 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Explanations, Fairness, and Appropriate Reliance in Human-AI Decision-Making
Sep 23, 2022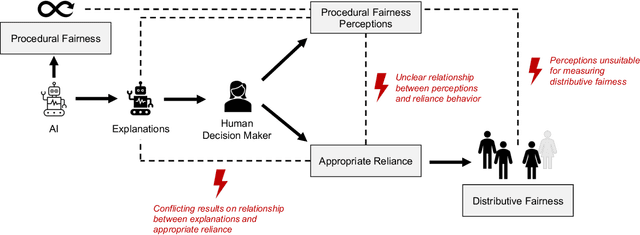



Explanations have been framed as an essential feature for better and fairer human-AI decision-making. In the context of fairness, this has not been appropriately studied, as prior works have mostly evaluated explanations based on their effects on people's perceptions. We argue, however, that for explanations to promote fairer decisions, they must enable humans to discern correct and wrong AI recommendations. To validate our conceptual arguments, we conduct an empirical study to examine the relationship between explanations, fairness perceptions, and reliance behavior. Our findings show that explanations influence people's fairness perceptions, which, in turn, affect reliance. However, we observe that low fairness perceptions lead to more overrides of AI recommendations, regardless of whether they are correct or wrong. This (i) raises doubts about the usefulness of existing explanations for enhancing distributive fairness, and, (ii) makes an important case for why perceptions must not be confused as a proxy for appropriate reliance.
Imputation Strategies Under Clinical Presence: Impact on Algorithmic Fairness
Aug 13, 2022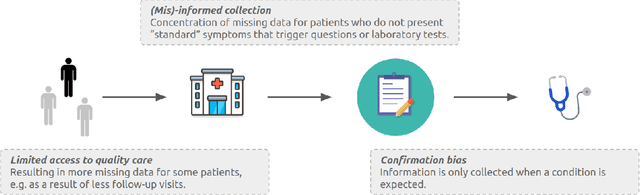
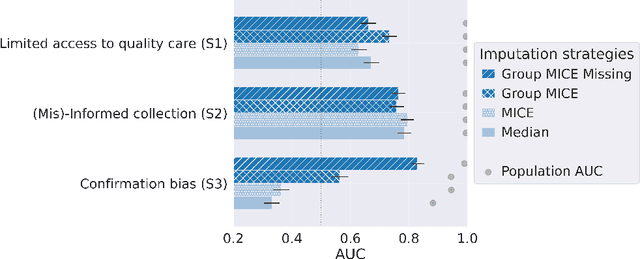
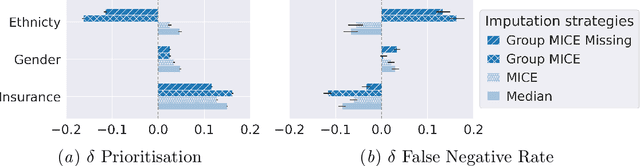
Biases have marked medical history, leading to unequal care affecting marginalised groups. The patterns of missingness in observational data often reflect these group discrepancies, but the algorithmic fairness implications of group-specific missingness are not well understood. Despite its potential impact, imputation is too often a forgotten preprocessing step. At best, practitioners guide imputation choice by optimising overall performance, ignoring how this preprocessing can reinforce inequities. Our work questions this choice by studying how imputation affects downstream algorithmic fairness. First, we provide a structured view of the relationship between clinical presence mechanisms and group-specific missingness patterns. Then, through simulations and real-world experiments, we demonstrate that the imputation choice influences marginalised group performance and that no imputation strategy consistently reduces disparities. Importantly, our results show that current practices may endanger health equity as similarly performing imputation strategies at the population level can affect marginalised groups in different ways. Finally, we propose recommendations for mitigating inequity stemming from a neglected step of the machine learning pipeline.
Toward Supporting Perceptual Complementarity in Human-AI Collaboration via Reflection on Unobservables
Jul 28, 2022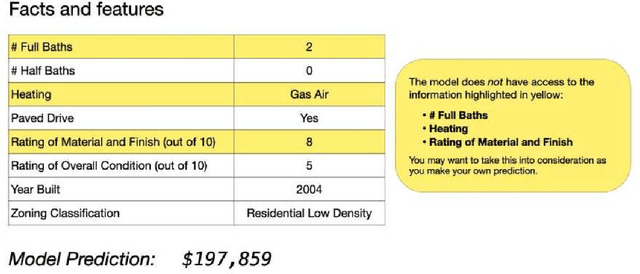
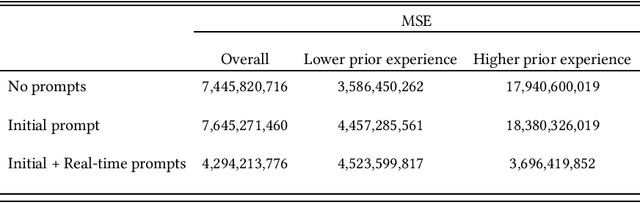
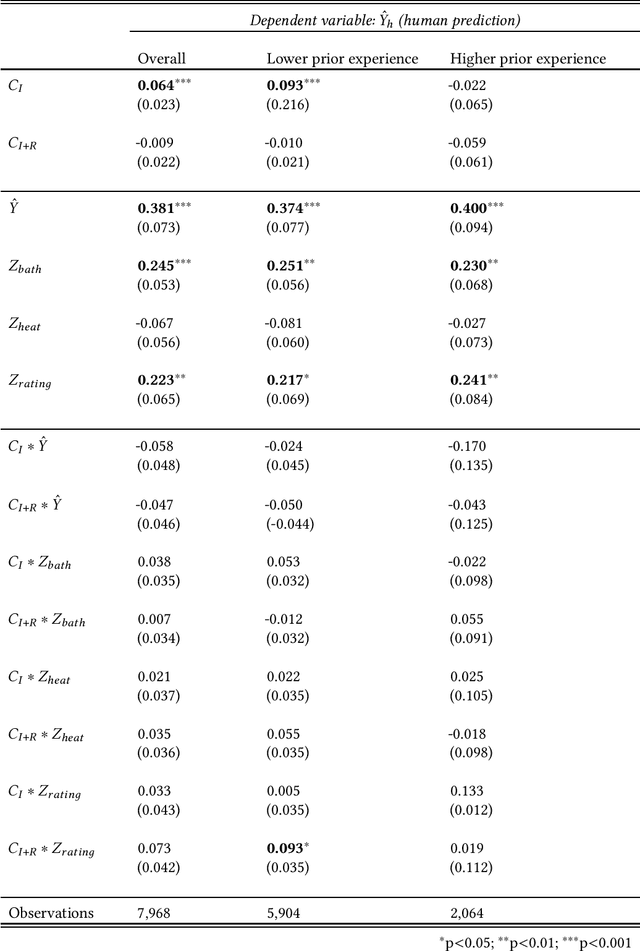

In many real world contexts, successful human-AI collaboration requires humans to productively integrate complementary sources of information into AI-informed decisions. However, in practice human decision-makers often lack understanding of what information an AI model has access to in relation to themselves. There are few available guidelines regarding how to effectively communicate about unobservables: features that may influence the outcome, but which are unavailable to the model. In this work, we conducted an online experiment to understand whether and how explicitly communicating potentially relevant unobservables influences how people integrate model outputs and unobservables when making predictions. Our findings indicate that presenting prompts about unobservables can change how humans integrate model outputs and unobservables, but do not necessarily lead to improved performance. Furthermore, the impacts of these prompts can vary depending on decision-makers' prior domain expertise. We conclude by discussing implications for future research and design of AI-based decision support tools.
Algorithmic Fairness in Business Analytics: Directions for Research and Practice
Jul 22, 2022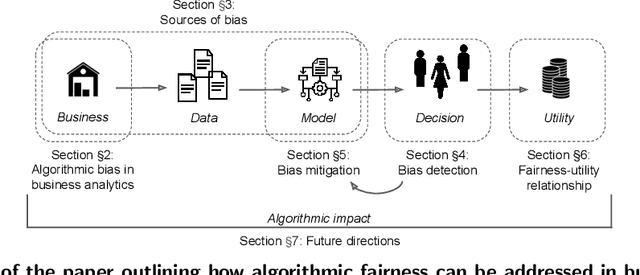

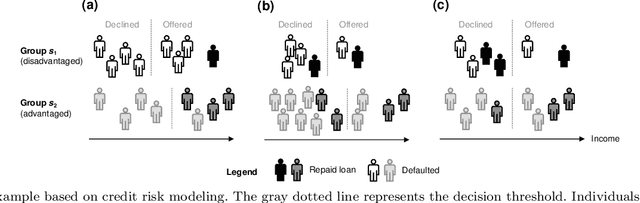
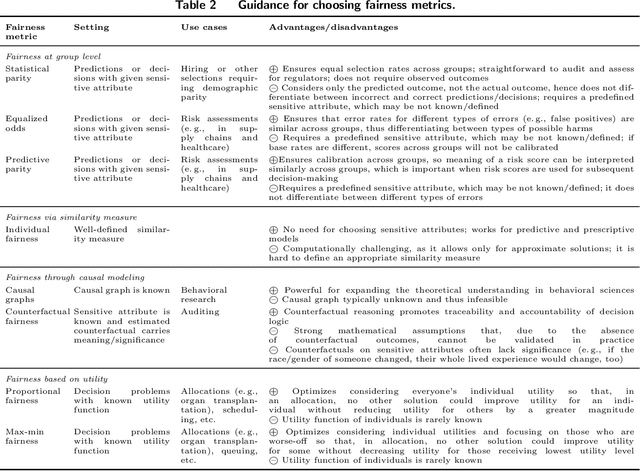
The extensive adoption of business analytics (BA) has brought financial gains and increased efficiencies. However, these advances have simultaneously drawn attention to rising legal and ethical challenges when BA inform decisions with fairness implications. As a response to these concerns, the emerging study of algorithmic fairness deals with algorithmic outputs that may result in disparate outcomes or other forms of injustices for subgroups of the population, especially those who have been historically marginalized. Fairness is relevant on the basis of legal compliance, social responsibility, and utility; if not adequately and systematically addressed, unfair BA systems may lead to societal harms and may also threaten an organization's own survival, its competitiveness, and overall performance. This paper offers a forward-looking, BA-focused review of algorithmic fairness. We first review the state-of-the-art research on sources and measures of bias, as well as bias mitigation algorithms. We then provide a detailed discussion of the utility-fairness relationship, emphasizing that the frequent assumption of a trade-off between these two constructs is often mistaken or short-sighted. Finally, we chart a path forward by identifying opportunities for business scholars to address impactful, open challenges that are key to the effective and responsible deployment of BA.
More Data Can Lead Us Astray: Active Data Acquisition in the Presence of Label Bias
Jul 15, 2022
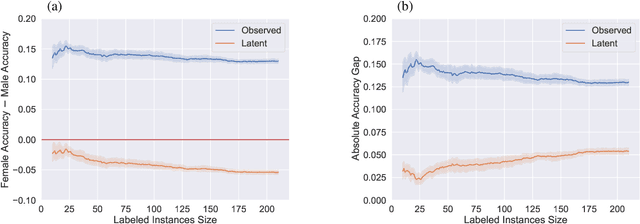
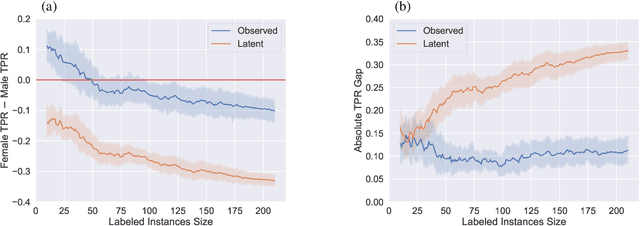
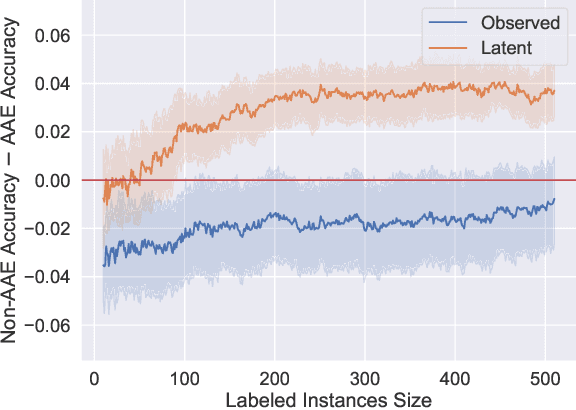
An increased awareness concerning risks of algorithmic bias has driven a surge of efforts around bias mitigation strategies. A vast majority of the proposed approaches fall under one of two categories: (1) imposing algorithmic fairness constraints on predictive models, and (2) collecting additional training samples. Most recently and at the intersection of these two categories, methods that propose active learning under fairness constraints have been developed. However, proposed bias mitigation strategies typically overlook the bias presented in the observed labels. In this work, we study fairness considerations of active data collection strategies in the presence of label bias. We first present an overview of different types of label bias in the context of supervised learning systems. We then empirically show that, when overlooking label bias, collecting more data can aggravate bias, and imposing fairness constraints that rely on the observed labels in the data collection process may not address the problem. Our results illustrate the unintended consequences of deploying a model that attempts to mitigate a single type of bias while neglecting others, emphasizing the importance of explicitly differentiating between the types of bias that fairness-aware algorithms aim to address, and highlighting the risks of neglecting label bias during data collection.
Doubting AI Predictions: Influence-Driven Second Opinion Recommendation
Apr 29, 2022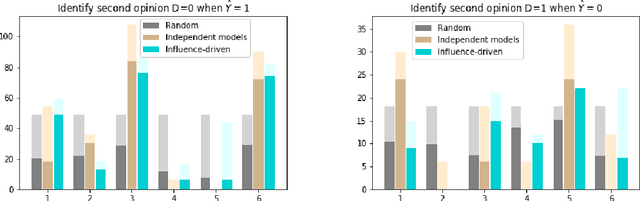
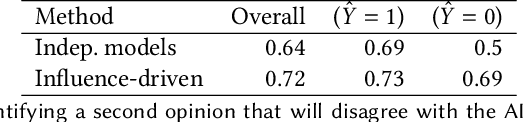
Effective human-AI collaboration requires a system design that provides humans with meaningful ways to make sense of and critically evaluate algorithmic recommendations. In this paper, we propose a way to augment human-AI collaboration by building on a common organizational practice: identifying experts who are likely to provide complementary opinions. When machine learning algorithms are trained to predict human-generated assessments, experts' rich multitude of perspectives is frequently lost in monolithic algorithmic recommendations. The proposed approach aims to leverage productive disagreement by (1) identifying whether some experts are likely to disagree with an algorithmic assessment and, if so, (2) recommend an expert to request a second opinion from.
Justice in Misinformation Detection Systems: An Analysis of Algorithms, Stakeholders, and Potential Harms
Apr 29, 2022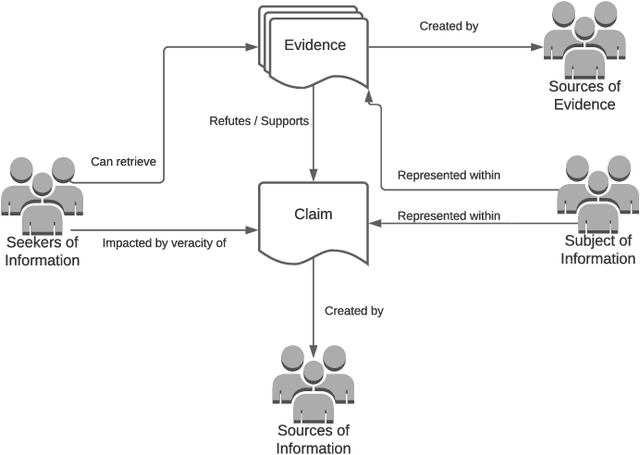
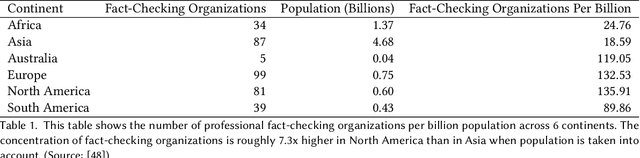
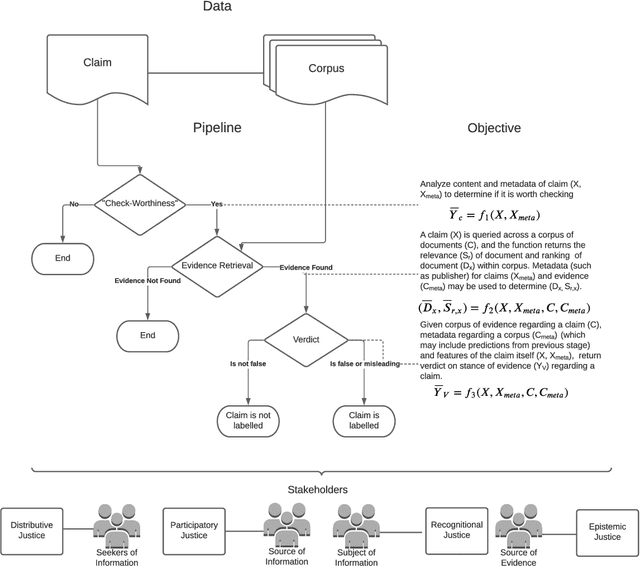
Faced with the scale and surge of misinformation on social media, many platforms and fact-checking organizations have turned to algorithms for automating key parts of misinformation detection pipelines. While offering a promising solution to the challenge of scale, the ethical and societal risks associated with algorithmic misinformation detection are not well-understood. In this paper, we employ and extend upon the notion of informational justice to develop a framework for explicating issues of justice relating to representation, participation, distribution of benefits and burdens, and credibility in the misinformation detection pipeline. Drawing on the framework: (1) we show how injustices materialize for stakeholders across three algorithmic stages in the pipeline; (2) we suggest empirical measures for assessing these injustices; and (3) we identify potential sources of these harms. This framework should help researchers, policymakers, and practitioners reason about potential harms or risks associated with these algorithms and provide conceptual guidance for the design of algorithmic fairness audits in this domain.
On the Relationship Between Explanations, Fairness Perceptions, and Decisions
Apr 29, 2022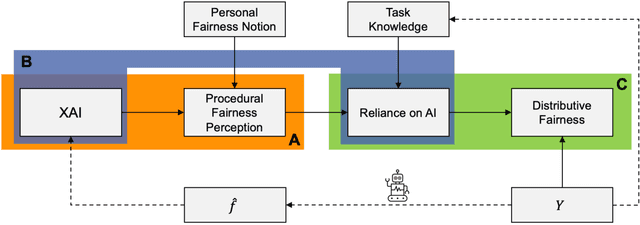
It is known that recommendations of AI-based systems can be incorrect or unfair. Hence, it is often proposed that a human be the final decision-maker. Prior work has argued that explanations are an essential pathway to help human decision-makers enhance decision quality and mitigate bias, i.e., facilitate human-AI complementarity. For these benefits to materialize, explanations should enable humans to appropriately rely on AI recommendations and override the algorithmic recommendation when necessary to increase distributive fairness of decisions. The literature, however, does not provide conclusive empirical evidence as to whether explanations enable such complementarity in practice. In this work, we (a) provide a conceptual framework to articulate the relationships between explanations, fairness perceptions, reliance, and distributive fairness, (b) apply it to understand (seemingly) contradictory research findings at the intersection of explanations and fairness, and (c) derive cohesive implications for the formulation of research questions and the design of experiments.
Social Norm Bias: Residual Harms of Fairness-Aware Algorithms
Aug 29, 2021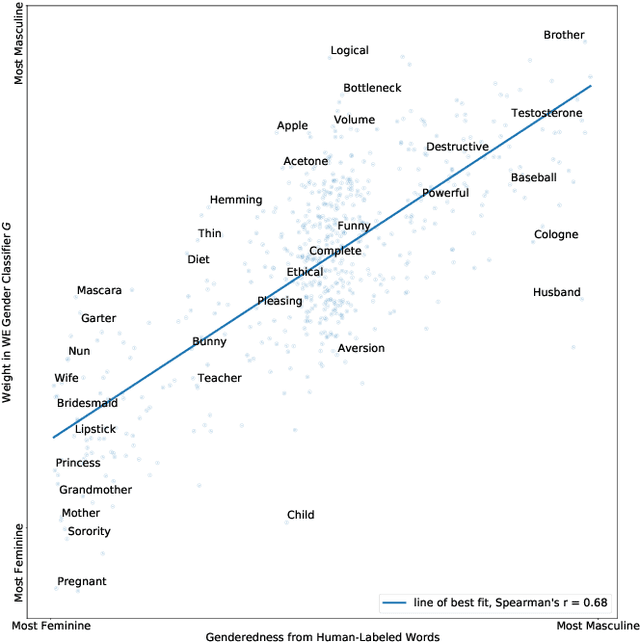
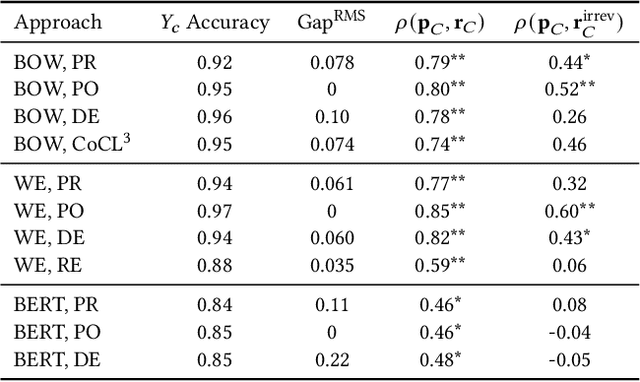
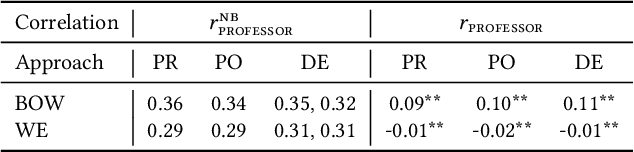
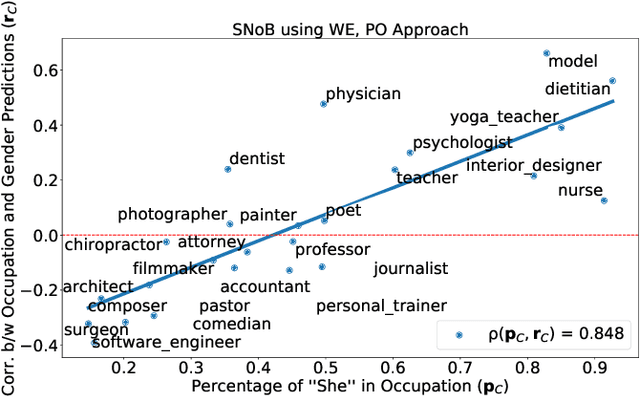
Many modern learning algorithms mitigate bias by enforcing fairness across coarsely-defined groups related to a sensitive attribute like gender or race. However, the same algorithms seldom account for the within-group biases that arise due to the heterogeneity of group members. In this work, we characterize Social Norm Bias (SNoB), a subtle but consequential type of discrimination that may be exhibited by automated decision-making systems, even when these systems achieve group fairness objectives. We study this issue through the lens of gender bias in occupation classification from biographies. We quantify SNoB by measuring how an algorithm's predictions are associated with conformity to gender norms, which is measured using a machine learning approach. This framework reveals that for classification tasks related to male-dominated occupations, fairness-aware classifiers favor biographies written in ways that align with masculine gender norms. We compare SNoB across fairness intervention techniques and show that post-processing interventions do not mitigate this type of bias at all.
The effect of differential victim crime reporting on predictive policing systems
Feb 04, 2021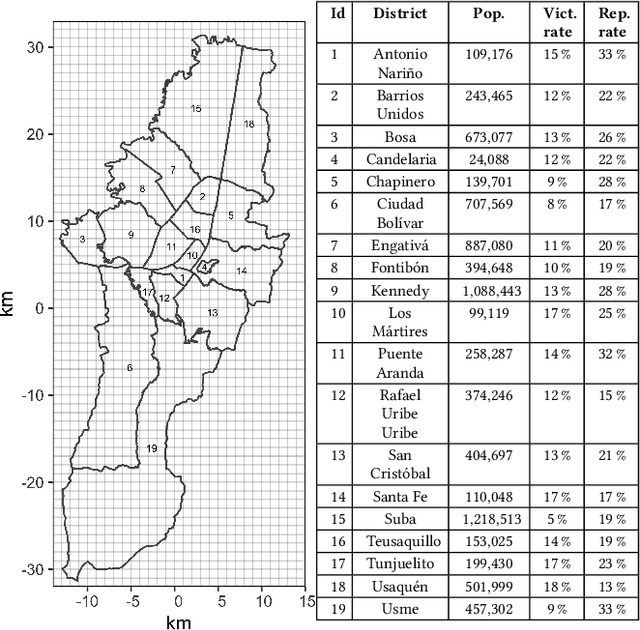
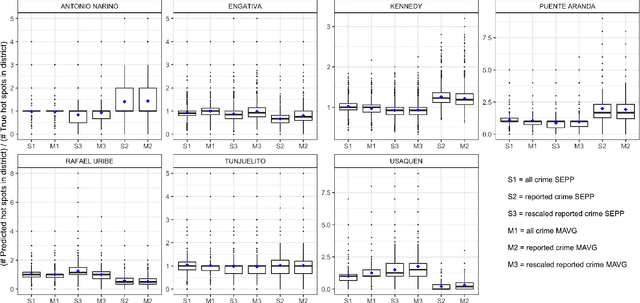
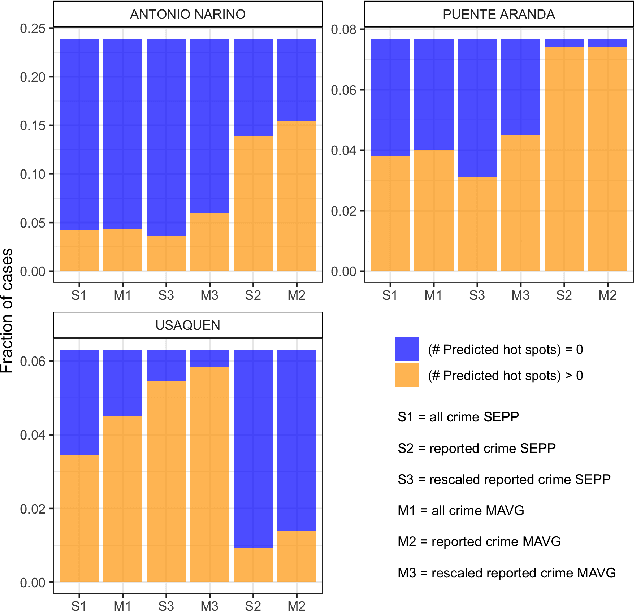
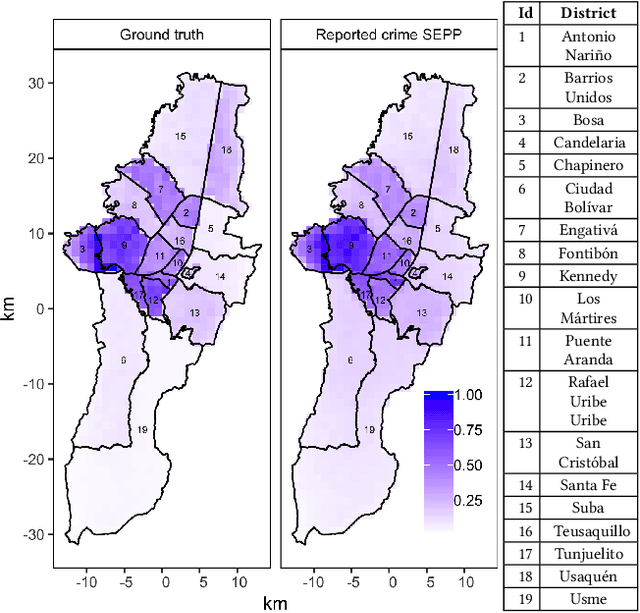
Police departments around the world have been experimenting with forms of place-based data-driven proactive policing for over two decades. Modern incarnations of such systems are commonly known as hot spot predictive policing. These systems predict where future crime is likely to concentrate such that police can allocate patrols to these areas and deter crime before it occurs. Previous research on fairness in predictive policing has concentrated on the feedback loops which occur when models are trained on discovered crime data, but has limited implications for models trained on victim crime reporting data. We demonstrate how differential victim crime reporting rates across geographical areas can lead to outcome disparities in common crime hot spot prediction models. Our analysis is based on a simulation patterned after district-level victimization and crime reporting survey data for Bogot\'a, Colombia. Our results suggest that differential crime reporting rates can lead to a displacement of predicted hotspots from high crime but low reporting areas to high or medium crime and high reporting areas. This may lead to misallocations both in the form of over-policing and under-policing.