 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharing to learn and learning to share - Fitting together Meta-Learning, Multi-Task Learning, and Transfer Learning : A meta review
Nov 23, 2021

Integrating knowledge across different domains is an essential feature of human learning. Learning paradigms like transfer learning, meta learning, and multi-task learning reflect the human learning process by exploiting the prior knowledge for new tasks, encouraging faster learning and good generalization for new tasks. This article gives a detailed view of these learning paradigms along with a comparative analysis. The weakness of a learning algorithm turns out to be the strength of another, and thereby merging them is a prevalent trait in the literature. This work delivers a literature review of the articles, which fuses two algorithms to accomplish multiple tasks. A global generic learning network, an ensemble of meta learning, transfer learning, and multi-task learning, is also introduced here, along with some open research questions and directions for future research.
Småprat: DialoGPT for Natural Language Generation of Swedish Dialogue by Transfer Learning
Oct 12, 2021
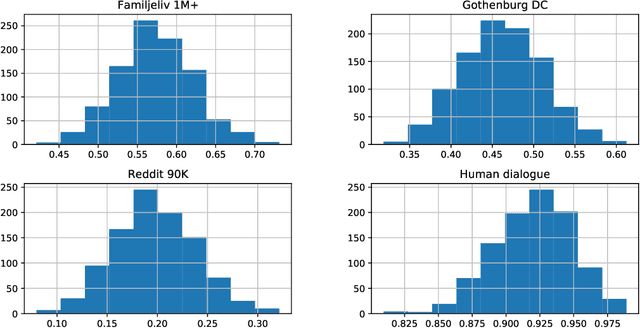
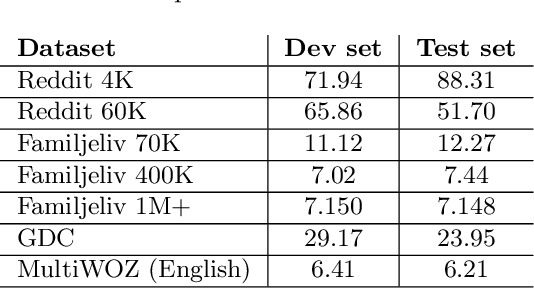
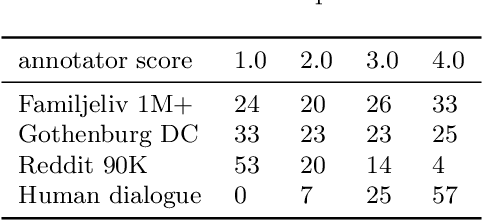
Building open-domain conversational systems (or chatbots) that produce convincing responses is a recognized challenge. Recent state-of-the-art (SoTA) transformer-based models for the generation of natural language dialogue have demonstrated impressive performance in simulating human-like, single-turn conversations in English. This work investigates, by an empirical study, the potential for transfer learning of such models to Swedish language. DialoGPT, an English language pre-trained model, is adapted by training on three different Swedish language conversational datasets obtained from publicly available sources. Perplexity score (an automated intrinsic language model metric) and surveys by human evaluation were used to assess the performances of the fine-tuned models, with results that indicate that the capacity for transfer learning can be exploited with considerable success. Human evaluators asked to score the simulated dialogue judged over 57% of the chatbot responses to be human-like for the model trained on the largest (Swedish) dataset. We provide the demos and model checkpoints of our English and Swedish chatbots on the HuggingFace platform for public use.
Current Status and Performance Analysis of Table Recognition in Document Images with Deep Neural Networks
May 08, 2021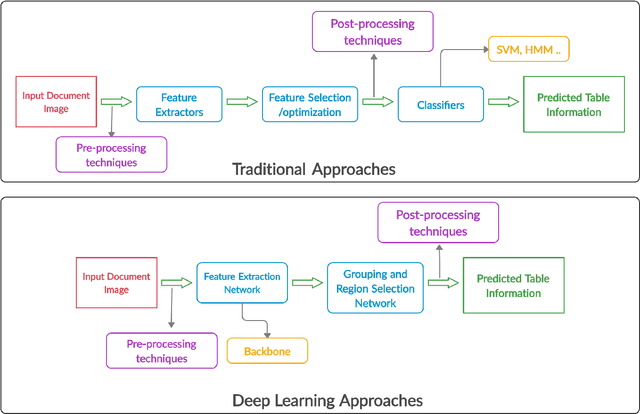
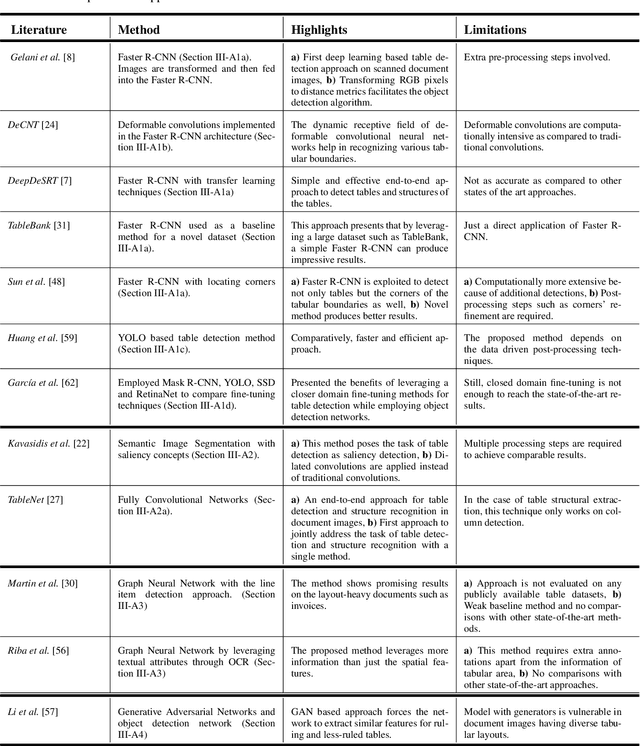
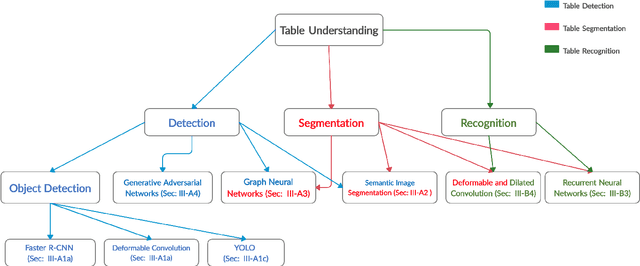
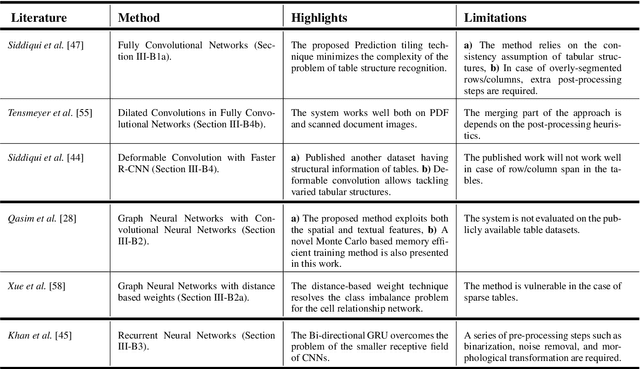
The first phase of table recognition is to detect the tabular area in a document. Subsequently, the tabular structures are recognized in the second phase in order to extract information from the respective cells. Table detection and structural recognition are pivotal problems in the domain of table understanding. However, table analysis is a perplexing task due to the colossal amount of diversity and asymmetry in tables. Therefore, it is an active area of research in document image analysis. Recent advances in the computing capabilities of graphical processing units have enabled deep neural networks to outperform traditional state-of-the-art machine learning methods. Table understanding has substantially benefited from the recent breakthroughs in deep neural networks. However, there has not been a consolidated description of the deep learning methods for table detection and table structure recognition. This review paper provides a thorough analysis of the modern methodologies that utilize deep neural networks. This work provided a thorough understanding of the current state-of-the-art and related challenges of table understanding in document images. Furthermore, the leading datasets and their intricacies have been elaborated along with the quantitative results. Moreover, a brief overview is given regarding the promising directions that can serve as a guide to further improve table analysis in document images.
Potential Idiomatic Expression (PIE)-English: Corpus for Classes of Idioms
Apr 25, 2021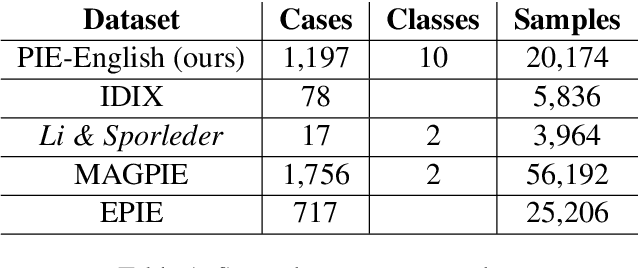
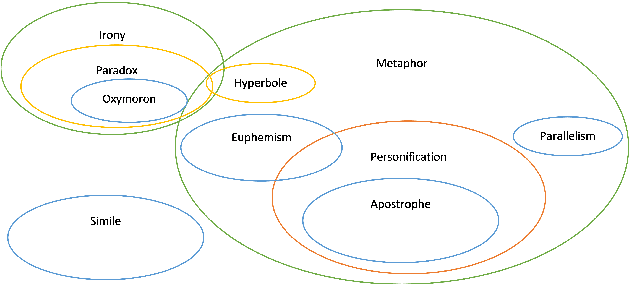
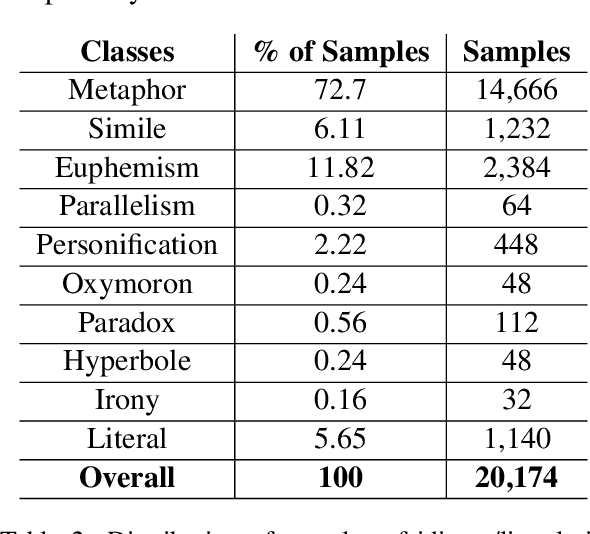
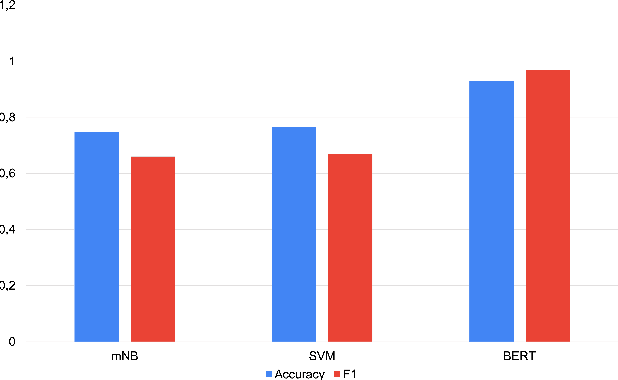
We present a fairly large, Potential Idiomatic Expression (PIE) dataset for Natural Language Processing (NLP) in English. The challenges with NLP systems with regards to tasks such as Machine Translation (MT), word sense disambiguation (WSD) and information retrieval make it imperative to have a labelled idioms dataset with classes such as it is in this work. To the best of the authors' knowledge, this is the first idioms corpus with classes of idioms beyond the literal and the general idioms classification. In particular, the following classes are labelled in the dataset: metaphor, simile, euphemism, parallelism, personification, oxymoron, paradox, hyperbole, irony and literal. Many past efforts have been limited in the corpus size and classes of samples but this dataset contains over 20,100 samples with almost 1,200 cases of idioms (with their meanings) from 10 classes (or senses). The corpus may also be extended by researchers to meet specific needs. The corpus has part of speech (PoS) tagging from the NLTK library. Classification experiments performed on the corpus to obtain a baseline and comparison among three common models, including the BERT model, give good results. We also make publicly available the corpus and the relevant codes for working with it for NLP tasks.
Guided Table Structure Recognition through Anchor Optimization
Apr 21, 2021

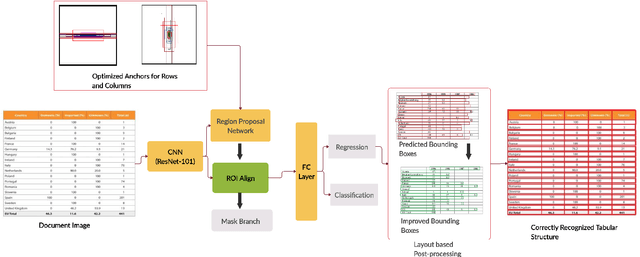
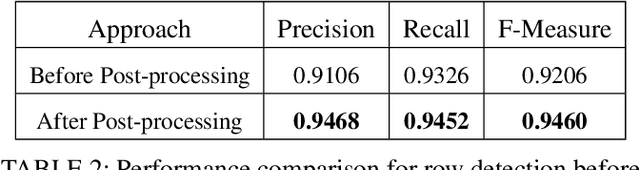
This paper presents the novel approach towards table structure recognition by leveraging the guided anchors. The concept differs from current state-of-the-art approaches for table structure recognition that naively apply object detection methods. In contrast to prior techniques, first, we estimate the viable anchors for table structure recognition. Subsequently, these anchors are exploited to locate the rows and columns in tabular images. Furthermore, the paper introduces a simple and effective method that improves the results by using tabular layouts in realistic scenarios. The proposed method is exhaustively evaluated on the two publicly available datasets of table structure recognition i.e ICDAR-2013 and TabStructDB. We accomplished state-of-the-art results on the ICDAR-2013 dataset with an average F-Measure of 95.05$\%$ (94.6$\%$ for rows and 96.32$\%$ for columns) and surpassed the baseline results on the TabStructDB dataset with an average F-Measure of 94.17$\%$ (94.08$\%$ for rows and 95.06$\%$ for columns).
The Challenge of Diacritics in Yoruba Embeddings
Nov 15, 2020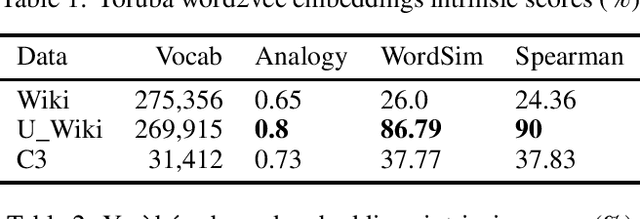
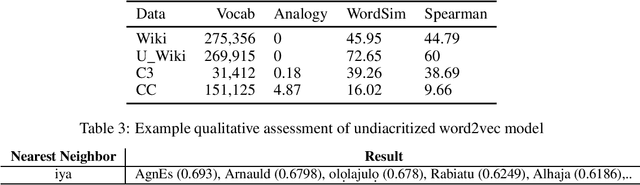
The major contributions of this work include the empirical establishment of a better performance for Yoruba embeddings from undiacritized (normalized) dataset and provision of new analogy sets for evaluation. The Yoruba language, being a tonal language, utilizes diacritics (tonal marks) in written form. We show that this affects embedding performance by creating embeddings from exactly the same Wikipedia dataset but with the second one normalized to be undiacritized. We further compare average intrinsic performance with two other work (using analogy test set & WordSim) and we obtain the best performance in WordSim and corresponding Spearman correlation.
Corpora Compared: The Case of the Swedish Gigaword & Wikipedia Corpora
Nov 06, 2020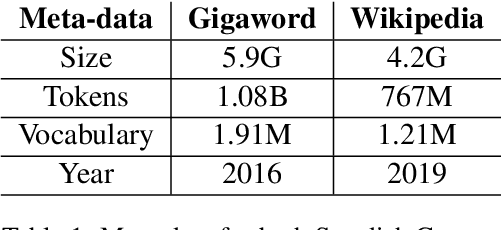
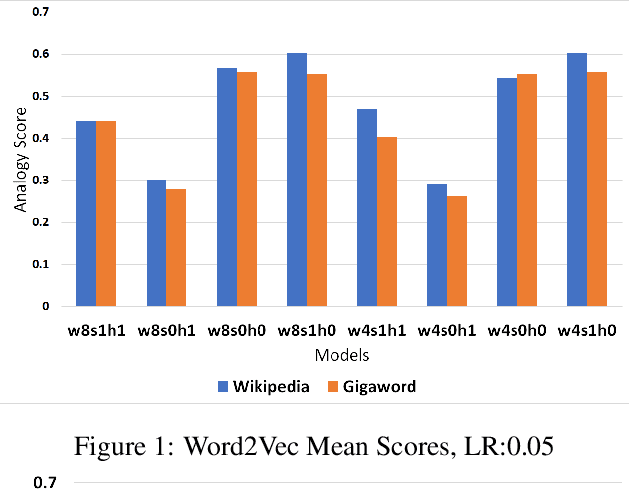
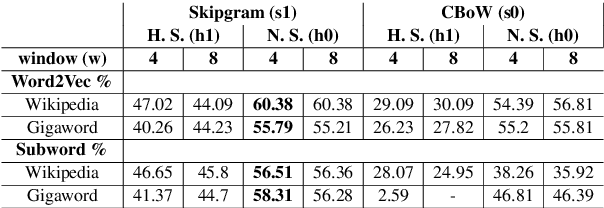
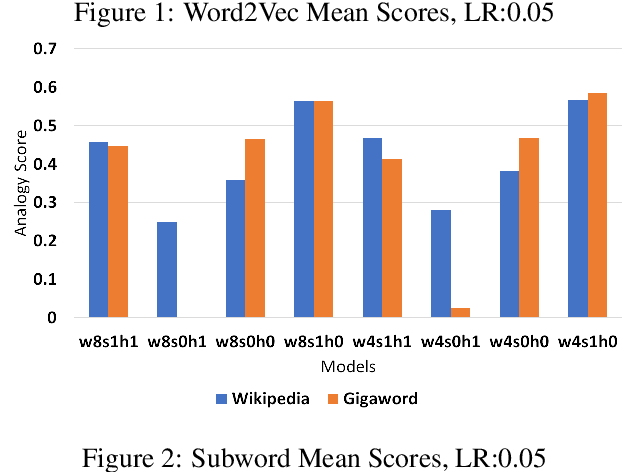
In this work, we show that the difference in performance of embeddings from differently sourced data for a given language can be due to other factors besides data size. Natural language processing (NLP) tasks usually perform better with embeddings from bigger corpora. However, broadness of covered domain and noise can play important roles. We evaluate embeddings based on two Swedish corpora: The Gigaword and Wikipedia, in analogy (intrinsic) tests and discover that the embeddings from the Wikipedia corpus generally outperform those from the Gigaword corpus, which is a bigger corpus. Downstream tests will be required to have a definite evaluation.
Exploring Swedish & English fastText Embeddings with the Transformer
Jul 23, 2020
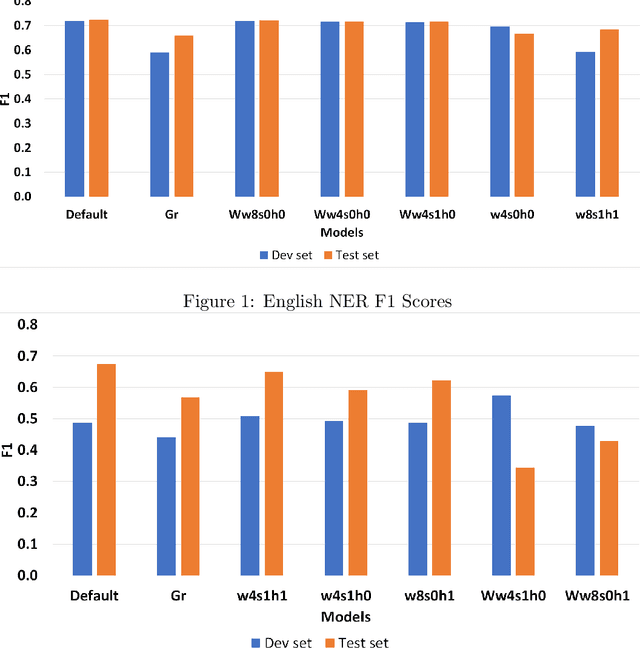

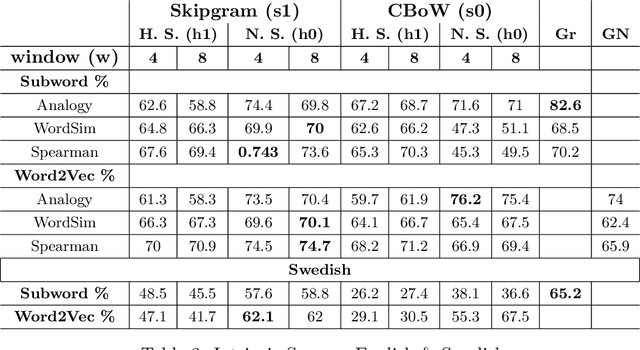
In this paper, our main contributions are that embeddings from relatively smaller corpora can outperform ones from far larger corpora and we present the new Swedish analogy test set. To achieve a good network performance in natural language processing (NLP) downstream tasks, several factors play important roles: dataset size, the right hyper-parameters, and well-trained embedding. We show that, with the right set of hyper-parameters, good network performance can be reached even on smaller datasets. We evaluate the embeddings at the intrinsic level and extrinsic level, by deploying them on the Transformer in named entity recognition (NER) task and conduct significance tests.This is done for both Swedish and English. We obtain better performance in both languages on the downstream task with far smaller training data, compared to recently released, common crawl versions and character n-grams appear useful for Swedish, a morphologically rich language.
Word2Vec: Optimal Hyper-Parameters and Their Impact on NLP Downstream Tasks
Mar 23, 2020

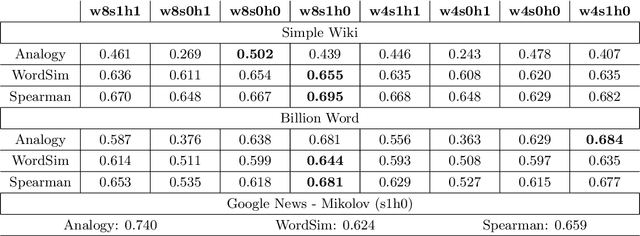
Word2Vec is a prominent tool for Natural Language Processing (NLP) tasks. Similar inspiration is found in distributed embeddings for state-of-the-art (sota) deep neural networks. However, wrong combination of hyper-parameters can produce poor quality vectors. The objective of this work is to show optimal combination of hyper-parameters exists and evaluate various combinations. We compare them with the original model released by Mikolov. Both intrinsic and extrinsic (downstream) evaluations, including Named Entity Recognition (NER) and Sentiment Analysis (SA) were carried out. The downstream tasks reveal that the best model is task-specific, high analogy scores don't necessarily correlate positively with F1 scores and the same applies for more data. Increasing vector dimension size after a point leads to poor quality or performance. If ethical considerations to save time, energy and the environment are made, then reasonably smaller corpora may do just as well or even better in some cases. Besides, using a small corpus, we obtain better human-assigned WordSim scores, corresponding Spearman correlation and better downstream (NER & SA) performance compared to Mikolov's model, trained on 100 billion word corpus.
Pretraining Image Encoders without Reconstruction via Feature Prediction Loss
Mar 16, 2020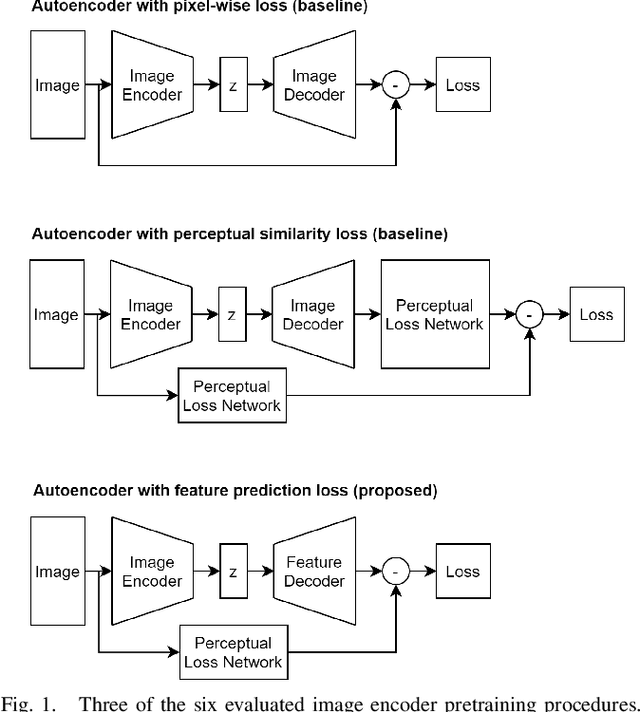
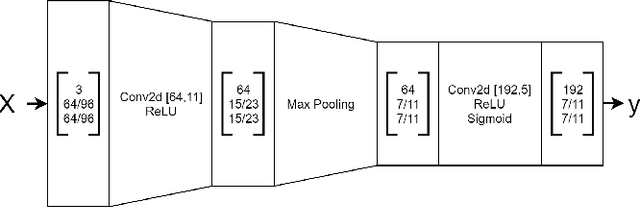

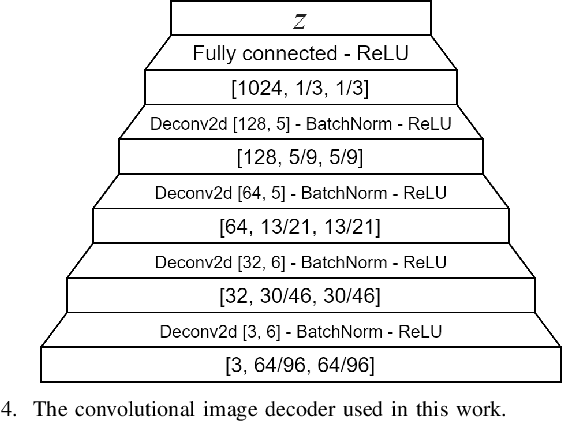
This work investigates three different loss functions for autoencoder-based pretraining of image encoders: The commonly used reconstruction loss, the more recently introduced perceptual similarity loss, and a feature prediction loss proposed here; the latter turning out to be the most efficient choice. Former work shows that predictions based on embeddings generated by image autoencoders can be improved by training with perceptual loss. So far the autoencoders trained with perceptual loss networks implemented an explicit comparison of the original and reconstructed images using the loss network. However, given such a loss network we show that there is no need for the timeconsuming task of decoding the entire image. Instead, we propose to decode the features of the loss network, hence the name "feature prediction loss". To evaluate this method we compare six different procedures for training image encoders based on pixel-wise, perceptual similarity, and feature prediction loss. The embedding-based prediction results show that encoders trained with feature prediction loss is as good or better than those trained with the other two losses. Additionally, the encoder is significantly faster to train using feature prediction loss in comparison to the other losses. The method implementation used in this work is available online: https://github.com/guspih/Perceptual-Autoencoders