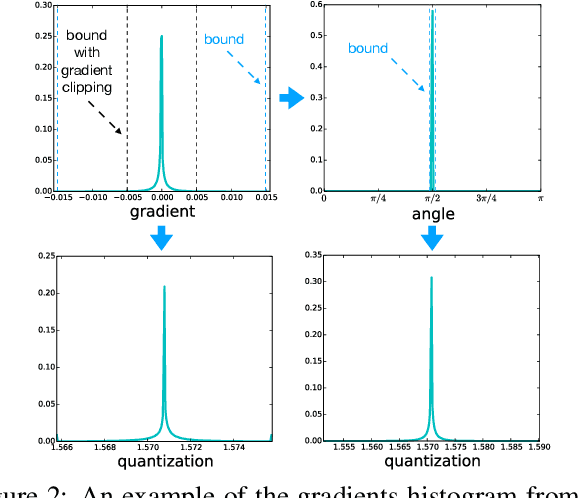
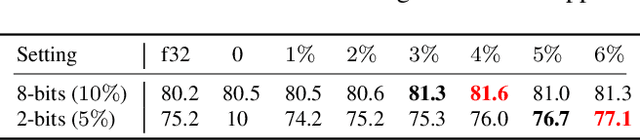
Federated learning facilitates learning across clients without transferring local data on these clients to a central server. Despite the success of the federated learning method, it remains to improve further w.r.t communicating the most critical information to update a model under limited communication conditions, which can benefit this learning scheme into a wide range of application scenarios. In this work, we propose a nonlinear quantization for compressed stochastic gradient descent, which can be easily utilized in federated learning. Based on the proposed quantization, our system significantly reduces the communication cost by up to three orders of magnitude, while maintaining convergence and accuracy of the training process to a large extent. Extensive experiments are conducted on image classification and brain tumor semantic segmentation using the MNIST, CIFAR-10 and BraTS datasets where we show state-of-the-art effectiveness and impressive communication efficiency.
Hijack-GAN: Unintended-Use of Pretrained, Black-Box GANs
Nov 28, 2020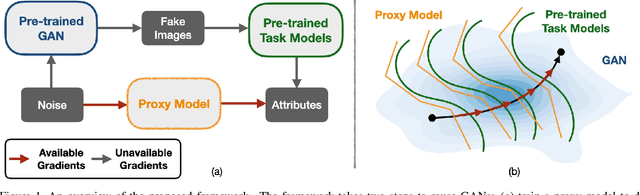
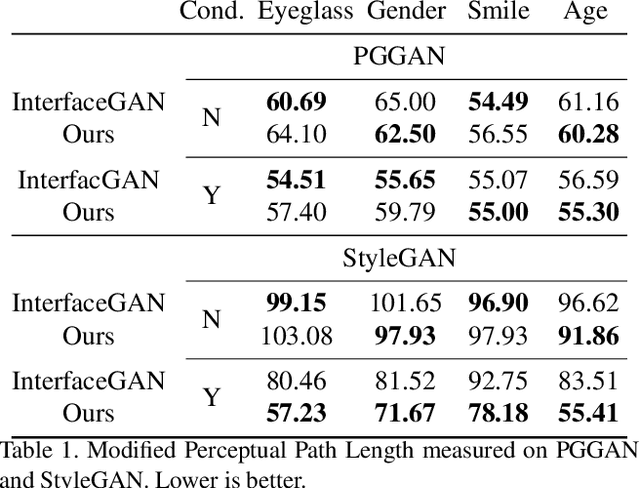

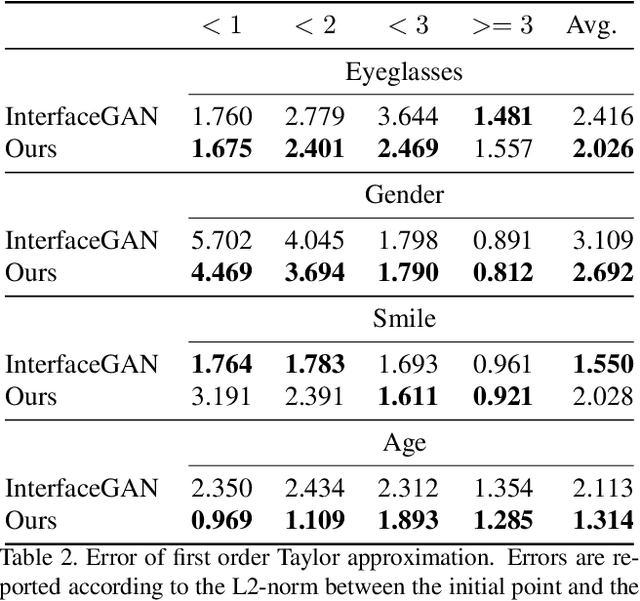
While Generative Adversarial Networks (GANs) show increasing performance and the level of realism is becoming indistinguishable from natural images, this also comes with high demands on data and computation. We show that state-of-the-art GAN models -- such as they are being publicly released by researchers and industry -- can be used for a range of applications beyond unconditional image generation. We achieve this by an iterative scheme that also allows gaining control over the image generation process despite the highly non-linear latent spaces of the latest GAN models. We demonstrate that this opens up the possibility to re-use state-of-the-art, difficult to train, pre-trained GANs with a high level of control even if only black-box access is granted. Our work also raises concerns and awareness that the use cases of a published GAN model may well reach beyond the creators' intention, which needs to be taken into account before a full public release.
Haar Wavelet based Block Autoregressive Flows for Trajectories
Sep 21, 2020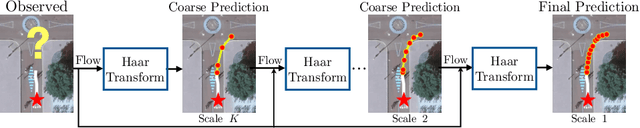
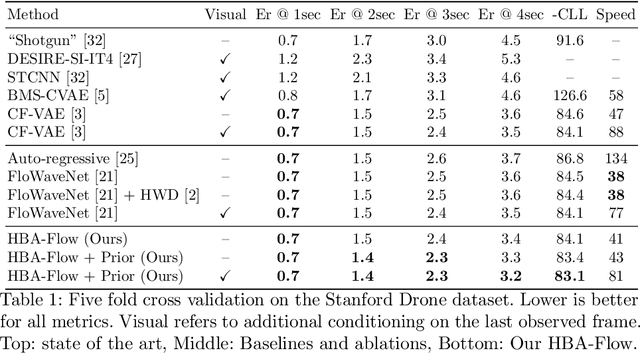
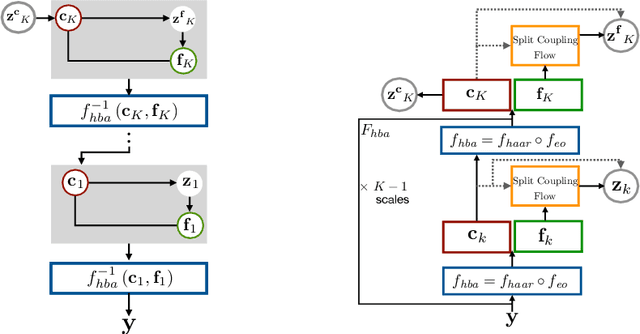
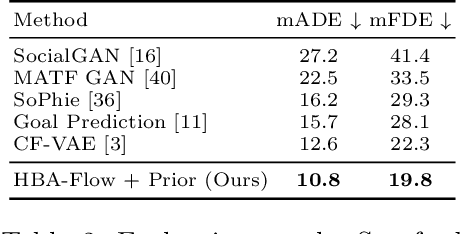
Prediction of trajectories such as that of pedestrians is crucial to the performance of autonomous agents. While previous works have leveraged conditional generative models like GANs and VAEs for learning the likely future trajectories, accurately modeling the dependency structure of these multimodal distributions, particularly over long time horizons remains challenging. Normalizing flow based generative models can model complex distributions admitting exact inference. These include variants with split coupling invertible transformations that are easier to parallelize compared to their autoregressive counterparts. To this end, we introduce a novel Haar wavelet based block autoregressive model leveraging split couplings, conditioned on coarse trajectories obtained from Haar wavelet based transformations at different levels of granularity. This yields an exact inference method that models trajectories at different spatio-temporal resolutions in a hierarchical manner. We illustrate the advantages of our approach for generating diverse and accurate trajectories on two real-world datasets - Stanford Drone and Intersection Drone.
Synthetic Convolutional Features for Improved Semantic Segmentation
Sep 18, 2020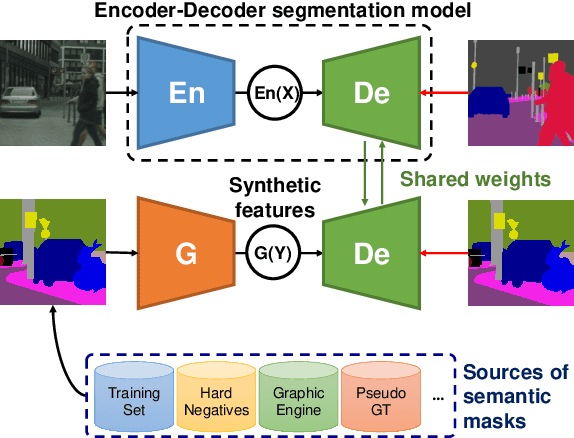
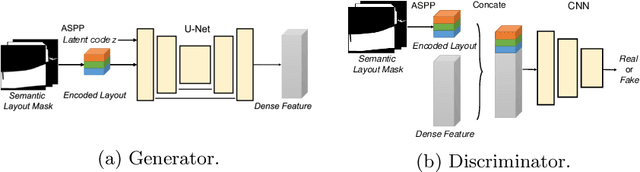
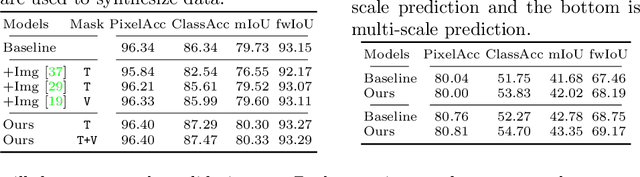

Recently, learning-based image synthesis has enabled to generate high-resolution images, either applying popular adversarial training or a powerful perceptual loss. However, it remains challenging to successfully leverage synthetic data for improving semantic segmentation with additional synthetic images. Therefore, we suggest to generate intermediate convolutional features and propose the first synthesis approach that is catered to such intermediate convolutional features. This allows us to generate new features from label masks and include them successfully into the training procedure in order to improve the performance of semantic segmentation. Experimental results and analysis on two challenging datasets Cityscapes and ADE20K show that our generated feature improves performance on segmentation tasks.
Adversarial Watermarking Transformer: Towards Tracing Text Provenance with Data Hiding
Sep 07, 2020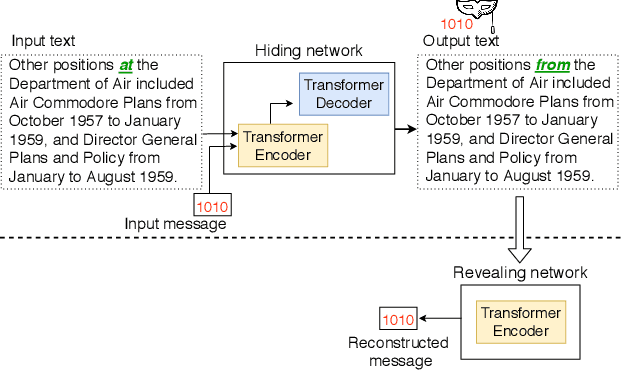
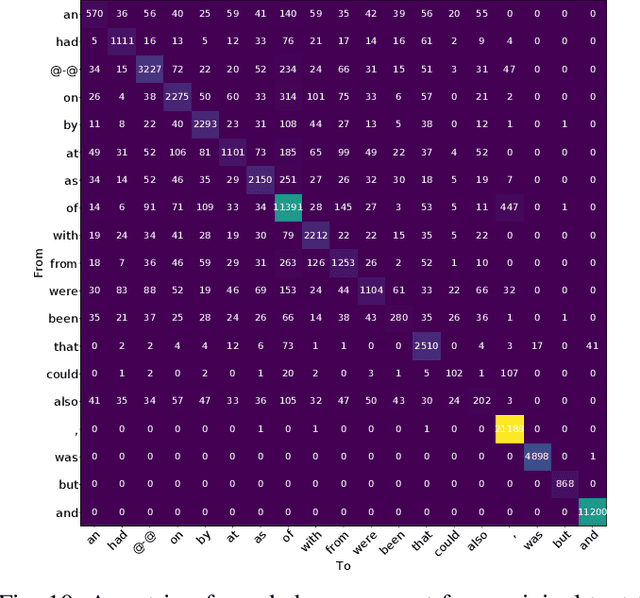
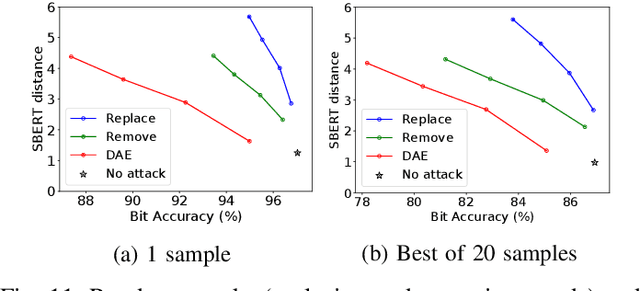
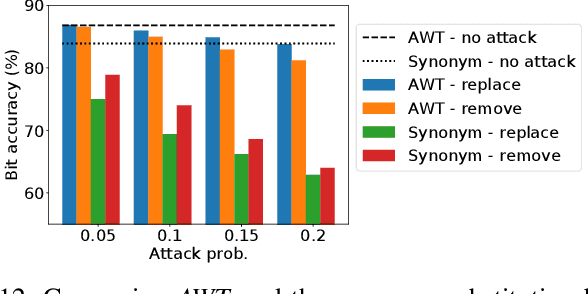
Recent advances in natural language generation have introduced powerful language models with high-quality output text. However, this raises concerns about the potential misuse of such models for malicious purposes. In this paper, we study natural language watermarking as a defense to help better mark and trace the provenance of text. We introduce the Adversarial Watermarking Transformer (AWT) with a jointly trained encoder-decoder and adversarial training that, given an input text and a binary message, generates an output text that is unobtrusively encoded with the given message. We further study different training and inference strategies to achieve minimal changes to the semantics and correctness of the input text. AWT is the first end-to-end model to hide data in text by automatically learning -- without ground truth -- word substitutions along with their locations in order to encode the message. We show that our model is effective in largely preserving text utility and decoding the watermark while hiding its presence against adversaries. Additionally, we demonstrate that our method is robust against a range of local changes and denoising attacks.
Sampling Attacks: Amplification of Membership Inference Attacks by Repeated Queries
Sep 01, 2020
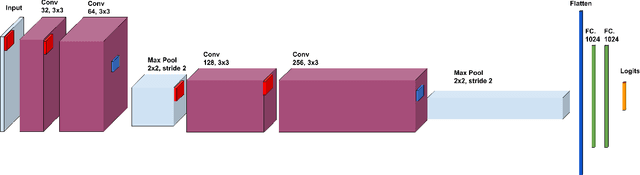
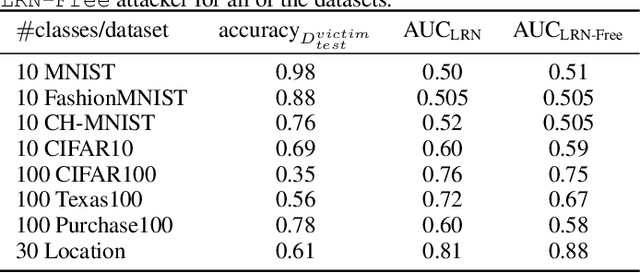
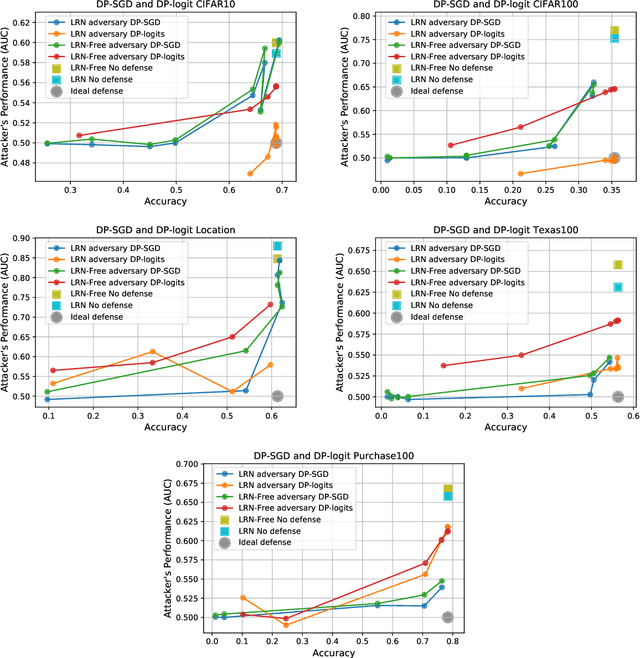
Machine learning models have been shown to leak information violating the privacy of their training set. We focus on membership inference attacks on machine learning models which aim to determine whether a data point was used to train the victim model. Our work consists of two sides: We introduce sampling attack, a novel membership inference technique that unlike other standard membership adversaries is able to work under severe restriction of no access to scores of the victim model. We show that a victim model that only publishes the labels is still susceptible to sampling attacks and the adversary can recover up to 100% of its performance compared to when posterior vectors are provided. The other sides of our work includes experimental results on two recent membership inference attack models and the defenses against them. For defense, we choose differential privacy in the form of gradient perturbation during the training of the victim model as well as output perturbation at prediction time. We carry out our experiments on a wide range of datasets which allows us to better analyze the interaction between adversaries, defense mechanism and datasets. We find out that our proposed fast and easy-to-implement output perturbation technique offers good privacy protection for membership inference attacks at little impact on utility.
Black-Box Watermarking for Generative Adversarial Networks
Aug 03, 2020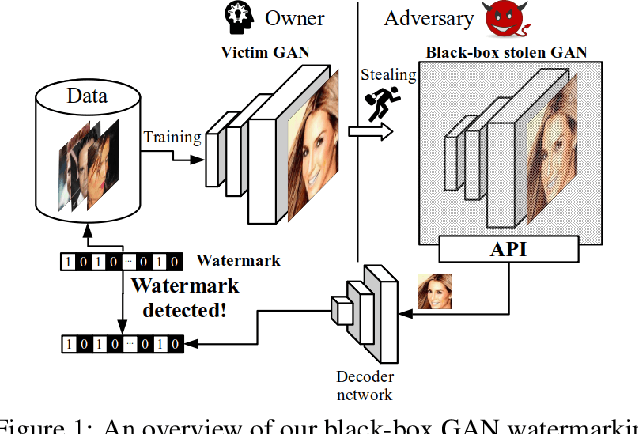
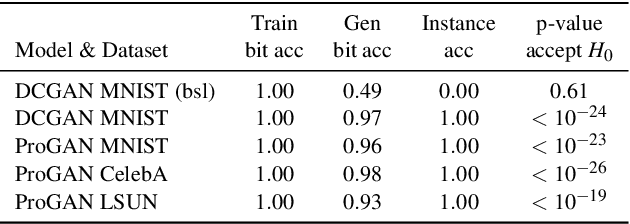
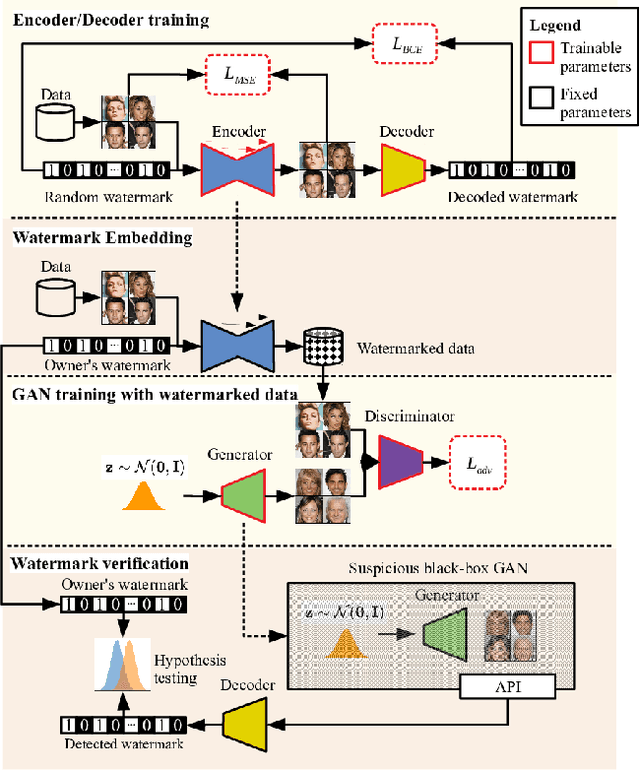
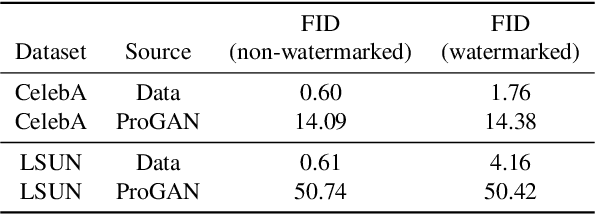
As companies start using deep learning to provide value to their customers, the demand for solutions to protect the ownership of trained models becomes evident. Several watermarking approaches have been proposed for protecting discriminative models. However, rapid progress in the task of photorealistic image synthesis, boosted by Generative Adversarial Networks (GANs), raises an urgent need for extending protection to generative models. We propose the first watermarking solution for GAN models. We leverage steganography techniques to watermark GAN training dataset, transfer the watermark from dataset to GAN models, and then verify the watermark from generated images. In the experiments, we show that the hidden encoding characteristic of steganography allows preserving generation quality and supports the watermark secrecy against steganalysis attacks. We validate that our watermark verification is robust in wide ranges against several image and model perturbation attacks. Critically, our solution treats GAN models as an independent component: watermark embedding is agnostic to GAN details and watermark verification relies only on accessing the APIs of black-box GANs. We further extend our watermarking applications to generated image detection and attribution, which delivers a practical potential to facilitate forensics against deep fakes and responsibility tracking of GAN misuse.
IReEn: Iterative Reverse-Engineering of Black-Box Functions via Neural Program Synthesis
Jun 18, 2020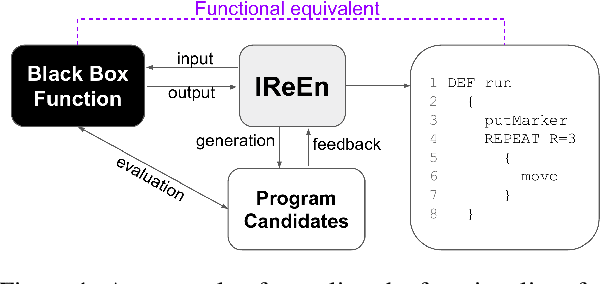
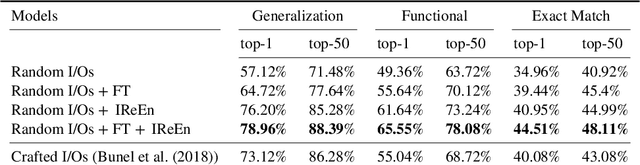
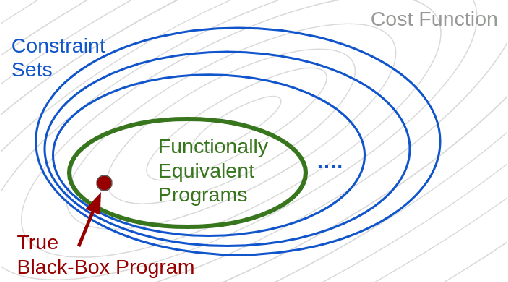
In this work, we investigate the problem of revealing the functionality of a black-box agent. Notably, we are interested in the interpretable and formal description of the behavior of such an agent. Ideally, this description would take the form of a program written in a high-level language. This task is also known as reverse engineering and plays a pivotal role in software engineering, computer security, but also most recently in interpretability. In contrast to prior work, we do not rely on privileged information on the black box, but rather investigate the problem under a weaker assumption of having only access to inputs and outputs of the program. We approach this problem by iteratively refining a candidate set using a generative neural program synthesis approach until we arrive at a functionally equivalent program. We assess the performance of our approach on the Karel dataset. Our results show that the proposed approach outperforms the state-of-the-art on this challenge by finding a functional equivalent program in 78% of cases -- even exceeding prior work that had privileged information on the black-box.