 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-specific Subnetwork Discovery in Reinforcement Learning for Autonomous Underwater Navigation
Apr 23, 2026Autonomous underwater vehicles are required to perform multiple tasks adaptively and in an explainable manner under dynamic, uncertain conditions and limited sensing, challenges that classical controllers struggle to address. This demands robust, generalizable, and inherently interpretable control policies for reliable long-term monitoring. Reinforcement learning, particularly multi-task RL, overcomes these limitations by leveraging shared representations to enable efficient adaptation across tasks and environments. However, while such policies show promising results in simulation and controlled experiments, they yet remain opaque and offer limited insight into the agent's internal decision-making, creating gaps in transparency, trust, and safety that hinder real-world deployment. The internal policy structure and task-specific specialization remain poorly understood. To address these gaps, we analyze the internal structure of a pretrained multi-task reinforcement learning network in the HoloOcean simulator for underwater navigation by identifying and comparing task-specific subnetworks responsible for navigating toward different species. We find that in a contextual multi-task reinforcement learning setting with related tasks, the network uses only about 1.5% of its weights to differentiate between tasks. Of these, approximately 85% connect the context-variable nodes in the input layer to the next hidden layer, highlighting the importance of context variables in such settings. Our approach provides insights into shared and specialized network components, useful for efficient model editing, transfer learning, and continual learning for underwater monitoring through a contextual multi-task reinforcement learning method.
DINO-Explorer: Active Underwater Discovery via Ego-Motion Compensated Semantic Predictive Coding
Apr 14, 2026Marine ecosystem degradation necessitates continuous, scientifically selective underwater monitoring. However, most autonomous underwater vehicles (AUVs) operate as passive data loggers, capturing exhaustive video for offline review and frequently missing transient events of high scientific value. Transitioning to active perception requires a causal, online signal that highlights significant phenomena while suppressing maneuver-induced visual changes. We propose DINO-Explorer, a novelty-aware perception framework driven by a continuous semantic surprise signal. Operating within the latent space of a frozen DINOv3 foundation model, it leverages a lightweight, action-conditioned recurrent predictor to anticipate short-horizon semantic evolution. An efference-copy-inspired module utilizes globally pooled optical flow to discount self-induced visual changes without suppressing genuine environmental novelty. We evaluate this signal on the downstream task of asynchronous event triage under variant telemetry constraints. Results demonstrate that DINO-Explorer provides a robust, bandwidth-efficient attention mechanism. At a fixed operating point, the system retains 78.8% of post-discovery human-reviewer consensus events with a 56.8% trigger confirmation rate, effectively surfacing mission-relevant phenomena. Crucially, ego-motion conditioning suppresses 45.5% of false positives relative to an uncompensated surprise signal baseline. In a replay-side Pareto ablation study, DINO-Explorer robustly dominates the validated peak F1 versus telemetry bandwidth frontier, reducing telemetry bandwidth by 48.2% at the selected operating point while maintaining a 62.2% peak F1 score, successfully concentrating data transmission around human-verified novelty events.
Contextual Multi-Task Reinforcement Learning for Autonomous Reef Monitoring
Apr 14, 2026Although autonomous underwater vehicles promise the capability of marine ecosystem monitoring, their deployment is fundamentally limited by the difficulty of controlling vehicles under highly uncertain and non-stationary underwater dynamics. To address these challenges, we employ a data-driven reinforcement learning approach to compensate for unknown dynamics and task variations.Traditional single-task reinforcement learning has a tendency to overfit the training environment, thus, limit the long-term usefulness of the learnt policy. Hence, we propose to use a contextual multi-task reinforcement learning paradigm instead, allowing us to learn controllers that can be reused for various tasks, e.g., detecting oysters in one reef and detecting corals in another. We evaluate whether contextual multi-task reinforcement learning can efficiently learn robust and generalisable control policies for autonomous underwater reef monitoring. We train a single context-dependent policy that is able to solve multiple related monitoring tasks in a simulated reef environment in HoloOcean. In our experiments, we empirically evaluate the contextual policies regarding sample-efficiency, zero-shot generalisation to unseen tasks, and robustness to varying water currents. By utilising multi-task reinforcement learning, we aim to improve the training effectiveness, as well as the reusability of learnt policies to take a step towards more sustainable procedures in autonomous reef monitoring.
Safety Enhancement in Planetary Rovers: Early Detection of Tip-over Risks Using Autoencoders
Aug 10, 2024Autonomous robots consistently encounter unforeseen dangerous situations during exploration missions. The characteristic rimless wheels in the AsguardIV rover allow it to overcome challenging terrains. However, steep slopes or difficult maneuvers can cause the rover to tip over and threaten the completion of a mission. This work focuses on identifying early signs or initial stages for potential tip-over events to predict and detect these critical moments before they fully occur, possibly preventing accidents and enhancing the safety and stability of the rover during its exploration mission. Inertial Measurement Units (IMU) readings are used to develop compact, robust, and efficient Autoencoders that combine the power of sequence processing of Long Short-Term Memory Networks (LSTM). By leveraging LSTM-based Autoencoders, this work contributes predictive capabilities for detecting tip-over risks and developing safety measures for more reliable exploration missions.
Results from the Robocademy ITN: Autonomy, Disturbance Rejection and Perception for Advanced Marine Robotics
Oct 29, 2019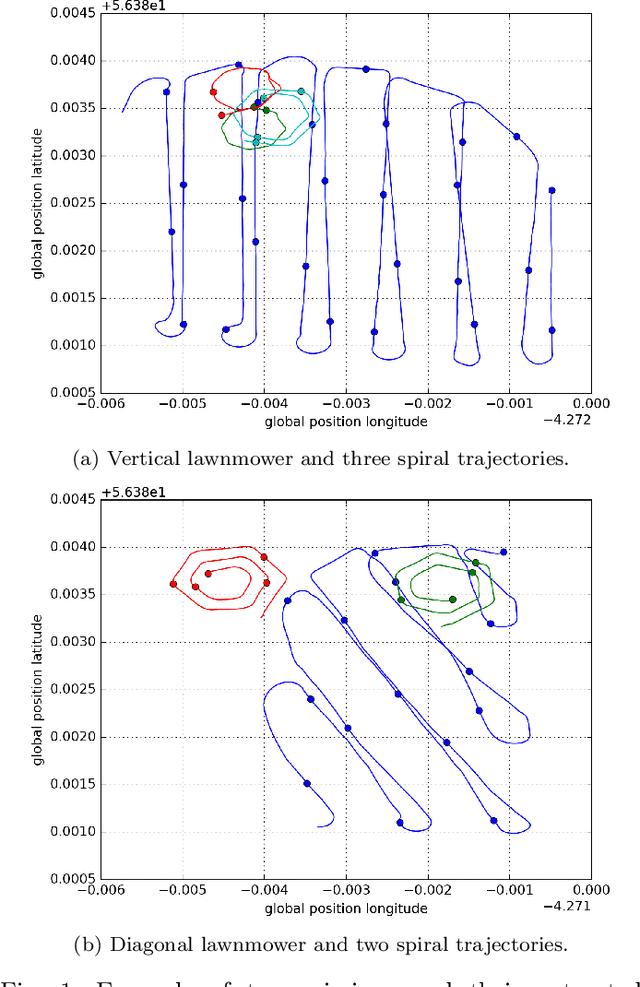
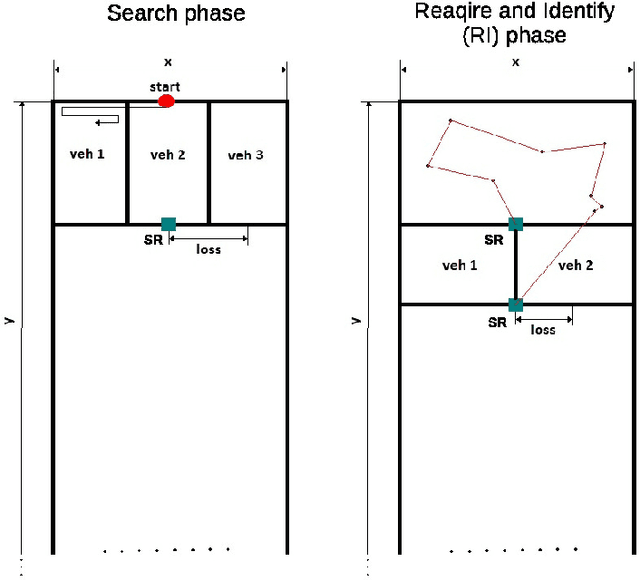


Marine and Underwater resources are important part of the economy of many countries. This requires significant financial resources into their construction and maintentance. Robotics is expected to fill this void, by automating and/or removing humans from hostile environments in order to easily perform maintenance tasks. The Robocademy Marie Sklodowska-Curie Initial Training Network was funded by the European Union's FP7 research program in order to train 13 Fellows into world-leading researchers in Marine and Underwater Robotics. The fellows developed guided research into three areas of key importance: Autonomy, Disturbance Rejection, and Perception. This paper presents a summary of the fellows' research in the three action lines. 71 scientific publications were the primary result of this project, with many other publications currently in the pipeline. Most of the fellows have found employment in Europe, which shows the high demand for this kind of experts. We believe the results from this project are already having an impact in the marine robotics industry, as key technologies are being adopted already.