 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogarithmic Pruning is All You Need
Jun 22, 2020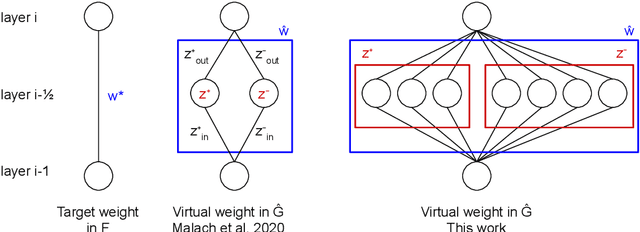
The Lottery Ticket Hypothesis is a conjecture that every large neural network contains a subnetwork that, when trained in isolation, achieves comparable performance to the large network. An even stronger conjecture has been proven recently: Every sufficiently overparameterized network contains a subnetwork that, even without training, achieves comparable accuracy to the trained large network. This theorem, however, relies on a number of strong assumptions and guarantees a polynomial factor on the size of the large network compared to the target function. In this work, we remove the most limiting assumptions of this previous work while providing significantly tighter bounds: the overparameterized network only needs a logarithmic factor (in all variables but depth) number of neurons per weight of the target subnetwork.
Pessimism About Unknown Unknowns Inspires Conservatism
Jun 15, 2020If we could define the set of all bad outcomes, we could hard-code an agent which avoids them; however, in sufficiently complex environments, this is infeasible. We do not know of any general-purpose approaches in the literature to avoiding novel failure modes. Motivated by this, we define an idealized Bayesian reinforcement learner which follows a policy that maximizes the worst-case expected reward over a set of world-models. We call this agent pessimistic, since it optimizes assuming the worst case. A scalar parameter tunes the agent's pessimism by changing the size of the set of world-models taken into account. Our first main contribution is: given an assumption about the agent's model class, a sufficiently pessimistic agent does not cause "unprecedented events" with probability $1-\delta$, whether or not designers know how to precisely specify those precedents they are concerned with. Since pessimism discourages exploration, at each timestep, the agent may defer to a mentor, who may be a human or some known-safe policy we would like to improve. Our other main contribution is that the agent's policy's value approaches at least that of the mentor, while the probability of deferring to the mentor goes to 0. In high-stakes environments, we might like advanced artificial agents to pursue goals cautiously, which is a non-trivial problem even if the agent were allowed arbitrary computing power; we present a formal solution.
Curiosity Killed the Cat and the Asymptotically Optimal Agent
Jun 05, 2020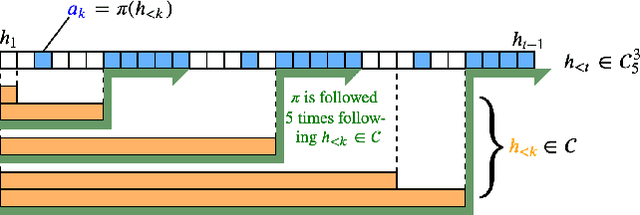
Reinforcement learners are agents that learn to pick actions that lead to high reward. Ideally, the value of a reinforcement learner's policy approaches optimality--where the optimal informed policy is the one which maximizes reward. Unfortunately, we show that if an agent is guaranteed to be "asymptotically optimal" in any (stochastically computable) environment, then subject to an assumption about the true environment, this agent will be either destroyed or incapacitated with probability 1; both of these are forms of traps as understood in the Markov Decision Process literature. Environments with traps pose a well-known problem for agents, but we are unaware of other work which shows that traps are not only a risk, but a certainty, for agents of a certain caliber. Much work in reinforcement learning uses an ergodicity assumption to avoid this problem. Often, doing theoretical research under simplifying assumptions prepares us to provide practical solutions even in the absence of those assumptions, but the ergodicity assumption in reinforcement learning may have led us entirely astray in preparing safe and effective exploration strategies for agents in dangerous environments. Rather than assuming away the problem, we present an agent with the modest guarantee of approaching the performance of a mentor, doing safe exploration instead of reckless exploration.
Online Learning in Contextual Bandits using Gated Linear Networks
Feb 21, 2020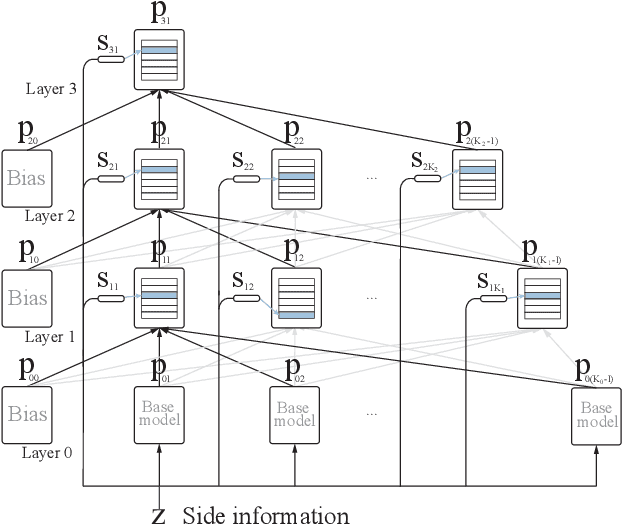
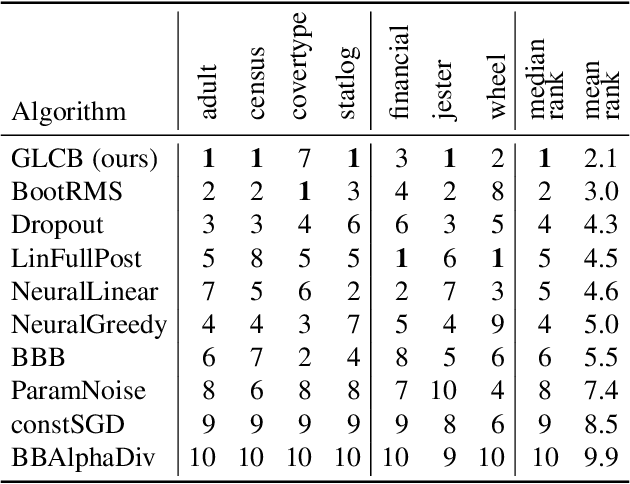
We introduce a new and completely online contextual bandit algorithm called Gated Linear Contextual Bandits (GLCB). This algorithm is based on Gated Linear Networks (GLNs), a recently introduced deep learning architecture with properties well-suited to the online setting. Leveraging data-dependent gating properties of the GLN we are able to estimate prediction uncertainty with effectively zero algorithmic overhead. We empirically evaluate GLCB compared to 9 state-of-the-art algorithms that leverage deep neural networks, on a standard benchmark suite of discrete and continuous contextual bandit problems. GLCB obtains median first-place despite being the only online method, and we further support these results with a theoretical study of its convergence properties.
Gated Linear Networks
Sep 30, 2019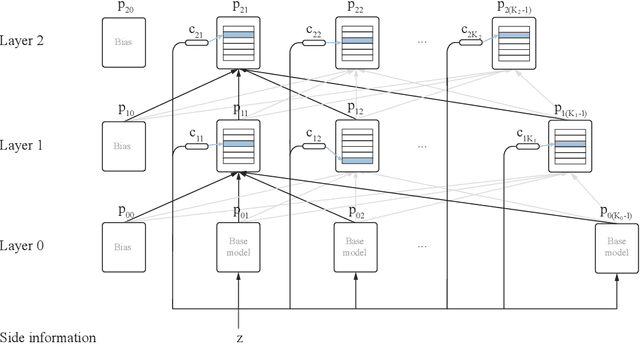
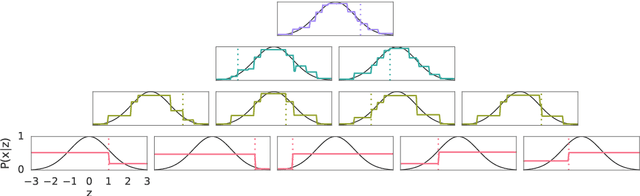
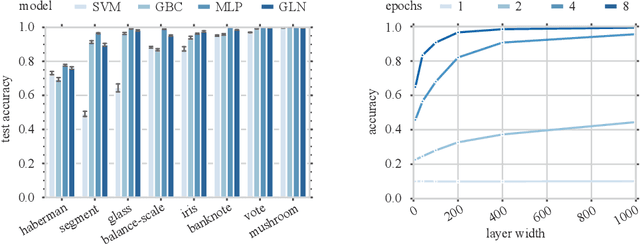
This paper presents a family of backpropagation-free neural architectures, Gated Linear Networks (GLNs),that are well suited to online learning applications where sample efficiency is of paramount importance. The impressive empirical performance of these architectures has long been known within the data compression community, but a theoretically satisfying explanation as to how and why they perform so well has proven difficult. What distinguishes these architectures from other neural systems is the distributed and local nature of their credit assignment mechanism; each neuron directly predicts the target and has its own set of hard-gated weights that are locally adapted via online convex optimization. By providing an interpretation, generalization and subsequent theoretical analysis, we show that sufficiently large GLNs are universal in a strong sense: not only can they model any compactly supported, continuous density function to arbitrary accuracy, but that any choice of no-regret online convex optimization technique will provably converge to the correct solution with enough data. Empirically we show a collection of single-pass learning results on established machine learning benchmarks that are competitive with results obtained with general purpose batch learning techniques.
Reward Tampering Problems and Solutions in Reinforcement Learning: A Causal Influence Diagram Perspective
Aug 20, 2019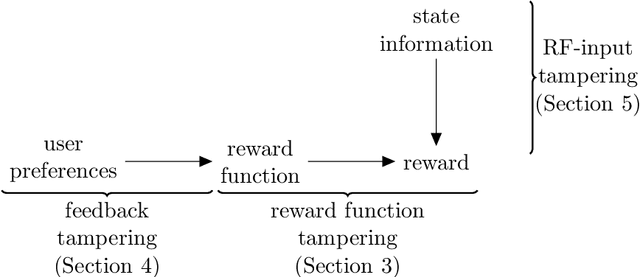
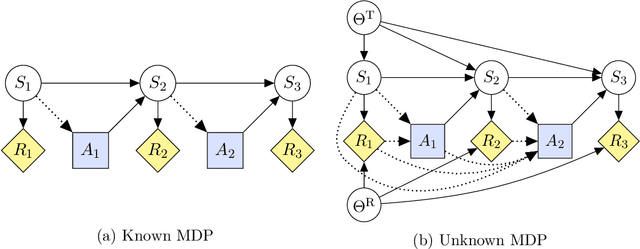
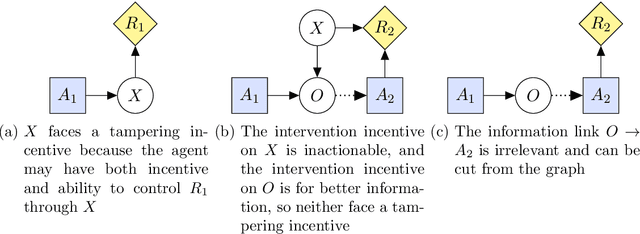
Can an arbitrarily intelligent reinforcement learning agent be kept under control by a human user? Or do agents with sufficient intelligence inevitably find ways to shortcut their reward signal? This question impacts how far reinforcement learning can be scaled, and whether alternative paradigms must be developed in order to build safe artificial general intelligence. In this paper, we use an intuitive yet precise graphical model called causal influence diagrams to formalize reward tampering problems. We also describe a number of modifications to the reinforcement learning objective that prevent incentives for reward tampering. We verify the solutions using recently developed graphical criteria for inferring agent incentives from causal influence diagrams. Along the way, we also compare corrigibility and self-preservation properties of the various solutions, and discuss how they can be combined into a single agent without reward tampering incentives.
Fairness without Regret
Jul 11, 2019
A popular approach of achieving fairness in optimization problems is by constraining the solution space to "fair" solutions, which unfortunately typically reduces solution quality. In practice, the ultimate goal is often an aggregate of sub-goals without a unique or best way of combining them or which is otherwise only partially known. I turn this problem into a feature and suggest to use a parametrized objective and vary the parameters within reasonable ranges to get a "set" of optimal solutions, which can then be optimized using secondary criteria such as fairness without compromising the primary objective, i.e. without regret (societal cost).
Asymptotically Unambitious Artificial General Intelligence
May 29, 2019
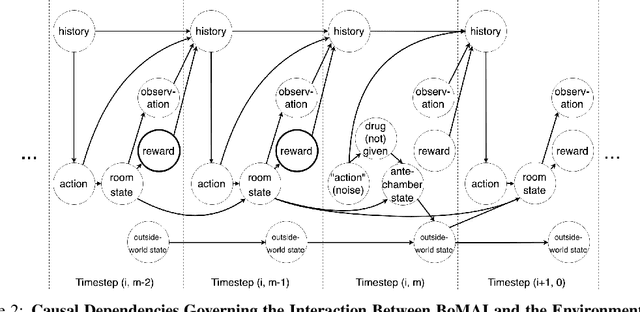
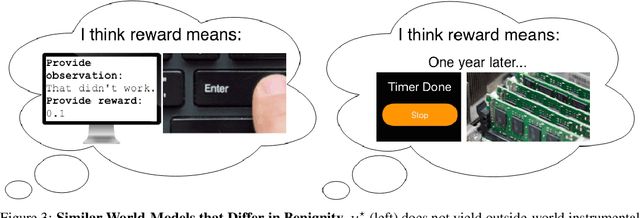
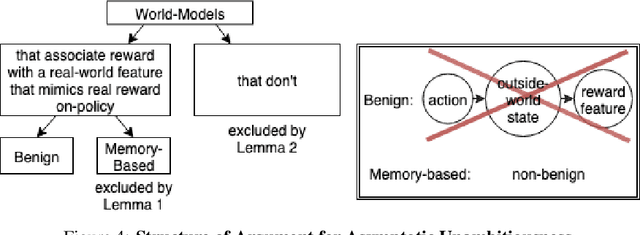
General intelligence, the ability to solve arbitrary solvable problems, is supposed by many to be artificially constructible. Narrow intelligence, the ability to solve a given particularly difficult problem, has seen impressive recent development. Notable examples include self-driving cars, Go engines, image classifiers, and translators. Artificial General Intelligence (AGI) presents dangers that narrow intelligence does not: if something smarter than us across every domain were indifferent to our concerns, it would be an existential threat to humanity, just as we threaten many species despite no ill will. Even the theory of how to maintain the alignment of an AGI's goals with our own has proven highly elusive. We present the first algorithm we are aware of for asymptotically unambitious AGI, where "unambitiousness" includes not seeking arbitrary power. Thus, we identify an exception to the Instrumental Convergence Thesis, which is roughly that by default, an AGI would seek power, including over us.
Conditions on Features for Temporal Difference-Like Methods to Converge
May 28, 2019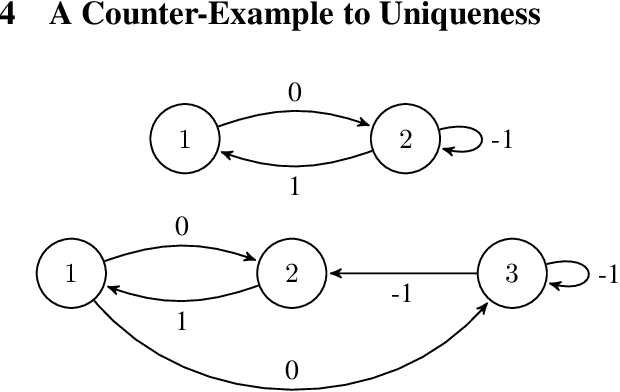
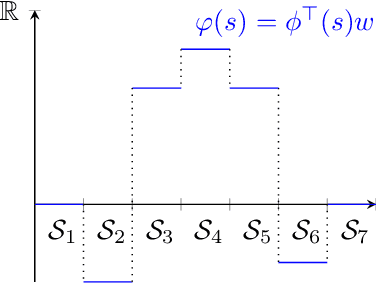
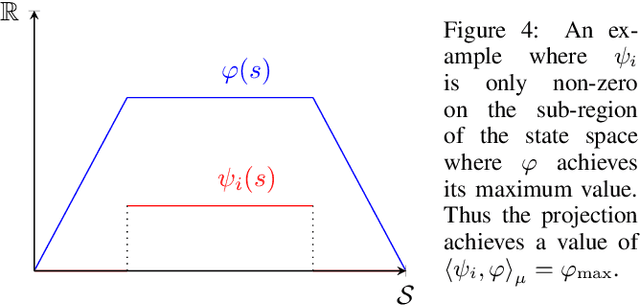
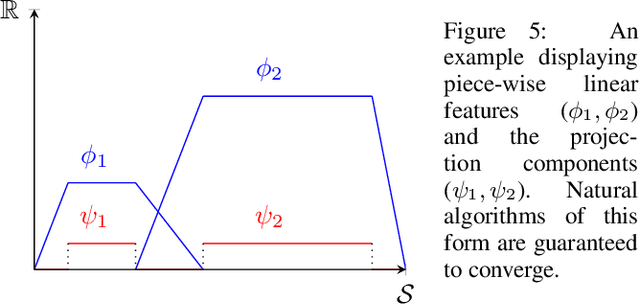
The convergence of many reinforcement learning (RL) algorithms with linear function approximation has been investigated extensively but most proofs assume that these methods converge to a unique solution. In this paper, we provide a complete characterization of non-uniqueness issues for a large class of reinforcement learning algorithms, simultaneously unifying many counter-examples to convergence in a theoretical framework. We achieve this by proving a new condition on features that can determine whether the convergence assumptions are valid or non-uniqueness holds. We consider a general class of RL methods, which we call natural algorithms, whose solutions are characterized as the fixed point of a projected Bellman equation (when it exists); notably, bootstrapped temporal difference-based methods such as $TD(\lambda)$ and $GTD(\lambda)$ are natural algorithms. Our main result proves that natural algorithms converge to the correct solution if and only if all the value functions in the approximation space satisfy a certain shape. This implies that natural algorithms are, in general, inherently prone to converge to the wrong solution for most feature choices even if the value function can be represented exactly. Given our results, we show that state aggregation based features are a safe choice for natural algorithms and we also provide a condition for finding convergent algorithms under other feature constructions.
Strong Asymptotic Optimality in General Environments
Mar 04, 2019
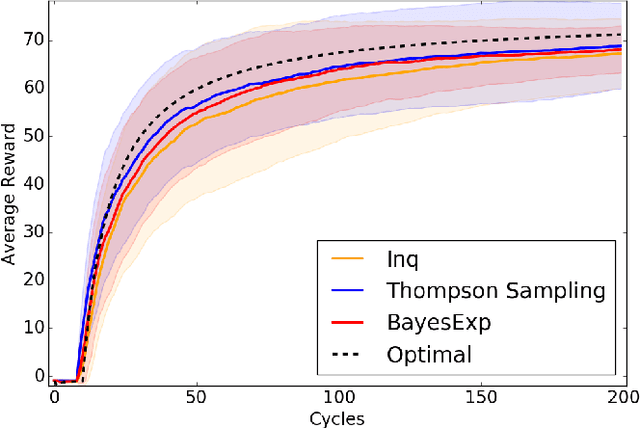
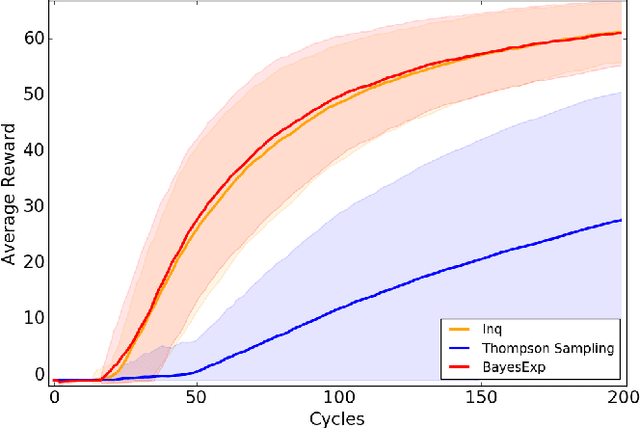
Reinforcement Learning agents are expected to eventually perform well. Typically, this takes the form of a guarantee about the asymptotic behavior of an algorithm given some assumptions about the environment. We present an algorithm for a policy whose value approaches the optimal value with probability 1 in all computable probabilistic environments, provided the agent has a bounded horizon. This is known as strong asymptotic optimality, and it was previously unknown whether it was possible for a policy to be strongly asymptotically optimal in the class of all computable probabilistic environments. Our agent, Inquisitive Reinforcement Learner (Inq), is more likely to explore the more it expects an exploratory action to reduce its uncertainty about which environment it is in, hence the term inquisitive. Exploring inquisitively is a strategy that can be applied generally; for more manageable environment classes, inquisitiveness is tractable. We conducted experiments in "grid-worlds" to compare the Inquisitive Reinforcement Learner to other weakly asymptotically optimal agents.