 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Annotates in NLP? A Large-scale Assessment of Human Annotation Reporting between 2018 and 2025
Jun 01, 2026Human annotation is the empirical foundation of much NLP research, from dataset construction to model evaluation, but papers often leave unclear who produced the annotations and how the annotation process was controlled. We provide the first large-scale, task-level audit of human annotation reporting across major NLP venues, asking which annotation details are documented, which are missing, and how reporting varies across time, topic, venue, and intended use of human judgment. We introduce a unified taxonomy of annotation-reporting practices and validate an LLM-assisted extraction pipeline against Annotated-gold, a human-adjudicated gold standard of 41 papers and 72 annotation tasks, where the best model reaches human-comparable agreement with adjudicated labels, with Krippendorff's alpha of 0.606 versus 0.585 for human-human agreement. Using this pipeline, we construct Annotated-llm, a dataset covering ACL-venue papers from 2018-2025, with 2,667 extracted annotation tasks from 1,603 papers, and find that papers frequently report operational details such as recruitment strategies, annotator expertise, and annotation volume, but often omit details needed to assess annotation validity, including training, language proficiency, compensation, socio-demographics, adjudication, and agreement values, especially in model-evaluation studies. Our results show that annotation reporting in NLP has improved over time but remains uneven, and they establish a scalable framework and bare-minimum reporting recommendations for making human annotation more reliable, reproducible, and interpretable.
Translationese as a Rational Response to Translation Task Difficulty
Mar 12, 2026Translations systematically diverge from texts originally produced in the target language, a phenomenon widely referred to as translationese. Translationese has been attributed to production tendencies (e.g. interference, simplification), socio-cultural variables, and language-pair effects, yet a unified explanatory account is still lacking. We propose that translationese reflects cognitive load inherent in the translation task itself. We test whether observable translationese can be predicted from quantifiable measures of translation task difficulty. Translationese is operationalised as a segment-level translatedness score produced by an automatic classifier. Translation task difficulty is conceptualised as comprising source-text and cross-lingual transfer components, operationalised mainly through information-theoretic metrics based on LLM surprisal, complemented by established syntactic and semantic alternatives. We use a bidirectional English-German corpus comprising written and spoken subcorpora. Results indicate that translationese can be partly explained by translation task difficulty, especially in English-to-German. For most experiments, cross-lingual transfer difficulty contributes more than source-text complexity. Information-theoretic indicators match or outperform traditional features in written mode, but offer no advantage in spoken mode. Source-text syntactic complexity and translation-solution entropy emerged as the strongest predictors of translationese across language pairs and modes.
EPIC-EuroParl-UdS: Information-Theoretic Perspectives on Translation and Interpreting
Mar 10, 2026This paper introduces an updated and combined version of the bidirectional English-German EPIC-UdS (spoken) and EuroParl-UdS (written) corpora containing original European Parliament speeches as well as their translations and interpretations. The new version corrects metadata and text errors identified through previous use, refines the content, updates linguistic annotations, and adds new layers, including word alignment and word-level surprisal indices. The combined resource is designed to support research using information-theoretic approaches to language variation, particularly studies comparing written and spoken modes, and examining disfluencies in speech, as well as traditional translationese studies, including parallel (source vs. target) and comparable (original vs. translated) analyses. The paper outlines the updates introduced in this release, summarises previous results based on the corpus, and presents a new illustrative study. The study validates the integrity of the rebuilt spoken data and evaluates probabilistic measures derived from base and fine-tuned GPT-2 and machine translation models on the task of filler particles prediction in interpreting.
Size vs. Structure in Training Corpora for Word Embedding Models: Araneum Russicum Maximum and Russian National Corpus
Jan 19, 2018


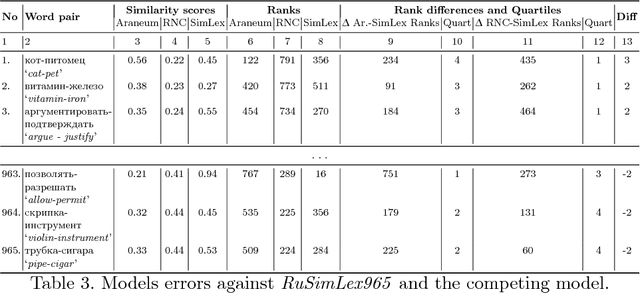
In this paper, we present a distributional word embedding model trained on one of the largest available Russian corpora: Araneum Russicum Maximum (over 10 billion words crawled from the web). We compare this model to the model trained on the Russian National Corpus (RNC). The two corpora are much different in their size and compilation procedures. We test these differences by evaluating the trained models against the Russian part of the Multilingual SimLex999 semantic similarity dataset. We detect and describe numerous issues in this dataset and publish a new corrected version. Aside from the already known fact that the RNC is generally a better training corpus than web corpora, we enumerate and explain fine differences in how the models process semantic similarity task, what parts of the evaluation set are difficult for particular models and why. Additionally, the learning curves for both models are described, showing that the RNC is generally more robust as training material for this task.