 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Extended Sequence Tagging Vocabulary for Grammatical Error Correction
Feb 12, 2023We extend a current sequence-tagging approach to Grammatical Error Correction (GEC) by introducing specialised tags for spelling correction and morphological inflection using the SymSpell and LemmInflect algorithms. Our approach improves generalisation: the proposed new tagset allows a smaller number of tags to correct a larger range of errors. Our results show a performance improvement both overall and in the targeted error categories. We further show that ensembles trained with our new tagset outperform those trained with the baseline tagset on the public BEA benchmark.
Probing for targeted syntactic knowledge through grammatical error detection
Oct 28, 2022



Targeted studies testing knowledge of subject-verb agreement (SVA) indicate that pre-trained language models encode syntactic information. We assert that if models robustly encode subject-verb agreement, they should be able to identify when agreement is correct and when it is incorrect. To that end, we propose grammatical error detection as a diagnostic probe to evaluate token-level contextual representations for their knowledge of SVA. We evaluate contextual representations at each layer from five pre-trained English language models: BERT, XLNet, GPT-2, RoBERTa, and ELECTRA. We leverage public annotated training data from both English second language learners and Wikipedia edits, and report results on manually crafted stimuli for subject-verb agreement. We find that masked language models linearly encode information relevant to the detection of SVA errors, while the autoregressive models perform on par with our baseline. However, we also observe a divergence in performance when probes are trained on different training sets, and when they are evaluated on different syntactic constructions, suggesting the information pertaining to SVA error detection is not robustly encoded.
Logical Reasoning with Span Predictions: Span-level Logical Atoms for Interpretable and Robust NLI Models
May 23, 2022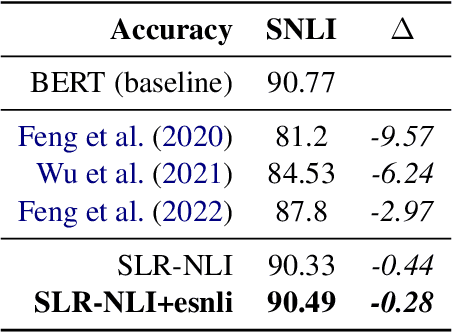

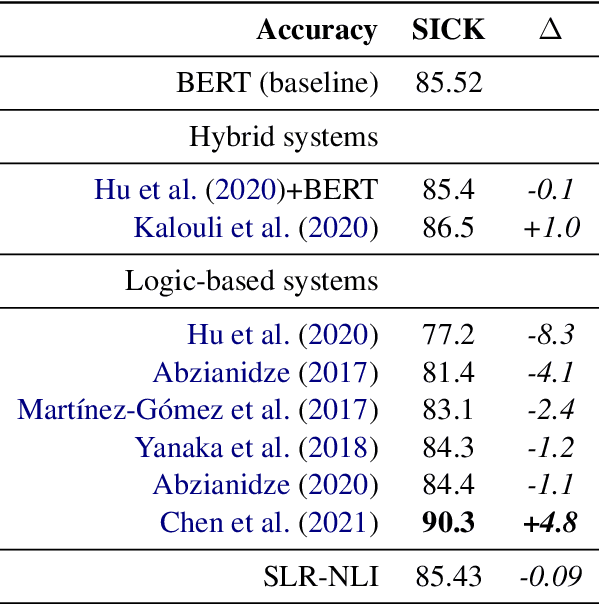
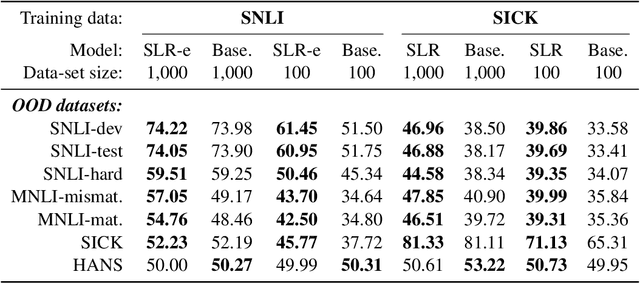
Current Natural Language Inference (NLI) models achieve impressive results, sometimes outperforming humans when evaluating on in-distribution test sets. However, as these models are known to learn from annotation artefacts and dataset biases, it is unclear to what extent the models are learning the task of NLI instead of learning from shallow heuristics in their training data. We address this issue by introducing a logical reasoning framework for NLI, creating highly transparent model decisions that are based on logical rules. Unlike prior work, we show that the improved interpretability can be achieved without decreasing the predictive accuracy. We almost fully retain performance on SNLI while identifying the exact hypothesis spans that are responsible for each model prediction. Using the e-SNLI human explanations, we also verify that our model makes sensible decisions at a span level, despite not using any span-level labels during training. We can further improve model performance and the span-level decisions by using the e-SNLI explanations during training. Finally, our model outperforms its baseline in a reduced data setting. When training with only 100 examples, in-distribution performance improves by 18%, while out-of-distribution performance improves on SNLI-hard, MNLI-mismatched, MNLI-matched and SICK by 11%, 26%, 22%, and 21% respectively.
Control Prefixes for Text Generation
Oct 15, 2021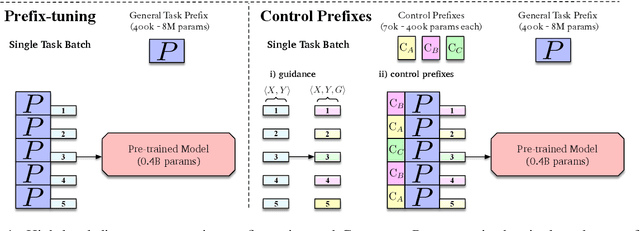
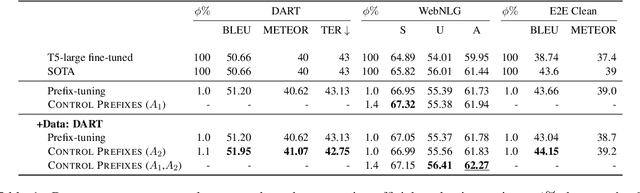
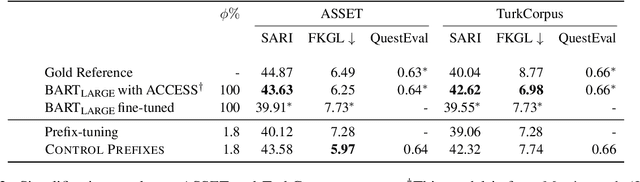
Prompt learning methods adapt pre-trained language models to downstream applications by using a task-specific prompt together with the input. Most of the current work on prompt learning in text generation relies on a shared dataset-level prompt for all examples in the dataset. We extend this approach and propose a dynamic method, Control Prefixes, which allows for the inclusion of conditional input-dependent information in each prompt. Control Prefixes is at the intersection of prompt learning and controlled generation, empowering the model to have finer-grained control during text generation. The method incorporates attribute-level learnable representations into different layers of a pre-trained transformer, allowing for the generated text to be guided in a particular direction. We provide a systematic evaluation of the technique and apply it to five datasets from the GEM benchmark for natural language generation (NLG). We present state-of-the-art results on several data-to-text datasets, including WebNLG.
Guiding Visual Question Generation
Oct 15, 2021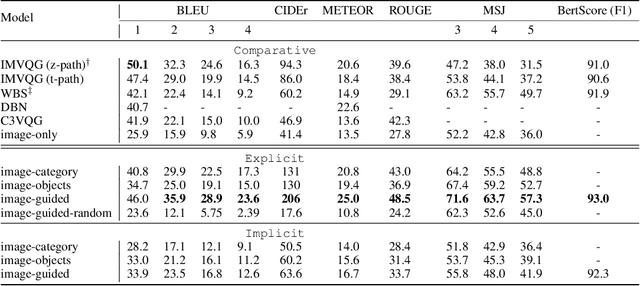
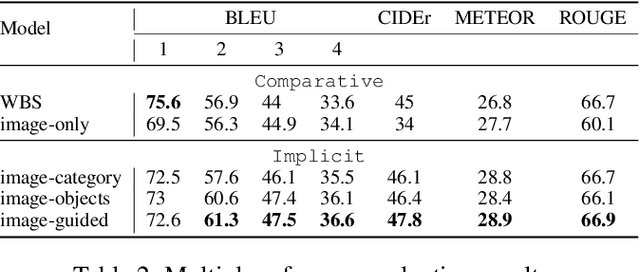


In traditional Visual Question Generation (VQG), most images have multiple concepts (e.g. objects and categories) for which a question could be generated, but models are trained to mimic an arbitrary choice of concept as given in their training data. This makes training difficult and also poses issues for evaluation -- multiple valid questions exist for most images but only one or a few are captured by the human references. We present Guiding Visual Question Generation - a variant of VQG which conditions the question generator on categorical information based on expectations on the type of question and the objects it should explore. We propose two variants: (i) an explicitly guided model that enables an actor (human or automated) to select which objects and categories to generate a question for; and (ii) an implicitly guided model that learns which objects and categories to condition on, based on discrete latent variables. The proposed models are evaluated on an answer-category augmented VQA dataset and our quantitative results show a substantial improvement over the current state of the art (over 9 BLEU-4 increase). Human evaluation validates that guidance helps the generation of questions that are grammatically coherent and relevant to the given image and objects.
Contextual Sentence Classification: Detecting Sustainability Initiatives in Company Reports
Oct 07, 2021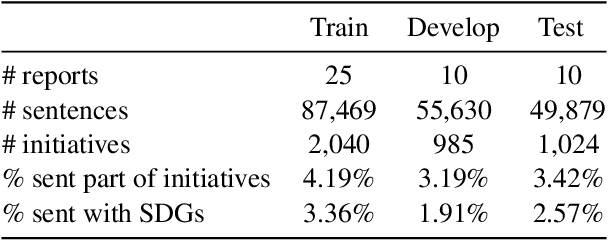
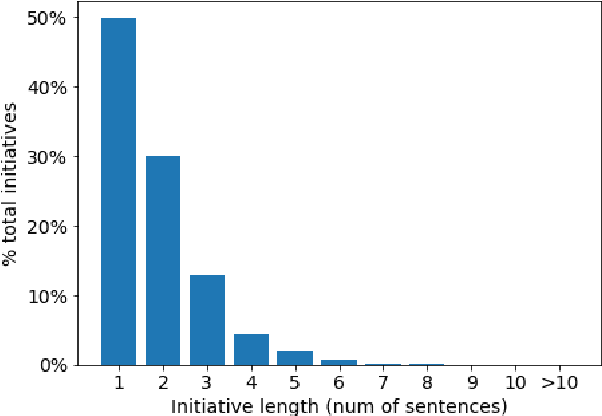
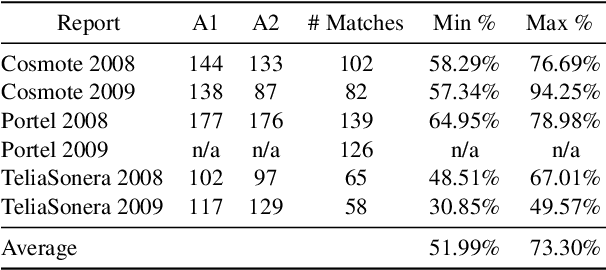
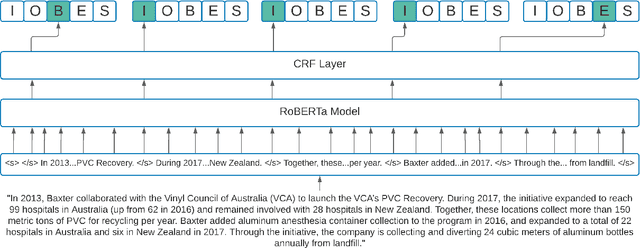
We introduce the novel task of detecting sustainability initiatives in company reports. Given a full report, the aim is to automatically identify mentions of practical activities that a company has performed in order to tackle specific societal issues. As a single initiative can often be described over multiples sentences, new methods for identifying continuous sentence spans needs to be developed. We release a new dataset of company reports in which the text has been manually annotated with sustainability initiatives. We also evaluate different models for initiative detection, introducing a novel aggregation and evaluation methodology. Our proposed architecture uses sequences of five consecutive sentences to account for contextual information when making classification decisions at the individual sentence level.
BERT memorisation and pitfalls in low-resource scenarios
Apr 16, 2021State-of-the-art pre-trained models have been shown to memorise facts and perform well with limited amounts of training data. To gain a better understanding of how these models learn, we study their generalisation and memorisation capabilities in noisy and low-resource scenarios. We find that the training of these models is almost unaffected by label noise and that it is possible to reach near-optimal performances even on extremely noisy datasets. Conversely, we also find that they completely fail when tested on low-resource tasks such as few-shot learning and rare entity recognition. To mitigate such limitations, we propose a novel architecture based on BERT and prototypical networks that improves performance in low-resource named entity recognition tasks.
Natural Language Inference with a Human Touch: Using Human Explanations to Guide Model Attention
Apr 16, 2021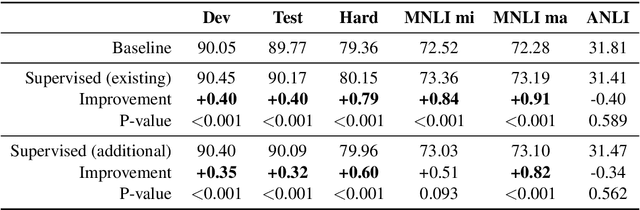
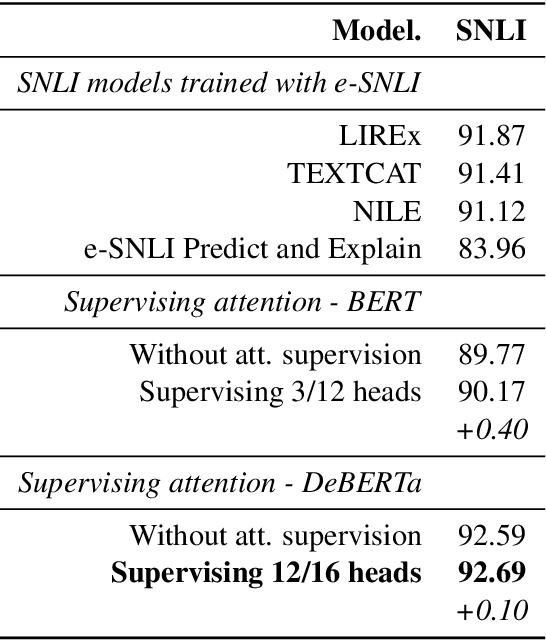
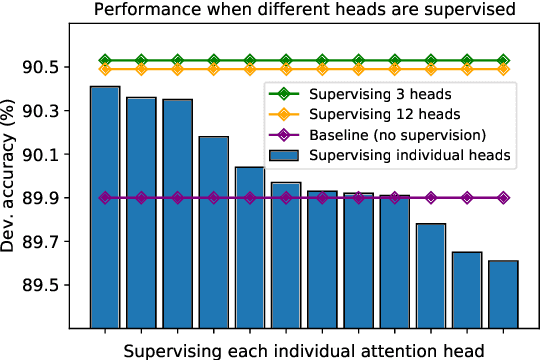
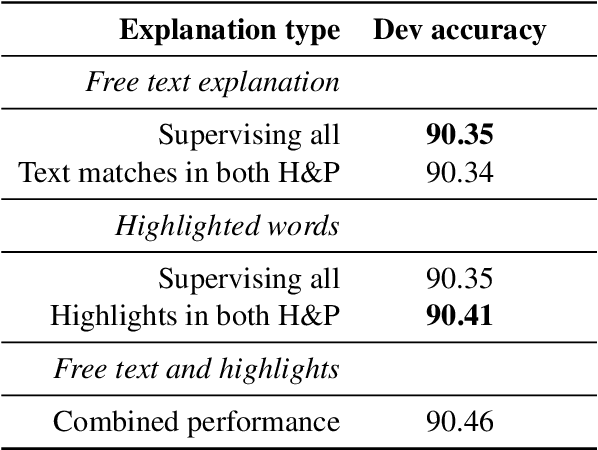
Natural Language Inference (NLI) models are known to learn from biases and artefacts within their training data, impacting how well the models generalise to other unseen datasets. While previous de-biasing approaches focus on preventing models learning from these biases, we instead provide models with information about how a human would approach the task, with the aim of encouraging the model to learn features that will generalise better to out-of-domain datasets. Using natural language explanations, we supervise a model's attention weights to encourage more attention to be paid to the words present in these explanations. For the first time, we show that training with human generated explanations can simultaneously improve performance both in-distribution and out-of-distribution for NLI, whereas most related work on robustness involves a trade-off between the two. Training with the human explanations encourages models to attend more broadly across the sentences, paying more attention to words in the premise and less attention to stop-words and punctuation. The supervised models attend to words humans believe are important, creating more robust and better performing NLI models.
How Metaphors Impact Political Discourse: A Large-Scale Topic-Agnostic Study Using Neural Metaphor Detection
Apr 08, 2021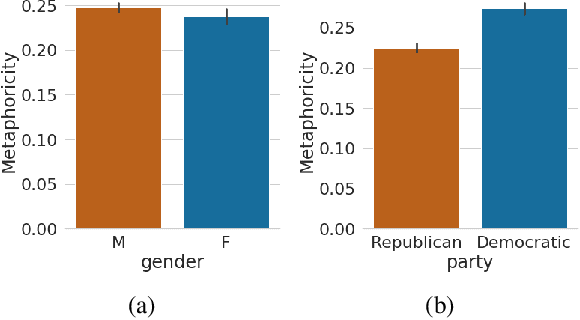
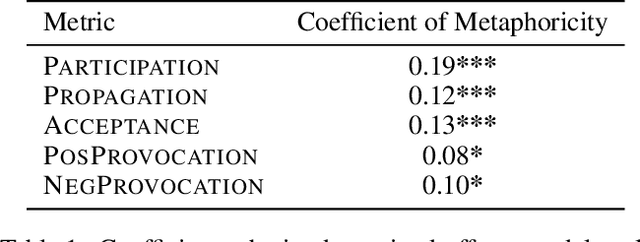
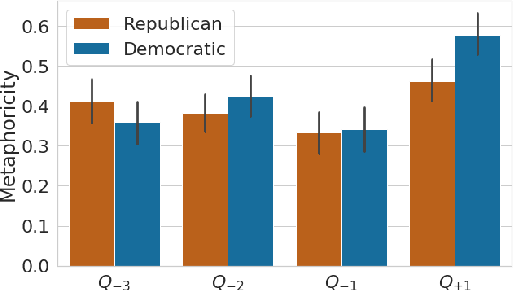
Metaphors are widely used in political rhetoric as an effective framing device. While the efficacy of specific metaphors such as the war metaphor in political discourse has been documented before, those studies often rely on small number of hand-coded instances of metaphor use. Larger-scale topic-agnostic studies are required to establish the general persuasiveness of metaphors as a device, and to shed light on the broader patterns that guide their persuasiveness. In this paper, we present a large-scale data-driven study of metaphors used in political discourse. We conduct this study on a publicly available dataset of over 85K posts made by 412 US politicians in their Facebook public pages, up until Feb 2017. Our contributions are threefold: we show evidence that metaphor use correlates with ideological leanings in complex ways that depend on concurrent political events such as winning or losing elections; we show that posts with metaphors elicit more engagement from their audience overall even after controlling for various socio-political factors such as gender and political party affiliation; and finally, we demonstrate that metaphoricity is indeed the reason for increased engagement of posts, through a fine-grained linguistic analysis of metaphorical vs. literal usages of 513 words across 70K posts.
* Published at ICWSM 2021. Please cite that version for academic publications
Turning transformer attention weights into zero-shot sequence labelers
Mar 26, 2021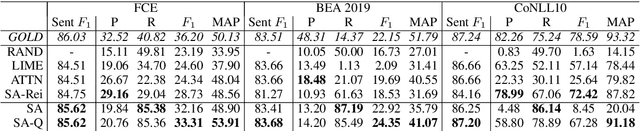
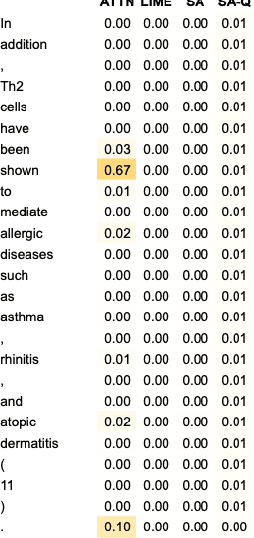
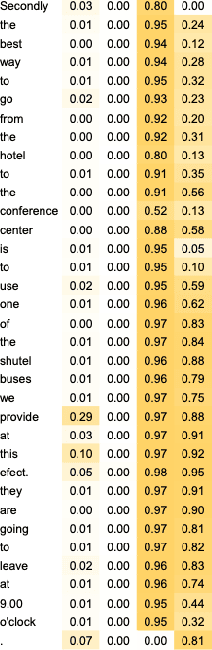
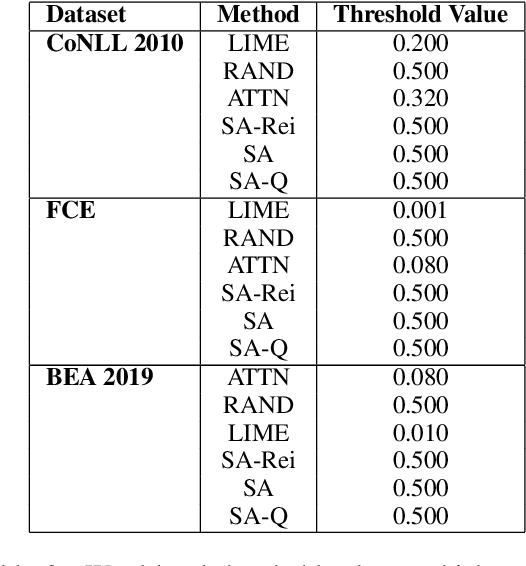
We demonstrate how transformer-based models can be redesigned in order to capture inductive biases across tasks on different granularities and perform inference in a zero-shot manner. Specifically, we show how sentence-level transformers can be modified into effective sequence labelers at the token level without any direct supervision. We compare against a range of diverse and previously proposed methods for generating token-level labels, and present a simple yet effective modified attention layer that significantly advances the current state of the art.