 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Selection with the Loss Rank Principle
Mar 02, 2010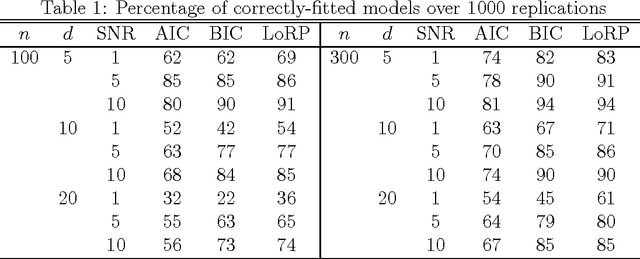
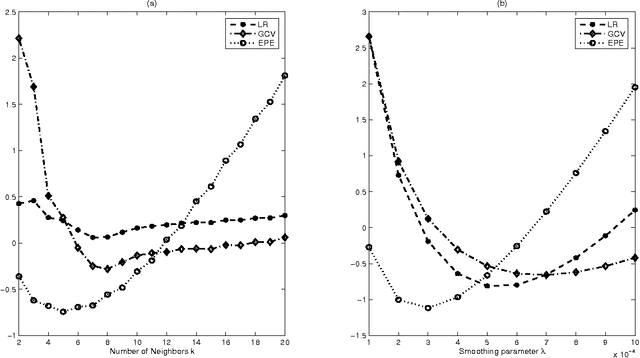
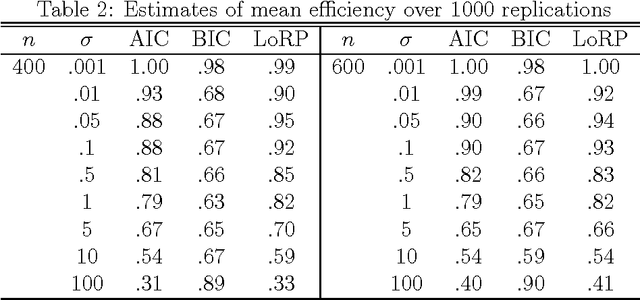
A key issue in statistics and machine learning is to automatically select the "right" model complexity, e.g., the number of neighbors to be averaged over in k nearest neighbor (kNN) regression or the polynomial degree in regression with polynomials. We suggest a novel principle - the Loss Rank Principle (LoRP) - for model selection in regression and classification. It is based on the loss rank, which counts how many other (fictitious) data would be fitted better. LoRP selects the model that has minimal loss rank. Unlike most penalized maximum likelihood variants (AIC, BIC, MDL), LoRP depends only on the regression functions and the loss function. It works without a stochastic noise model, and is directly applicable to any non-parametric regressor, like kNN.
* 31 LaTeX pages, 1 figure
Matching 2-D Ellipses to 3-D Circles with Application to Vehicle Pose Estimation
Dec 18, 2009
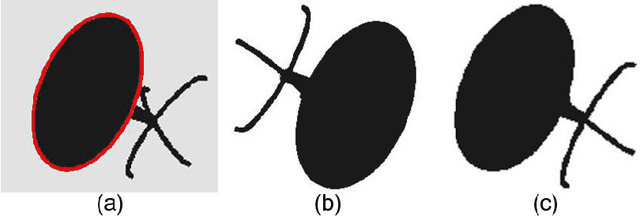

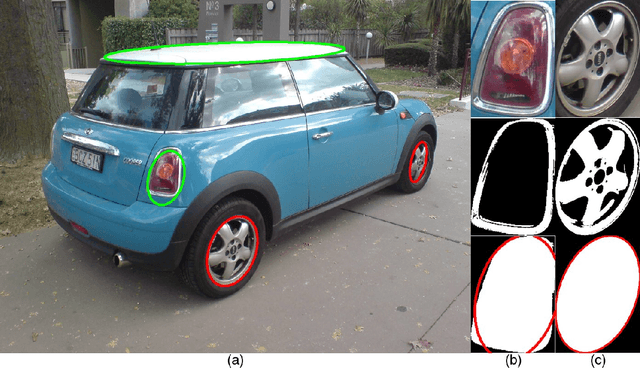
Finding the three-dimensional representation of all or a part of a scene from a single two dimensional image is a challenging task. In this paper we propose a method for identifying the pose and location of objects with circular protrusions in three dimensions from a single image and a 3d representation or model of the object of interest. To do this, we present a method for identifying ellipses and their properties quickly and reliably with a novel technique that exploits intensity differences between objects and a geometric technique for matching an ellipse in 2d to a circle in 3d. We apply these techniques to the specific problem of determining the pose and location of vehicles, particularly cars, from a single image. We have achieved excellent pose recovery performance on artificially generated car images and show promising results on real vehicle images. We also make use of the ellipse detection method to identify car wheels from images, with a very high successful match rate.
* 16 LaTeX pages, 5 figures
Discrete MDL Predicts in Total Variation
Sep 25, 2009The Minimum Description Length (MDL) principle selects the model that has the shortest code for data plus model. We show that for a countable class of models, MDL predictions are close to the true distribution in a strong sense. The result is completely general. No independence, ergodicity, stationarity, identifiability, or other assumption on the model class need to be made. More formally, we show that for any countable class of models, the distributions selected by MDL (or MAP) asymptotically predict (merge with) the true measure in the class in total variation distance. Implications for non-i.i.d. domains like time-series forecasting, discriminative learning, and reinforcement learning are discussed.
* 15 LaTeX pages
Open Problems in Universal Induction & Intelligence
Jul 04, 2009Specialized intelligent systems can be found everywhere: finger print, handwriting, speech, and face recognition, spam filtering, chess and other game programs, robots, et al. This decade the first presumably complete mathematical theory of artificial intelligence based on universal induction-prediction-decision-action has been proposed. This information-theoretic approach solidifies the foundations of inductive inference and artificial intelligence. Getting the foundations right usually marks a significant progress and maturing of a field. The theory provides a gold standard and guidance for researchers working on intelligent algorithms. The roots of universal induction have been laid exactly half-a-century ago and the roots of universal intelligence exactly one decade ago. So it is timely to take stock of what has been achieved and what remains to be done. Since there are already good recent surveys, I describe the state-of-the-art only in passing and refer the reader to the literature. This article concentrates on the open problems in universal induction and its extension to universal intelligence.
* 32 LaTeX pages
Feature Reinforcement Learning: Part I: Unstructured MDPs
Jun 09, 2009General-purpose, intelligent, learning agents cycle through sequences of observations, actions, and rewards that are complex, uncertain, unknown, and non-Markovian. On the other hand, reinforcement learning is well-developed for small finite state Markov decision processes (MDPs). Up to now, extracting the right state representations out of bare observations, that is, reducing the general agent setup to the MDP framework, is an art that involves significant effort by designers. The primary goal of this work is to automate the reduction process and thereby significantly expand the scope of many existing reinforcement learning algorithms and the agents that employ them. Before we can think of mechanizing this search for suitable MDPs, we need a formal objective criterion. The main contribution of this article is to develop such a criterion. I also integrate the various parts into one learning algorithm. Extensions to more realistic dynamic Bayesian networks are developed in Part II. The role of POMDPs is also considered there.
* 24 LaTeX pages, 5 diagrams
Limits of Learning about a Categorical Latent Variable under Prior Near-Ignorance
Apr 29, 2009In this paper, we consider the coherent theory of (epistemic) uncertainty of Walley, in which beliefs are represented through sets of probability distributions, and we focus on the problem of modeling prior ignorance about a categorical random variable. In this setting, it is a known result that a state of prior ignorance is not compatible with learning. To overcome this problem, another state of beliefs, called \emph{near-ignorance}, has been proposed. Near-ignorance resembles ignorance very closely, by satisfying some principles that can arguably be regarded as necessary in a state of ignorance, and allows learning to take place. What this paper does, is to provide new and substantial evidence that also near-ignorance cannot be really regarded as a way out of the problem of starting statistical inference in conditions of very weak beliefs. The key to this result is focusing on a setting characterized by a variable of interest that is \emph{latent}. We argue that such a setting is by far the most common case in practice, and we provide, for the case of categorical latent variables (and general \emph{manifest} variables) a condition that, if satisfied, prevents learning to take place under prior near-ignorance. This condition is shown to be easily satisfied even in the most common statistical problems. We regard these results as a strong form of evidence against the possibility to adopt a condition of prior near-ignorance in real statistical problems.
* 27 LaTeX pages
Exact Non-Parametric Bayesian Inference on Infinite Trees
Mar 30, 2009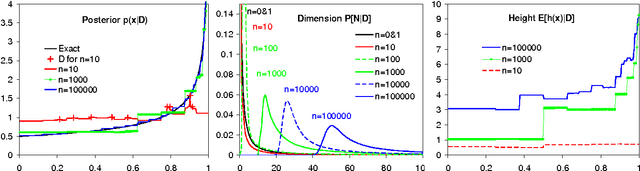
Given i.i.d. data from an unknown distribution, we consider the problem of predicting future items. An adaptive way to estimate the probability density is to recursively subdivide the domain to an appropriate data-dependent granularity. A Bayesian would assign a data-independent prior probability to "subdivide", which leads to a prior over infinite(ly many) trees. We derive an exact, fast, and simple inference algorithm for such a prior, for the data evidence, the predictive distribution, the effective model dimension, moments, and other quantities. We prove asymptotic convergence and consistency results, and illustrate the behavior of our model on some prototypical functions.
A New Local Distance-Based Outlier Detection Approach for Scattered Real-World Data
Mar 18, 2009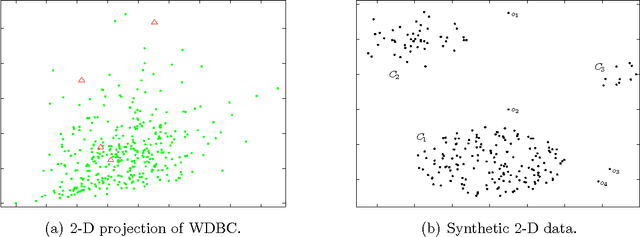
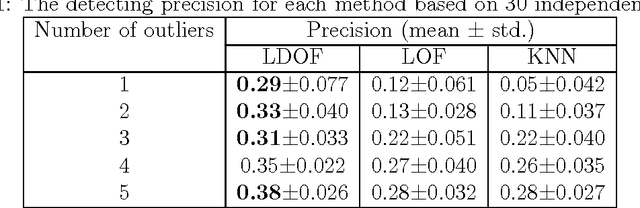
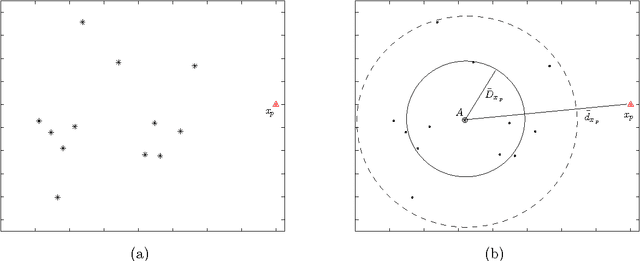
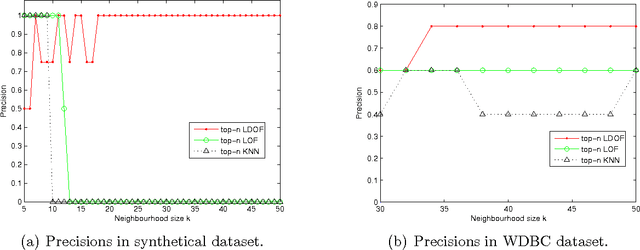
Detecting outliers which are grossly different from or inconsistent with the remaining dataset is a major challenge in real-world KDD applications. Existing outlier detection methods are ineffective on scattered real-world datasets due to implicit data patterns and parameter setting issues. We define a novel "Local Distance-based Outlier Factor" (LDOF) to measure the {outlier-ness} of objects in scattered datasets which addresses these issues. LDOF uses the relative location of an object to its neighbours to determine the degree to which the object deviates from its neighbourhood. Properties of LDOF are theoretically analysed including LDOF's lower bound and its false-detection probability, as well as parameter settings. In order to facilitate parameter settings in real-world applications, we employ a top-n technique in our outlier detection approach, where only the objects with the highest LDOF values are regarded as outliers. Compared to conventional approaches (such as top-n KNN and top-n LOF), our method top-n LDOF is more effective at detecting outliers in scattered data. It is also easier to set parameters, since its performance is relatively stable over a large range of parameter values, as illustrated by experimental results on both real-world and synthetic datasets.
* 15 LaTeX pages, 7 figures, 2 tables, 1 algorithm, 2 theorems
Practical Robust Estimators for the Imprecise Dirichlet Model
Jan 26, 2009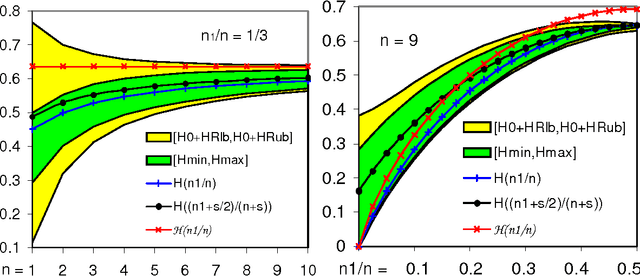
Walley's Imprecise Dirichlet Model (IDM) for categorical i.i.d. data extends the classical Dirichlet model to a set of priors. It overcomes several fundamental problems which other approaches to uncertainty suffer from. Yet, to be useful in practice, one needs efficient ways for computing the imprecise=robust sets or intervals. The main objective of this work is to derive exact, conservative, and approximate, robust and credible interval estimates under the IDM for a large class of statistical estimators, including the entropy and mutual information.
* 22 pages, 2 figures
Feature Dynamic Bayesian Networks
Dec 25, 2008Feature Markov Decision Processes (PhiMDPs) are well-suited for learning agents in general environments. Nevertheless, unstructured (Phi)MDPs are limited to relatively simple environments. Structured MDPs like Dynamic Bayesian Networks (DBNs) are used for large-scale real-world problems. In this article I extend PhiMDP to PhiDBN. The primary contribution is to derive a cost criterion that allows to automatically extract the most relevant features from the environment, leading to the "best" DBN representation. I discuss all building blocks required for a complete general learning algorithm.
* 7 pages