 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExSum: From Local Explanations to Model Understanding
Apr 30, 2022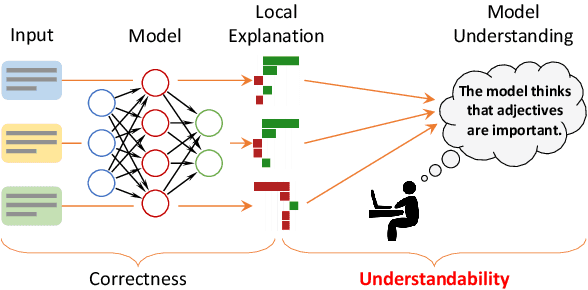
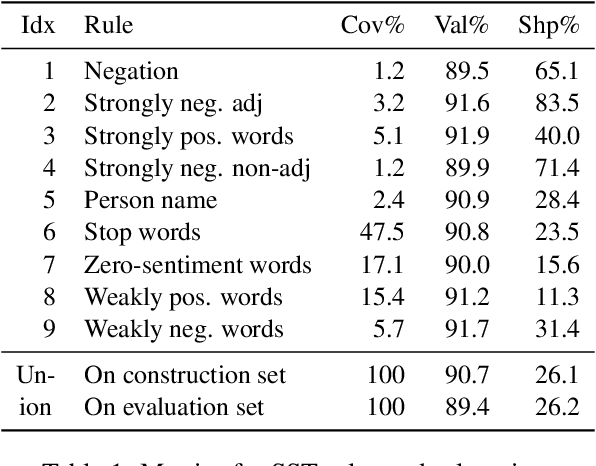
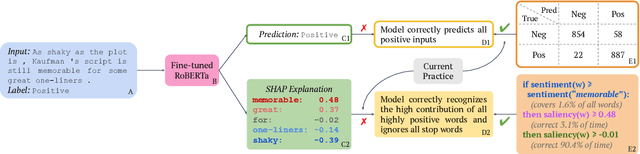
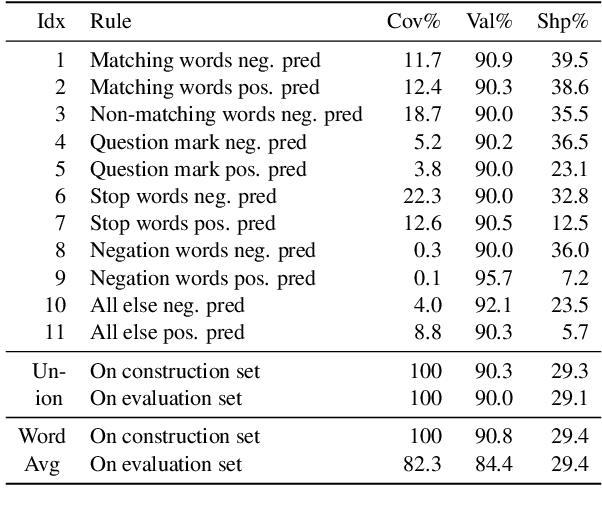
Interpretability methods are developed to understand the working mechanisms of black-box models, which is crucial to their responsible deployment. Fulfilling this goal requires both that the explanations generated by these methods are correct and that people can easily and reliably understand them. While the former has been addressed in prior work, the latter is often overlooked, resulting in informal model understanding derived from a handful of local explanations. In this paper, we introduce explanation summary (ExSum), a mathematical framework for quantifying model understanding, and propose metrics for its quality assessment. On two domains, ExSum highlights various limitations in the current practice, helps develop accurate model understanding, and reveals easily overlooked properties of the model. We also connect understandability to other properties of explanations such as human alignment, robustness, and counterfactual minimality and plausibility.
Finding and Fixing Spurious Patterns with Explanations
Jun 03, 2021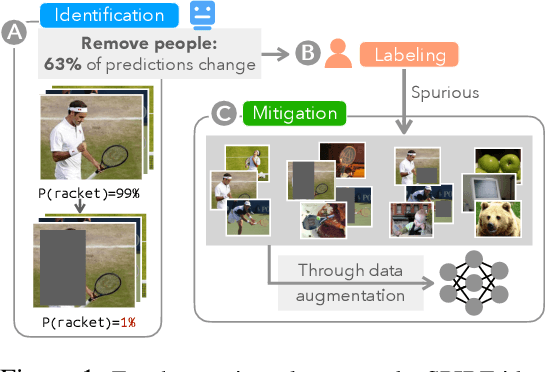

Machine learning models often use spurious patterns such as "relying on the presence of a person to detect a tennis racket," which do not generalize. In this work, we present an end-to-end pipeline for identifying and mitigating spurious patterns for image classifiers. We start by finding patterns such as "the model's prediction for tennis racket changes 63% of the time if we hide the people." Then, if a pattern is spurious, we mitigate it via a novel form of data augmentation. We demonstrate that this approach identifies a diverse set of spurious patterns and that it mitigates them by producing a model that is both more accurate on a distribution where the spurious pattern is not helpful and more robust to distribution shift.
Do Feature Attribution Methods Correctly Attribute Features?
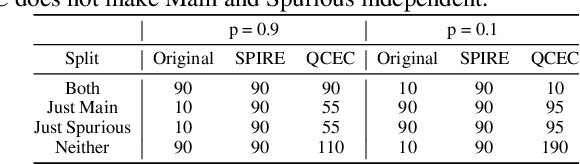
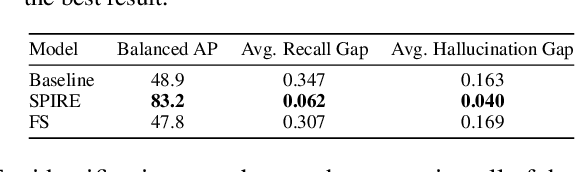
Apr 27, 2021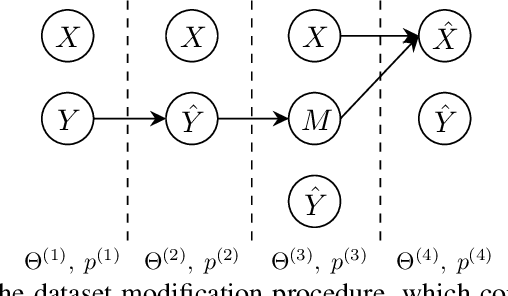

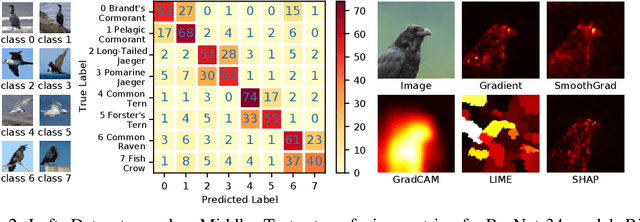
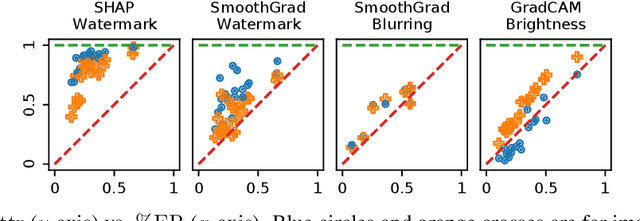
Feature attribution methods are exceedingly popular in interpretable machine learning. They aim to compute the attribution of each input feature to represent its importance, but there is no consensus on the definition of "attribution", leading to many competing methods with little systematic evaluation. The lack of attribution ground truth further complicates evaluation, which has to rely on proxy metrics. To address this, we propose a dataset modification procedure such that models trained on the new dataset have ground truth attribution available. We evaluate three methods: saliency maps, rationales, and attention. We identify their deficiencies and add a new perspective to the growing body of evidence questioning their correctness and reliability in the wild. Our evaluation approach is model-agnostic and can be used to assess future feature attribution method proposals as well. Code is available at https://github.com/YilunZhou/feature-attribution-evaluation.
Polyjuice: Automated, General-purpose Counterfactual Generation
Jan 01, 2021

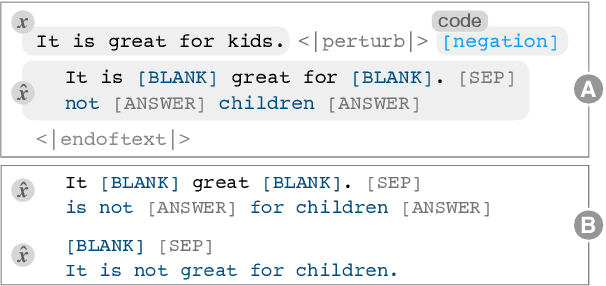
Counterfactual examples have been shown to be useful for many applications, including calibrating, evaluating, and explaining model decision boundaries. However, previous methods for generating such counterfactual examples have been tightly tailored to a specific application, used a limited range of linguistic patterns, or are hard to scale. We propose to disentangle counterfactual generation from its use cases, i.e., gather general-purpose counterfactuals first, and then select them for specific applications. We frame the automated counterfactual generation as text generation, and finetune GPT-2 into a generator, Polyjuice, which produces fluent and diverse counterfactuals. Our method also allows control over where perturbations happen and what they do. We show Polyjuice supports multiple use cases: by generating diverse counterfactuals for humans to label, Polyjuice helps produce high-quality datasets for model training and evaluation, requiring 40% less human effort. When used to generate explanations, Polyjuice helps augment feature attribution methods to reveal models' erroneous behaviors.
Does the Whole Exceed its Parts? The Effect of AI Explanations on Complementary Team Performance
Jun 30, 2020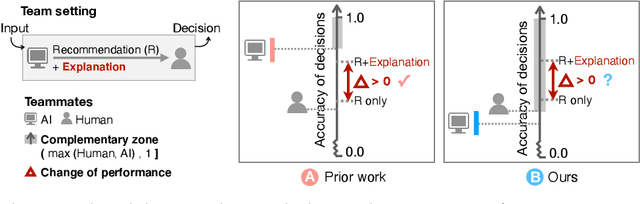
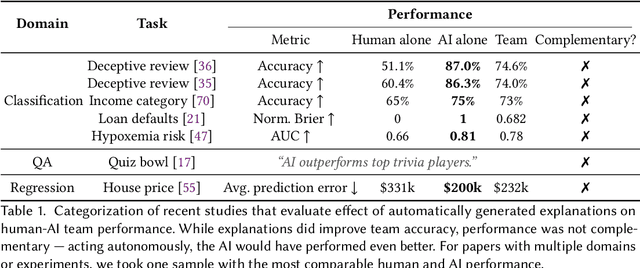
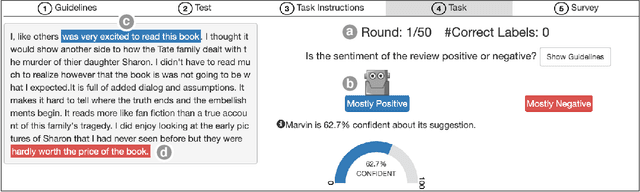
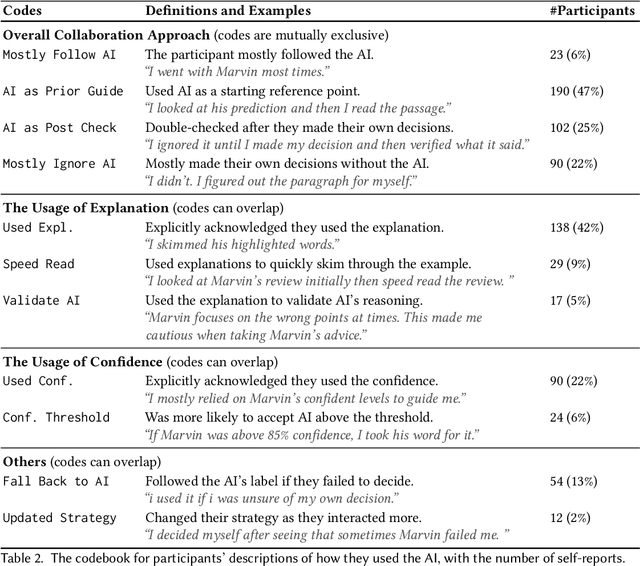
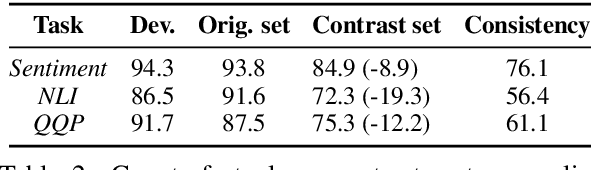
Increasingly, organizations are pairing humans with AI systems to improve decision-making and reducing costs. Proponents of human-centered AI argue that team performance can even further improve when the AI model explains its recommendations. However, a careful analysis of existing literature reveals that prior studies observed improvements due to explanations only when the AI, alone, outperformed both the human and the best human-AI team. This raises an important question: can explanations lead to complementary performance, i.e., with accuracy higher than both the human and the AI working alone? We address this question by devising comprehensive studies on human-AI teaming, where participants solve a task with help from an AI system without explanations and from one with varying types of AI explanation support. We carefully controlled to ensure comparable human and AI accuracy across experiments on three NLP datasets (two for sentiment analysis and one for question answering). While we found complementary improvements from AI augmentation, they were not increased by state-of-the-art explanations compared to simpler strategies, such as displaying the AI's confidence. We show that explanations increase the chance that humans will accept the AI's recommendation regardless of whether the AI is correct. While this clarifies the gains in team performance from explanations in prior work, it poses new challenges for human-centered AI: how can we best design systems to produce complementary performance? Can we develop explanatory approaches that help humans decide whether and when to trust AI input?
Beyond Accuracy: Behavioral Testing of NLP models with CheckList
May 08, 2020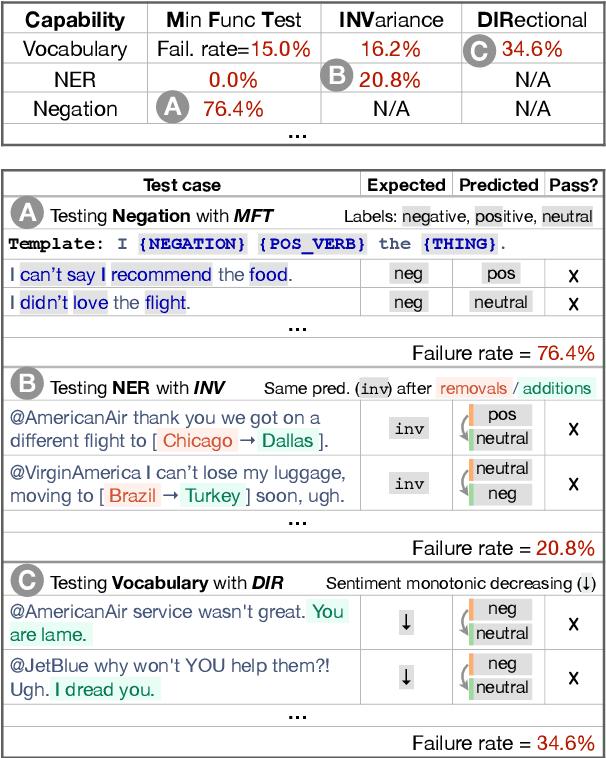
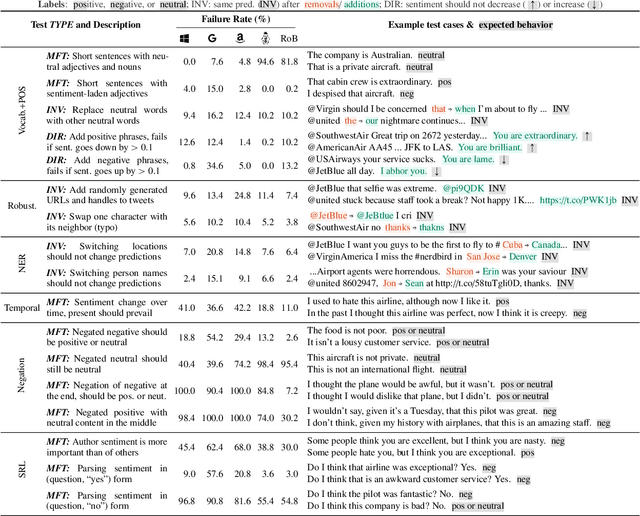
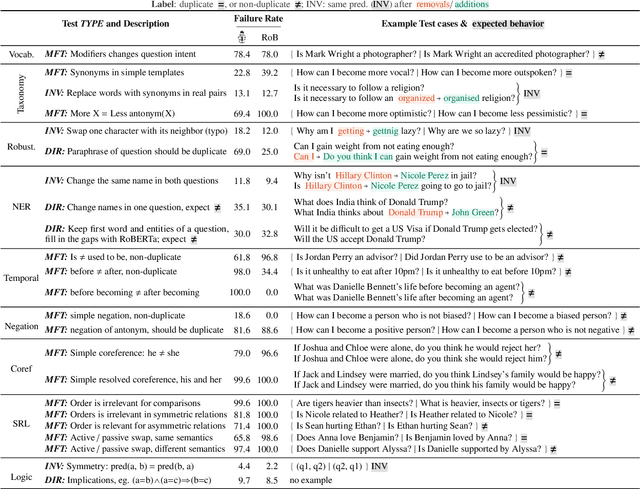
Although measuring held-out accuracy has been the primary approach to evaluate generalization, it often overestimates the performance of NLP models, while alternative approaches for evaluating models either focus on individual tasks or on specific behaviors. Inspired by principles of behavioral testing in software engineering, we introduce CheckList, a task-agnostic methodology for testing NLP models. CheckList includes a matrix of general linguistic capabilities and test types that facilitate comprehensive test ideation, as well as a software tool to generate a large and diverse number of test cases quickly. We illustrate the utility of CheckList with tests for three tasks, identifying critical failures in both commercial and state-of-art models. In a user study, a team responsible for a commercial sentiment analysis model found new and actionable bugs in an extensively tested model. In another user study, NLP practitioners with CheckList created twice as many tests, and found almost three times as many bugs as users without it.
Programs as Black-Box Explanations
Nov 22, 2016
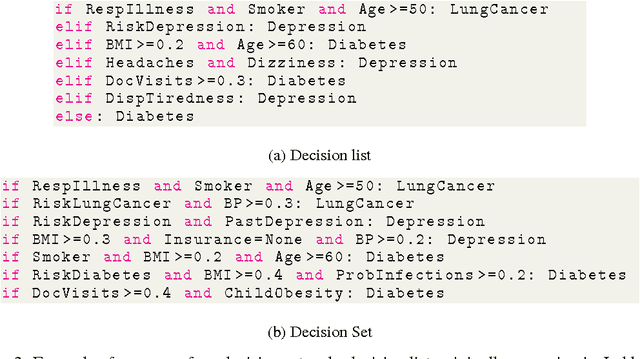
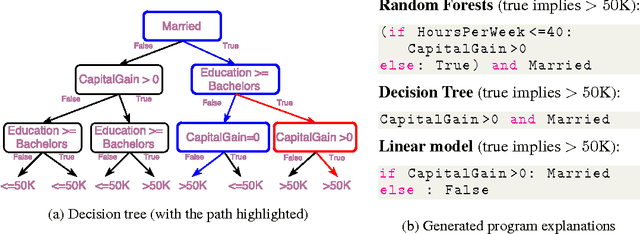
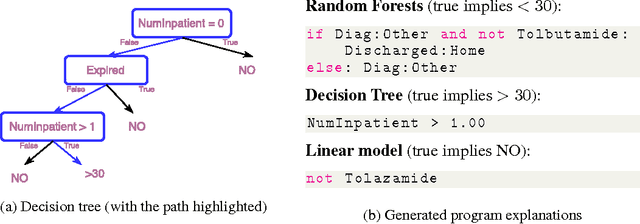
Recent work in model-agnostic explanations of black-box machine learning has demonstrated that interpretability of complex models does not have to come at the cost of accuracy or model flexibility. However, it is not clear what kind of explanations, such as linear models, decision trees, and rule lists, are the appropriate family to consider, and different tasks and models may benefit from different kinds of explanations. Instead of picking a single family of representations, in this work we propose to use "programs" as model-agnostic explanations. We show that small programs can be expressive yet intuitive as explanations, and generalize over a number of existing interpretable families. We propose a prototype program induction method based on simulated annealing that approximates the local behavior of black-box classifiers around a specific prediction using random perturbations. Finally, we present preliminary application on small datasets and show that the generated explanations are intuitive and accurate for a number of classifiers.
Nothing Else Matters: Model-Agnostic Explanations By Identifying Prediction Invariance
Nov 17, 2016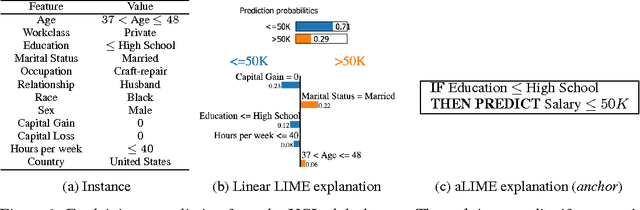

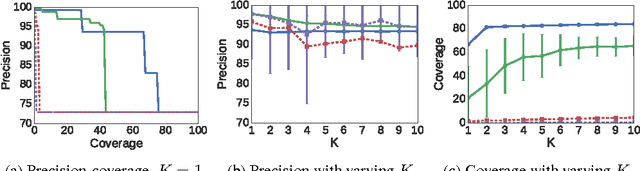

At the core of interpretable machine learning is the question of whether humans are able to make accurate predictions about a model's behavior. Assumed in this question are three properties of the interpretable output: coverage, precision, and effort. Coverage refers to how often humans think they can predict the model's behavior, precision to how accurate humans are in those predictions, and effort is either the up-front effort required in interpreting the model, or the effort required to make predictions about a model's behavior. In this work, we propose anchor-LIME (aLIME), a model-agnostic technique that produces high-precision rule-based explanations for which the coverage boundaries are very clear. We compare aLIME to linear LIME with simulated experiments, and demonstrate the flexibility of aLIME with qualitative examples from a variety of domains and tasks.
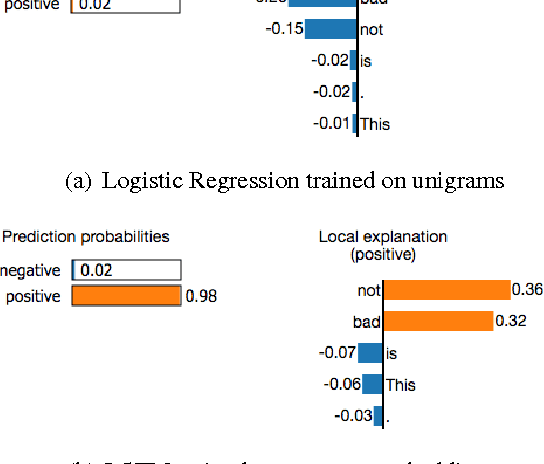
"Why Should I Trust You?": Explaining the Predictions of Any Classifier
Aug 09, 2016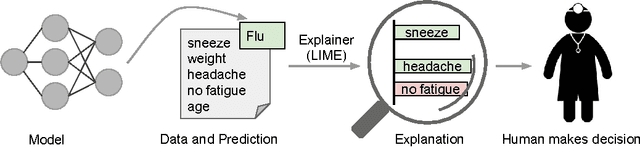
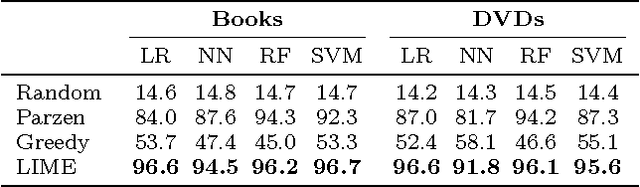


Despite widespread adoption, machine learning models remain mostly black boxes. Understanding the reasons behind predictions is, however, quite important in assessing trust, which is fundamental if one plans to take action based on a prediction, or when choosing whether to deploy a new model. Such understanding also provides insights into the model, which can be used to transform an untrustworthy model or prediction into a trustworthy one. In this work, we propose LIME, a novel explanation technique that explains the predictions of any classifier in an interpretable and faithful manner, by learning an interpretable model locally around the prediction. We also propose a method to explain models by presenting representative individual predictions and their explanations in a non-redundant way, framing the task as a submodular optimization problem. We demonstrate the flexibility of these methods by explaining different models for text (e.g. random forests) and image classification (e.g. neural networks). We show the utility of explanations via novel experiments, both simulated and with human subjects, on various scenarios that require trust: deciding if one should trust a prediction, choosing between models, improving an untrustworthy classifier, and identifying why a classifier should not be trusted.
Model-Agnostic Interpretability of Machine Learning
Jun 16, 2016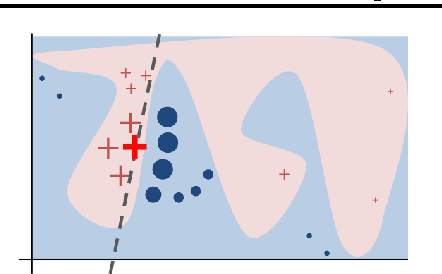
Understanding why machine learning models behave the way they do empowers both system designers and end-users in many ways: in model selection, feature engineering, in order to trust and act upon the predictions, and in more intuitive user interfaces. Thus, interpretability has become a vital concern in machine learning, and work in the area of interpretable models has found renewed interest. In some applications, such models are as accurate as non-interpretable ones, and thus are preferred for their transparency. Even when they are not accurate, they may still be preferred when interpretability is of paramount importance. However, restricting machine learning to interpretable models is often a severe limitation. In this paper we argue for explaining machine learning predictions using model-agnostic approaches. By treating the machine learning models as black-box functions, these approaches provide crucial flexibility in the choice of models, explanations, and representations, improving debugging, comparison, and interfaces for a variety of users and models. We also outline the main challenges for such methods, and review a recently-introduced model-agnostic explanation approach (LIME) that addresses these challenges.