 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: A Design Framework for Open-Source Foundation Model Safety
Jun 14, 2024


The rapid advancement of open-source foundation models has brought transparency and accessibility to this groundbreaking technology. However, this openness has also enabled the development of highly-capable, unsafe models, as exemplified by recent instances such as WormGPT and FraudGPT, which are specifically designed to facilitate criminal activity. As the capabilities of open foundation models continue to grow, potentially outpacing those of closed-source models, the risk of misuse by bad actors poses an increasingly serious threat to society. This paper addresses the critical question of how open foundation model developers should approach model safety in light of these challenges. Our analysis reveals that open-source foundation model companies often provide less restrictive acceptable use policies (AUPs) compared to their closed-source counterparts, likely due to the inherent difficulties in enforcing such policies once the models are released. To tackle this issue, we introduce PRISM, a design framework for open-source foundation model safety that emphasizes Private, Robust, Independent Safety measures, at Minimal marginal cost of compute. The PRISM framework proposes the use of modular functions that moderate prompts and outputs independently of the core language model, offering a more adaptable and resilient approach to safety compared to the brittle reinforcement learning methods currently used for value alignment. By focusing on identifying AUP violations and engaging the developer community in establishing consensus around safety design decisions, PRISM aims to create a safer open-source ecosystem that maximizes the potential of these powerful technologies while minimizing the risks to individuals and society as a whole.
Diverse, but Divisive: LLMs Can Exaggerate Gender Differences in Opinion Related to Harms of Misinformation
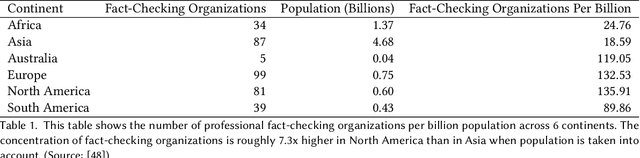
Jan 29, 2024The pervasive spread of misinformation and disinformation poses a significant threat to society. Professional fact-checkers play a key role in addressing this threat, but the vast scale of the problem forces them to prioritize their limited resources. This prioritization may consider a range of factors, such as varying risks of harm posed to specific groups of people. In this work, we investigate potential implications of using a large language model (LLM) to facilitate such prioritization. Because fact-checking impacts a wide range of diverse segments of society, it is important that diverse views are represented in the claim prioritization process. This paper examines whether a LLM can reflect the views of various groups when assessing the harms of misinformation, focusing on gender as a primary variable. We pose two central questions: (1) To what extent do prompts with explicit gender references reflect gender differences in opinion in the United States on topics of social relevance? and (2) To what extent do gender-neutral prompts align with gendered viewpoints on those topics? To analyze these questions, we present the TopicMisinfo dataset, containing 160 fact-checked claims from diverse topics, supplemented by nearly 1600 human annotations with subjective perceptions and annotator demographics. Analyzing responses to gender-specific and neutral prompts, we find that GPT 3.5-Turbo reflects empirically observed gender differences in opinion but amplifies the extent of these differences. These findings illuminate AI's complex role in moderating online communication, with implications for fact-checkers, algorithm designers, and the use of crowd-workers as annotators. We also release the TopicMisinfo dataset to support continuing research in the community.
Justice in Misinformation Detection Systems: An Analysis of Algorithms, Stakeholders, and Potential Harms
Apr 29, 2022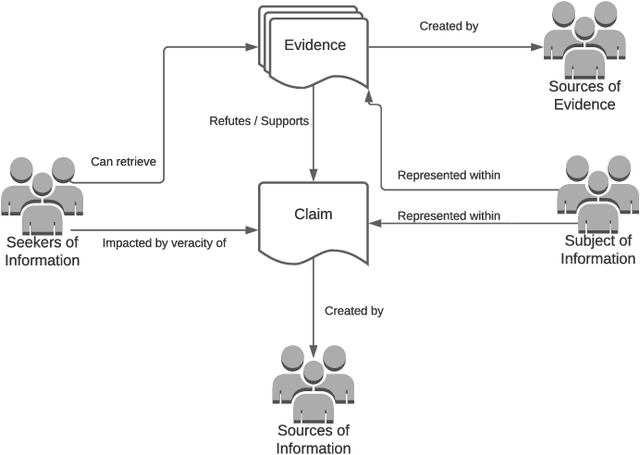
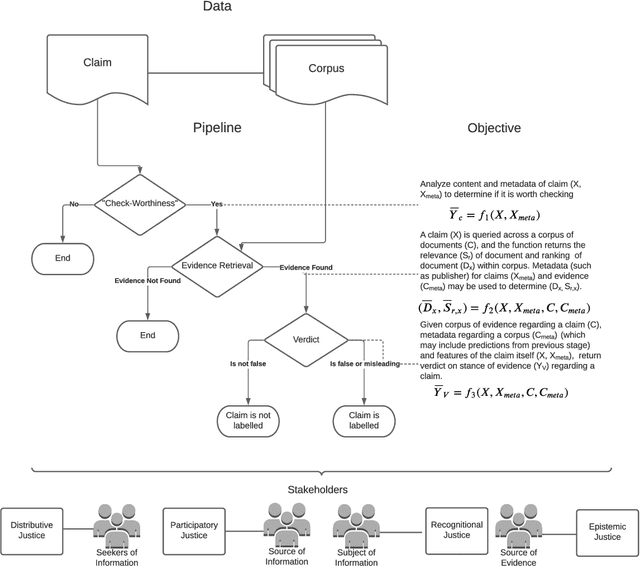
Faced with the scale and surge of misinformation on social media, many platforms and fact-checking organizations have turned to algorithms for automating key parts of misinformation detection pipelines. While offering a promising solution to the challenge of scale, the ethical and societal risks associated with algorithmic misinformation detection are not well-understood. In this paper, we employ and extend upon the notion of informational justice to develop a framework for explicating issues of justice relating to representation, participation, distribution of benefits and burdens, and credibility in the misinformation detection pipeline. Drawing on the framework: (1) we show how injustices materialize for stakeholders across three algorithmic stages in the pipeline; (2) we suggest empirical measures for assessing these injustices; and (3) we identify potential sources of these harms. This framework should help researchers, policymakers, and practitioners reason about potential harms or risks associated with these algorithms and provide conceptual guidance for the design of algorithmic fairness audits in this domain.