 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Flow Variational Autoencoders for Structured Sequence Prediction
Aug 24, 2019


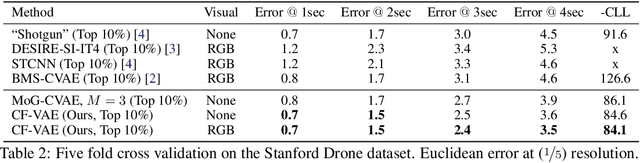
Prediction of future states of the environment and interacting agents is a key competence required for autonomous agents to operate successfully in the real world. Prior work for structured sequence prediction based on latent variable models imposes a uni-modal standard Gaussian prior on the latent variables. This induces a strong model bias which makes it challenging to fully capture the multi-modality of the distribution of the future states. In this work, we introduce Conditional Flow Variational Autoencoders which uses our novel conditional normalizing flow based prior. We show that using our novel complex multi-modal conditional prior we can capture complex multi-modal conditional distributions. Furthermore, we study for the first time latent variable collapse with normalizing flows and propose solutions to prevent such failure cases. Our experiments on three multi-modal structured sequence prediction datasets -- MNIST Sequences, Stanford Drone and HighD -- show that the proposed method obtains state of art results across different evaluation metrics.
Interpretability Beyond Classification Output: Semantic Bottleneck Networks
Jul 28, 2019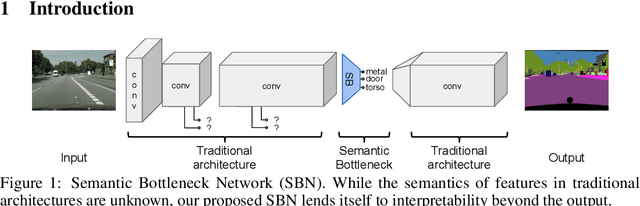
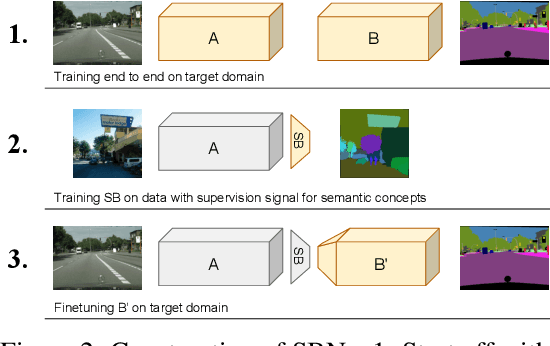
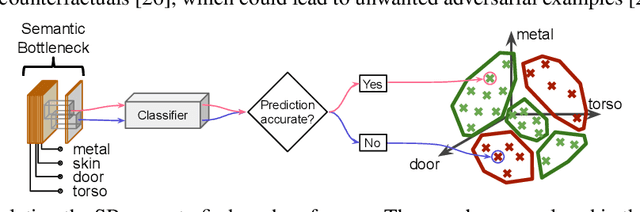

Today's deep learning systems deliver high performance based on end-to-end training. While they deliver strong performance, these systems are hard to interpret. To address this issue, we propose Semantic Bottleneck Networks (SBN): deep networks with semantically interpretable intermediate layers that all downstream results are based on. As a consequence, the analysis on what the final prediction is based on is transparent to the engineer and failure cases and modes can be analyzed and avoided by high-level reasoning. We present a case study on street scene segmentation to demonstrate the feasibility and power of SBN. In particular, we start from a well performing classic deep network which we adapt to house a SB-Layer containing task related semantic concepts (such as object-parts and materials). Importantly, we can recover state of the art performance despite a drastic dimensionality reduction from 1000s (non-semantic feature) to 10s (semantic concept) channels. Additionally we show how the activations of the SB-Layer can be used for both the interpretation of failure cases of the network as well as for confidence prediction of the resulting output. For the first time, e.g., we show interpretable segmentation results for most predictions at over 99% accuracy.
Prediction Poisoning: Utility-Constrained Defenses Against Model Stealing Attacks
Jun 26, 2019



With the advances of ML models in recent years, we are seeing an increasing number of real-world commercial applications and services e.g., autonomous vehicles, medical equipment, web APIs emerge. Recent advances in model functionality stealing attacks via black-box access (i.e., inputs in, predictions out) threaten the business model of such ML applications, which require a lot of time, money, and effort to develop. In this paper, we address the issue by studying defenses for model stealing attacks, largely motivated by a lack of effective defenses in literature. We work towards the first defense which introduces targeted perturbations to the model predictions under a utility constraint. Our approach introduces the perturbations targeted towards manipulating the training procedure of the attacker. We evaluate our approach on multiple datasets and attack scenarios across a range of utility constrains. Our results show that it is indeed possible to trade-off utility (e.g., deviation from original prediction, test accuracy) to significantly reduce effectiveness of model stealing attacks.
SampleFix: Learning to Correct Programs by Sampling Diverse Fixes
Jun 24, 2019
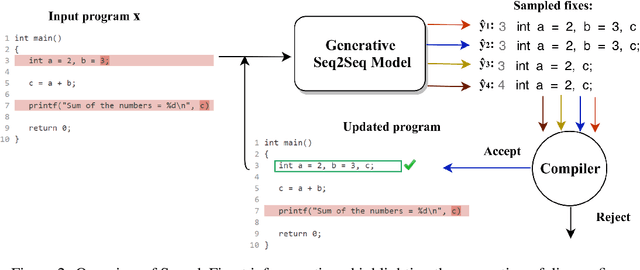
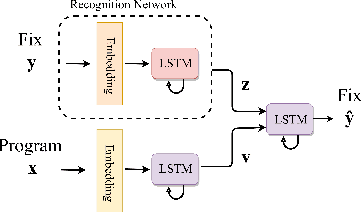

Automatic program correction is an active topic of research, which holds the potential of dramatically improving productivity of programmers during the software development process and correctness of software in general. Recent advances in machine learning, deep learning and NLP have rekindled the hope to eventually fully automate the process of repairing programs. A key challenges is ambiguity, as multiple codes -- or fixes -- can implement the same functionality. In addition, dataset by nature fail to capture the variance introduced by such ambiguities. Therefore, we propose a deep generative model to automatically correct programming errors by learning a distribution of potential fixes. Our model is formulated as a deep conditional variational autoencoder that samples diverse fixes for the given erroneous programs. In order to account for ambiguity and inherent lack of representative datasets, we propose a novel regularizer to encourage the model to generate diverse fixes. Our evaluations on common programming errors show for the first time the generation of diverse fixes and strong improvements over the state-of-the-art approaches by fixing up to $61\%$ of the mistakes.
Shape Evasion: Preventing Body Shape Inference of Multi-Stage Approaches
May 27, 2019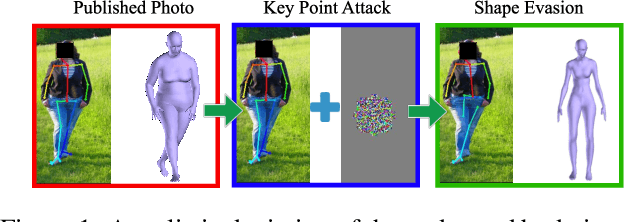



Modern approaches to pose and body shape estimation have recently achieved strong performance even under challenging real-world conditions. Even from a single image of a clothed person, a realistic looking body shape can be inferred that captures a users' weight group and body shape type well. This opens up a whole spectrum of applications -- in particular in fashion -- where virtual try-on and recommendation systems can make use of these new and automatized cues. However, a realistic depiction of the undressed body is regarded highly private and therefore might not be consented by most people. Hence, we ask if the automatic extraction of such information can be effectively evaded. While adversarial perturbations have been shown to be effective for manipulating the output of machine learning models -- in particular, end-to-end deep learning approaches -- state of the art shape estimation methods are composed of multiple stages. We perform the first investigation of different strategies that can be used to effectively manipulate the automatic shape estimation while preserving the overall appearance of the original image.
Learning Manipulation under Physics Constraints with Visual Perception
Apr 19, 2019
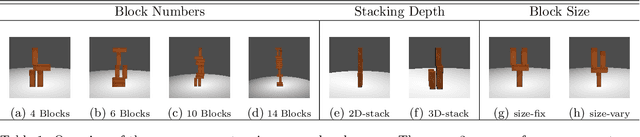
Understanding physical phenomena is a key competence that enables humans and animals to act and interact under uncertain perception in previously unseen environments containing novel objects and their configurations. In this work, we consider the problem of autonomous block stacking and explore solutions to learning manipulation under physics constraints with visual perception inherent to the task. Inspired by the intuitive physics in humans, we first present an end-to-end learning-based approach to predict stability directly from appearance, contrasting a more traditional model-based approach with explicit 3D representations and physical simulation. We study the model's behavior together with an accompanied human subject test. It is then integrated into a real-world robotic system to guide the placement of a single wood block into the scene without collapsing existing tower structure. To further automate the process of consecutive blocks stacking, we present an alternative approach where the model learns the physics constraint through the interaction with the environment, bypassing the dedicated physics learning as in the former part of this work. In particular, we are interested in the type of tasks that require the agent to reach a given goal state that may be different for every new trial. Thereby we propose a deep reinforcement learning framework that learns policies for stacking tasks which are parametrized by a target structure.
Updates-Leak: Data Set Inference and Reconstruction Attacks in Online Learning
Apr 01, 2019
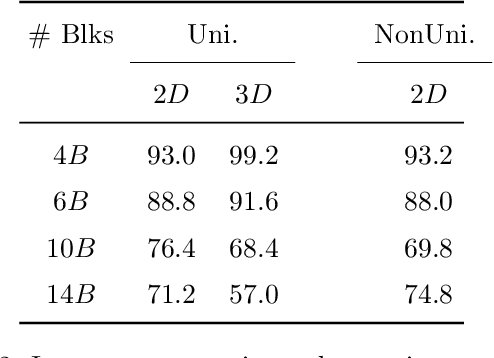
Machine learning (ML) has progressed rapidly during the past decade and the major factor that drives such development is the unprecedented large-scale data. As data generation is a continuous process, this leads to ML service providers updating their models frequently with newly-collected data in an online learning scenario. In consequence, if an ML model is queried with the same set of data samples at two different points in time, it will provide different results. In this paper, we investigate whether the change in the output of a black-box ML model before and after being updated can leak information of the dataset used to perform the update. This constitutes a new attack surface against black-box ML models and such information leakage severely damages the intellectual property and data privacy of the ML model owner/provider. In contrast to membership inference attacks, we use an encoder-decoder formulation that allows inferring diverse information ranging from detailed characteristics to full reconstruction of the dataset. Our new attacks are facilitated by state-of-the-art deep learning techniques. In particular, we propose a hybrid generative model (BM-GAN) that is based on generative adversarial networks (GANs) but includes a reconstructive loss that allows generating accurate samples. Our experiments show effective prediction of dataset characteristics and even full reconstruction in challenging conditions.
Not Using the Car to See the Sidewalk: Quantifying and Controlling the Effects of Context in Classification and Segmentation
Dec 17, 2018
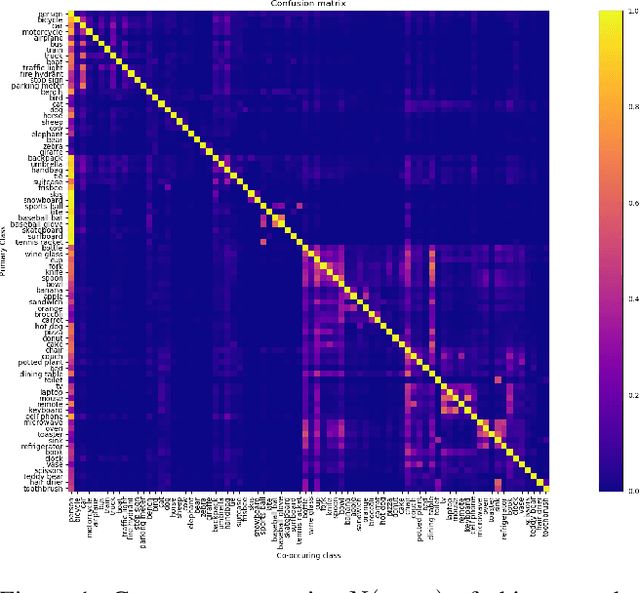

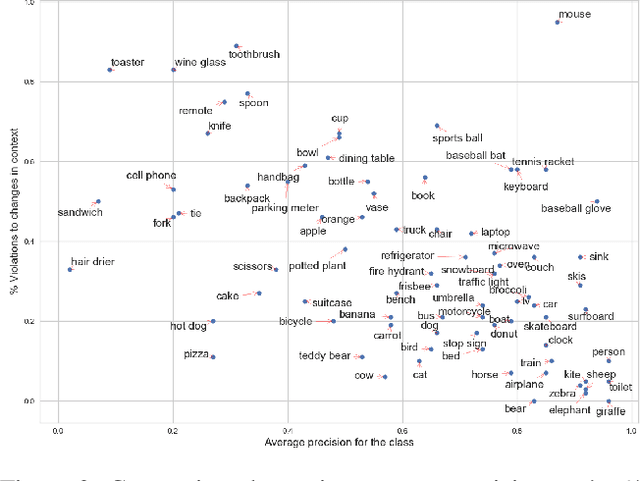
Importance of visual context in scene understanding tasks is well recognized in the computer vision community. However, to what extent the computer vision models for image classification and semantic segmentation are dependent on the context to make their predictions is unclear. A model overly relying on context will fail when encountering objects in context distributions different from training data and hence it is important to identify these dependencies before we can deploy the models in the real-world. We propose a method to quantify the sensitivity of black-box vision models to visual context by editing images to remove selected objects and measuring the response of the target models. We apply this methodology on two tasks, image classification and semantic segmentation, and discover undesirable dependency between objects and context, for example that "sidewalk" segmentation relies heavily on "cars" being present in the image. We propose an object removal based data augmentation solution to mitigate this dependency and increase the robustness of classification and segmentation models to contextual variations. Our experiments show that the proposed data augmentation helps these models improve the performance in out-of-context scenarios, while preserving the performance on regular data.
Knockoff Nets: Stealing Functionality of Black-Box Models
Dec 06, 2018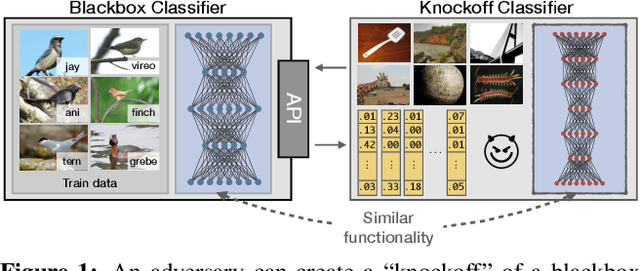

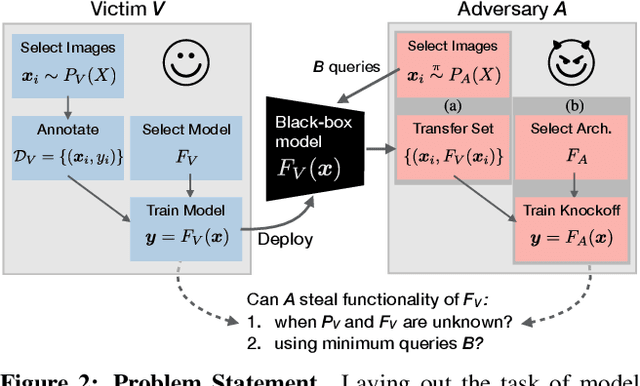

Machine Learning (ML) models are increasingly deployed in the wild to perform a wide range of tasks. In this work, we ask to what extent can an adversary steal functionality of such "victim" models based solely on blackbox interactions: image in, predictions out. In contrast to prior work, we present an adversary lacking knowledge of train/test data used by the model, its internals, and semantics over model outputs. We formulate model functionality stealing as a two-step approach: (i) querying a set of input images to the blackbox model to obtain predictions; and (ii) training a "knockoff" with queried image-prediction pairs. We make multiple remarkable observations: (a) querying random images from a different distribution than that of the blackbox training data results in a well-performing knockoff; (b) this is possible even when the knockoff is represented using a different architecture; and (c) our reinforcement learning approach additionally improves query sample efficiency in certain settings and provides performance gains. We validate model functionality stealing on a range of datasets and tasks, as well as on a popular image analysis API where we create a reasonable knockoff for as little as $30.
Attributing Fake Images to GANs: Analyzing Fingerprints in Generated Images
Nov 20, 2018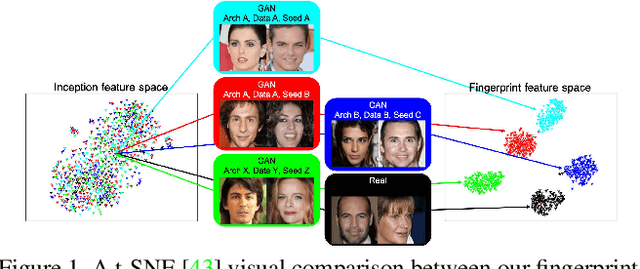
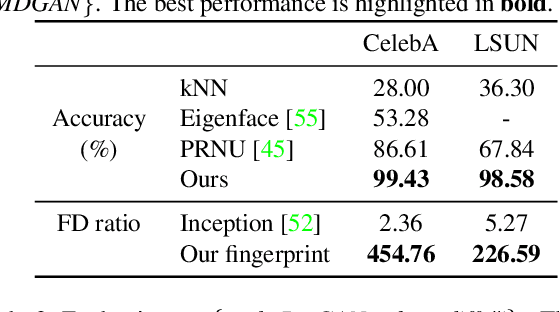
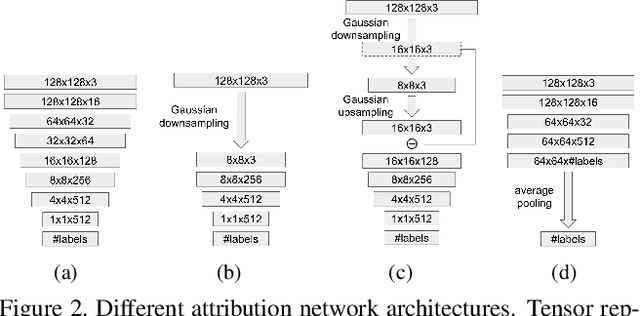
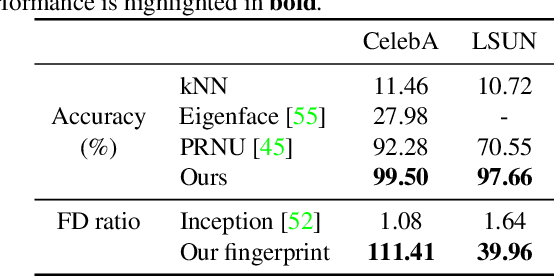
Research in computer graphics has been in pursuit of realistic image generation for a long time. Recent advances in machine learning with deep generative models have shown increasing success of closing the realism gap by using data-driven and learned components. There is an increasing concern that real and fake images will become more and more difficult to tell apart. We take a first step towards this larger research challenge by asking the question if and to what extend a generated fake image can be attribute to a particular Generative Adversarial Networks (GANs) of a certain architecture and trained with particular data and random seed. Our analysis shows single samples from GANs carry highly characteristic fingerprints which make attribution of images to GANs possible. Surprisingly, this is even possible for GANs with same architecture and same training that only differ by the training seed.