 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Forensics in Diffusion Models: A Systematic Analysis of Membership Privacy
Feb 15, 2023In recent years, diffusion models have achieved tremendous success in the field of image generation, becoming the stateof-the-art technology for AI-based image processing applications. Despite the numerous benefits brought by recent advances in diffusion models, there are also concerns about their potential misuse, specifically in terms of privacy breaches and intellectual property infringement. In particular, some of their unique characteristics open up new attack surfaces when considering the real-world deployment of such models. With a thorough investigation of the attack vectors, we develop a systematic analysis of membership inference attacks on diffusion models and propose novel attack methods tailored to each attack scenario specifically relevant to diffusion models. Our approach exploits easily obtainable quantities and is highly effective, achieving near-perfect attack performance (>0.9 AUCROC) in realistic scenarios. Our extensive experiments demonstrate the effectiveness of our method, highlighting the importance of considering privacy and intellectual property risks when using diffusion models in image generation tasks.
Systematically Finding Security Vulnerabilities in Black-Box Code Generation Models
Feb 08, 2023



Recently, large language models for code generation have achieved breakthroughs in several programming language tasks. Their advances in competition-level programming problems have made them an emerging pillar in AI-assisted pair programming. Tools such as GitHub Copilot are already part of the daily programming workflow and are used by more than a million developers. The training data for these models is usually collected from open-source repositories (e.g., GitHub) that contain software faults and security vulnerabilities. This unsanitized training data can lead language models to learn these vulnerabilities and propagate them in the code generation procedure. Given the wide use of these models in the daily workflow of developers, it is crucial to study the security aspects of these models systematically. In this work, we propose the first approach to automatically finding security vulnerabilities in black-box code generation models. To achieve this, we propose a novel black-box inversion approach based on few-shot prompting. We evaluate the effectiveness of our approach by examining code generation models in the generation of high-risk security weaknesses. We show that our approach automatically and systematically finds 1000s of security vulnerabilities in various code generation models, including the commercial black-box model GitHub Copilot.
Fed-GLOSS-DP: Federated, Global Learning using Synthetic Sets with Record Level Differential Privacy
Feb 02, 2023



This work proposes Fed-GLOSS-DP, a novel approach to privacy-preserving learning that uses synthetic data to train federated models. In our approach, the server recovers an approximation of the global loss landscape in a local neighborhood based on synthetic samples received from the clients. In contrast to previous, point-wise, gradient-based, linear approximation (such as FedAvg), our formulation enables a type of global optimization that is particularly beneficial in non-IID federated settings. We also present how it rigorously complements record-level differential privacy. Extensive results show that our novel formulation gives rise to considerable improvements in terms of convergence speed and communication costs. We argue that our new approach to federated learning can provide a potential path toward reconciling privacy and accountability by sending differentially private, synthetic data instead of gradient updates. The source code will be released upon publication.
Holistically Explainable Vision Transformers
Jan 20, 2023



Transformers increasingly dominate the machine learning landscape across many tasks and domains, which increases the importance for understanding their outputs. While their attention modules provide partial insight into their inner workings, the attention scores have been shown to be insufficient for explaining the models as a whole. To address this, we propose B-cos transformers, which inherently provide holistic explanations for their decisions. Specifically, we formulate each model component - such as the multi-layer perceptrons, attention layers, and the tokenisation module - to be dynamic linear, which allows us to faithfully summarise the entire transformer via a single linear transform. We apply our proposed design to Vision Transformers (ViTs) and show that the resulting models, dubbed Bcos-ViTs, are highly interpretable and perform competitively to baseline ViTs on ImageNet. Code will be made available soon.
Private Set Generation with Discriminative Information
Nov 07, 2022



Differentially private data generation techniques have become a promising solution to the data privacy challenge -- it enables sharing of data while complying with rigorous privacy guarantees, which is essential for scientific progress in sensitive domains. Unfortunately, restricted by the inherent complexity of modeling high-dimensional distributions, existing private generative models are struggling with the utility of synthetic samples. In contrast to existing works that aim at fitting the complete data distribution, we directly optimize for a small set of samples that are representative of the distribution under the supervision of discriminative information from downstream tasks, which is generally an easier task and more suitable for private training. Our work provides an alternative view for differentially private generation of high-dimensional data and introduces a simple yet effective method that greatly improves the sample utility of state-of-the-art approaches.
* NeurIPS 2022, 19 pages
SimSCOOD: Systematic Analysis of Out-of-Distribution Behavior of Source Code Models
Oct 10, 2022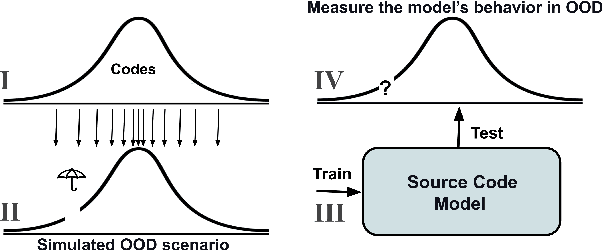

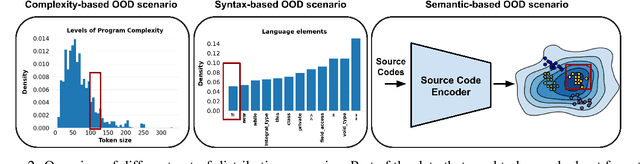
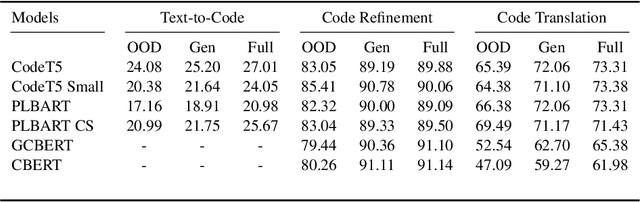
While large code datasets have become available in recent years, acquiring representative training data with full coverage of general code distribution remains challenging due to the compositional nature of code and the complexity of software. This leads to the out-of-distribution (OOD) issues with unexpected model inference behaviors that have not been systematically studied yet. We contribute the first systematic approach that simulates various OOD scenarios along different dimensions of data properties and investigates the model behaviors in such scenarios. Our extensive studies on six state-of-the-art models for three code generation tasks expose several failure modes caused by the out-of-distribution issues. It thereby provides insights and sheds light for future research in terms of generalization, robustness, and inductive biases of source code models.
UnGANable: Defending Against GAN-based Face Manipulation
Oct 03, 2022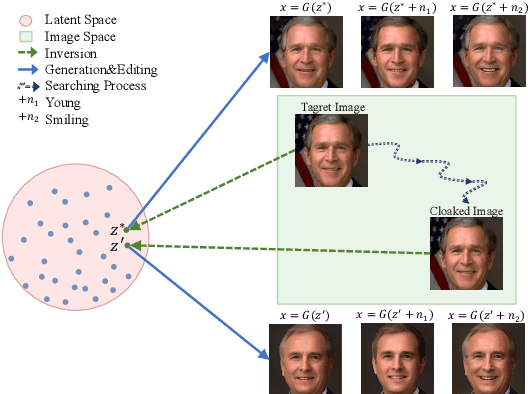

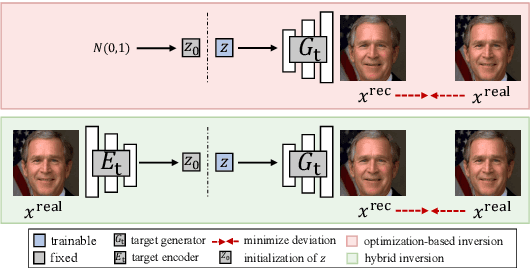
Deepfakes pose severe threats of visual misinformation to our society. One representative deepfake application is face manipulation that modifies a victim's facial attributes in an image, e.g., changing her age or hair color. The state-of-the-art face manipulation techniques rely on Generative Adversarial Networks (GANs). In this paper, we propose the first defense system, namely UnGANable, against GAN-inversion-based face manipulation. In specific, UnGANable focuses on defending GAN inversion, an essential step for face manipulation. Its core technique is to search for alternative images (called cloaked images) around the original images (called target images) in image space. When posted online, these cloaked images can jeopardize the GAN inversion process. We consider two state-of-the-art inversion techniques including optimization-based inversion and hybrid inversion, and design five different defenses under five scenarios depending on the defender's background knowledge. Extensive experiments on four popular GAN models trained on two benchmark face datasets show that UnGANable achieves remarkable effectiveness and utility performance, and outperforms multiple baseline methods. We further investigate four adaptive adversaries to bypass UnGANable and show that some of them are slightly effective.
Fact-Saboteurs: A Taxonomy of Evidence Manipulation Attacks against Fact-Verification Systems
Sep 07, 2022
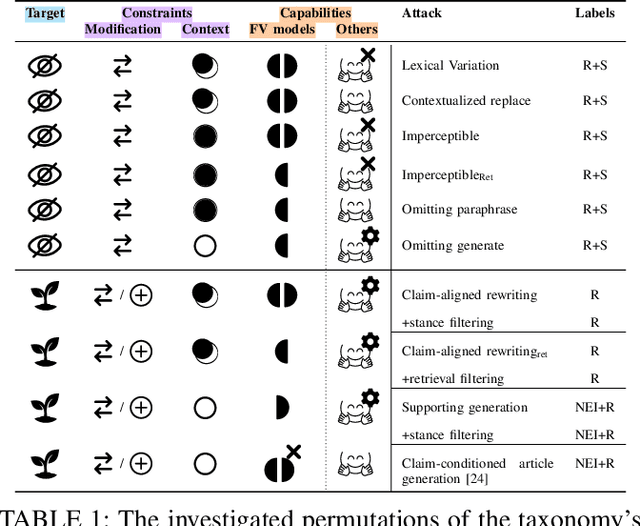
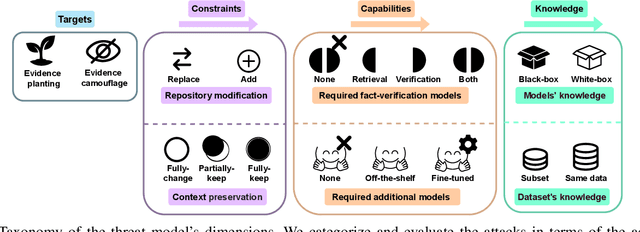
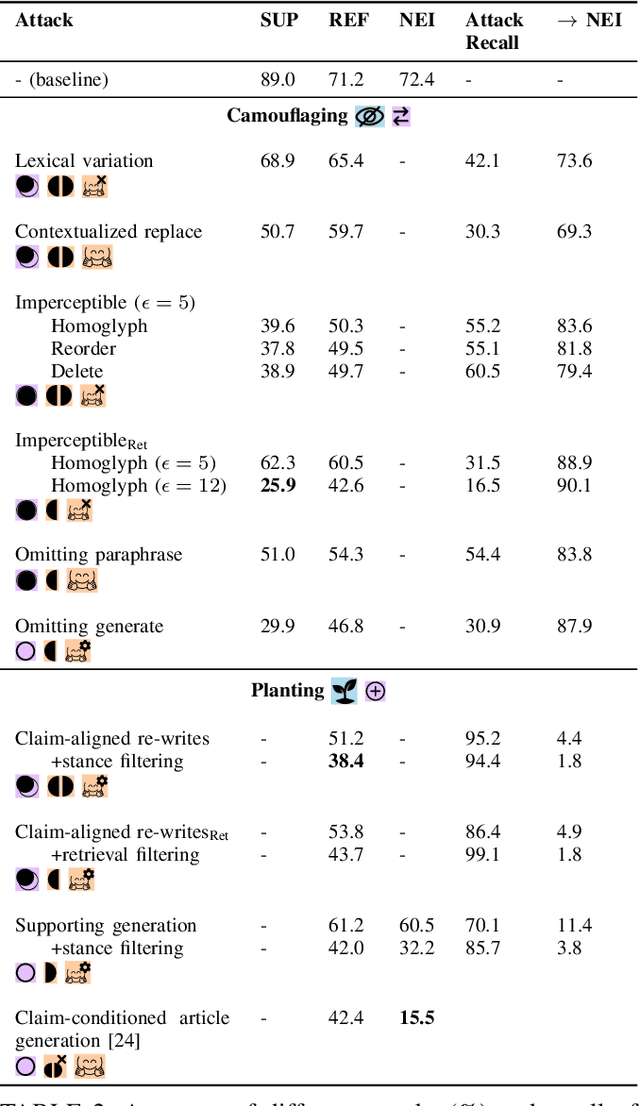
Mis- and disinformation are now a substantial global threat to our security and safety. To cope with the scale of online misinformation, one viable solution is to automate the fact-checking of claims by retrieving and verifying against relevant evidence. While major recent advances have been achieved in pushing forward the automatic fact-verification, a comprehensive evaluation of the possible attack vectors against such systems is still lacking. Particularly, the automated fact-verification process might be vulnerable to the exact disinformation campaigns it is trying to combat. In this work, we assume an adversary that automatically tampers with the online evidence in order to disrupt the fact-checking model via camouflaging the relevant evidence, or planting a misleading one. We first propose an exploratory taxonomy that spans these two targets and the different threat model dimensions. Guided by this, we design and propose several potential attack methods. We show that it is possible to subtly modify claim-salient snippets in the evidence, in addition to generating diverse and claim-aligned evidence. As a result, we highly degrade the fact-checking performance under many different permutations of the taxonomy's dimensions. The attacks are also robust against post-hoc modifications of the claim. Our analysis further hints at potential limitations in models' inference when faced with contradicting evidence. We emphasize that these attacks can have harmful implications on the inspectable and human-in-the-loop usage scenarios of such models, and we conclude by discussing challenges and directions for future defenses.
RelaxLoss: Defending Membership Inference Attacks without Losing Utility
Jul 12, 2022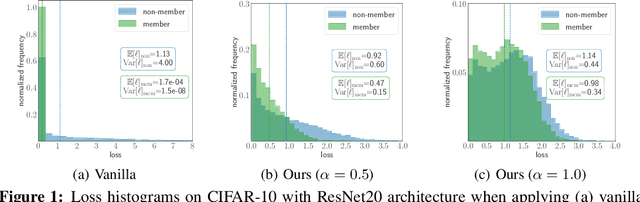

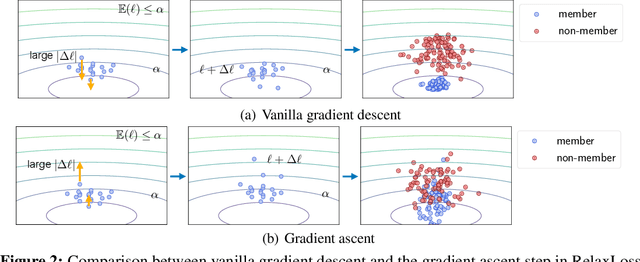
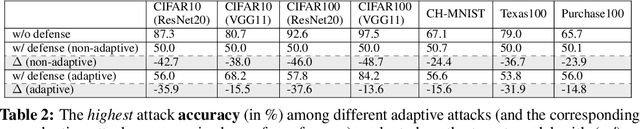
As a long-term threat to the privacy of training data, membership inference attacks (MIAs) emerge ubiquitously in machine learning models. Existing works evidence strong connection between the distinguishability of the training and testing loss distributions and the model's vulnerability to MIAs. Motivated by existing results, we propose a novel training framework based on a relaxed loss with a more achievable learning target, which leads to narrowed generalization gap and reduced privacy leakage. RelaxLoss is applicable to any classification model with added benefits of easy implementation and negligible overhead. Through extensive evaluations on five datasets with diverse modalities (images, medical data, transaction records), our approach consistently outperforms state-of-the-art defense mechanisms in terms of resilience against MIAs as well as model utility. Our defense is the first that can withstand a wide range of attacks while preserving (or even improving) the target model's utility. Source code is available at https://github.com/DingfanChen/RelaxLoss
* International Conference on Learning Representations (ICLR) 2022, 28 pages
B-cos Networks: Alignment is All We Need for Interpretability
May 20, 2022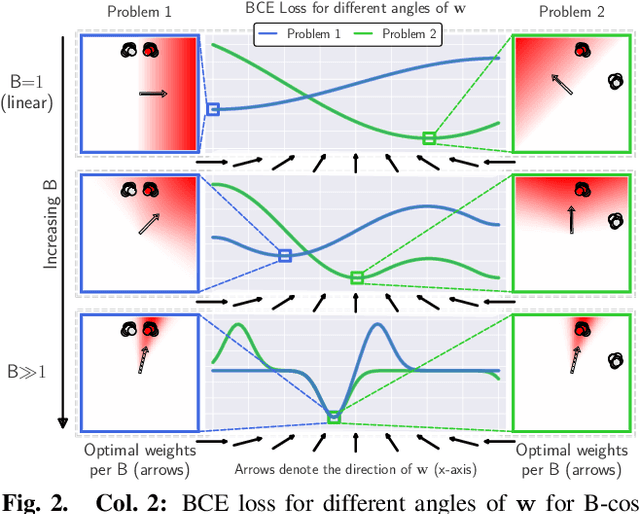
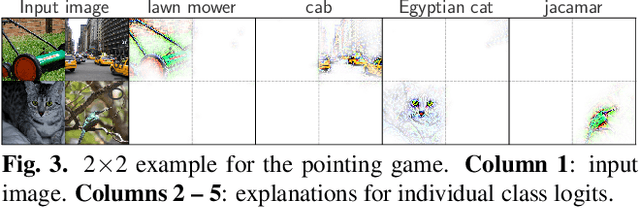
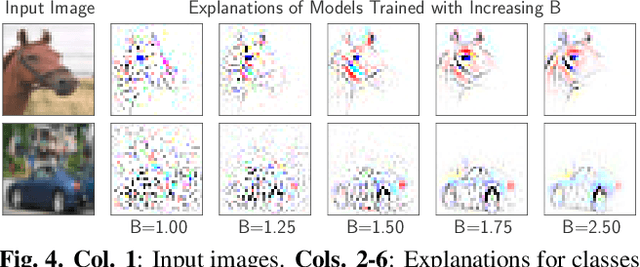
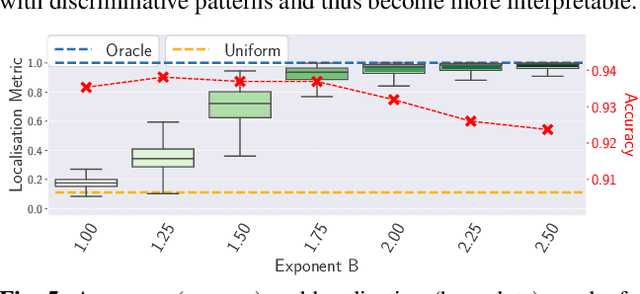
We present a new direction for increasing the interpretability of deep neural networks (DNNs) by promoting weight-input alignment during training. For this, we propose to replace the linear transforms in DNNs by our B-cos transform. As we show, a sequence (network) of such transforms induces a single linear transform that faithfully summarises the full model computations. Moreover, the B-cos transform introduces alignment pressure on the weights during optimisation. As a result, those induced linear transforms become highly interpretable and align with task-relevant features. Importantly, the B-cos transform is designed to be compatible with existing architectures and we show that it can easily be integrated into common models such as VGGs, ResNets, InceptionNets, and DenseNets, whilst maintaining similar performance on ImageNet. The resulting explanations are of high visual quality and perform well under quantitative metrics for interpretability. Code available at https://www.github.com/moboehle/B-cos.