 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Driven Separation of Arbitrary Sounds
Apr 12, 2022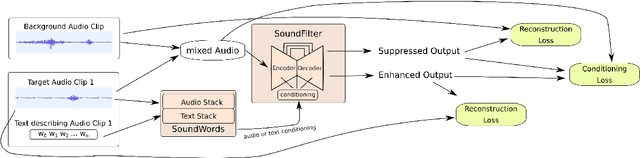

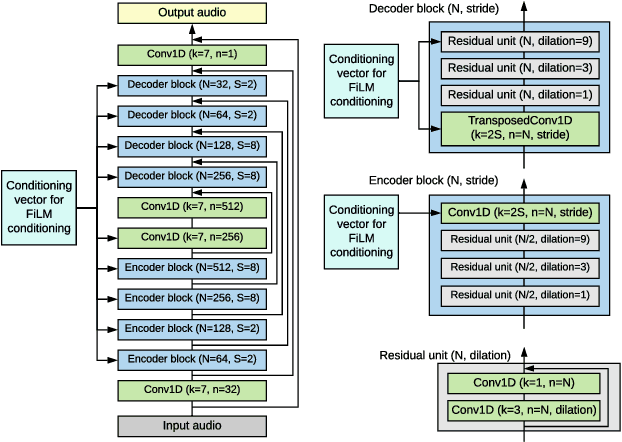
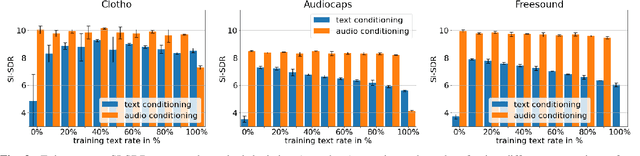
We propose a method of separating a desired sound source from a single-channel mixture, based on either a textual description or a short audio sample of the target source. This is achieved by combining two distinct models. The first model, SoundWords, is trained to jointly embed both an audio clip and its textual description to the same embedding in a shared representation. The second model, SoundFilter, takes a mixed source audio clip as an input and separates it based on a conditioning vector from the shared text-audio representation defined by SoundWords, making the model agnostic to the conditioning modality. Evaluating on multiple datasets, we show that our approach can achieve an SI-SDR of 9.1 dB for mixtures of two arbitrary sounds when conditioned on text and 10.1 dB when conditioned on audio. We also show that SoundWords is effective at learning co-embeddings and that our multi-modal training approach improves the performance of SoundFilter.
CycleGAN-Based Unpaired Speech Dereverberation
Mar 29, 2022

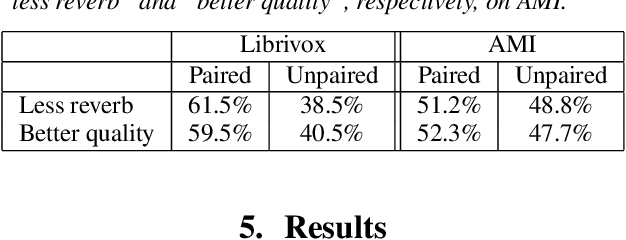
Typically, neural network-based speech dereverberation models are trained on paired data, composed of a dry utterance and its corresponding reverberant utterance. The main limitation of this approach is that such models can only be trained on large amounts of data and a variety of room impulse responses when the data is synthetically reverberated, since acquiring real paired data is costly. In this paper we propose a CycleGAN-based approach that enables dereverberation models to be trained on unpaired data. We quantify the impact of using unpaired data by comparing the proposed unpaired model to a paired model with the same architecture and trained on the paired version of the same dataset. We show that the performance of the unpaired model is comparable to the performance of the paired model on two different datasets, according to objective evaluation metrics. Furthermore, we run two subjective evaluations and show that both models achieve comparable subjective quality on the AMI dataset, which was not seen during training.
Disentangling speech from surroundings in a neural audio codec
Mar 29, 2022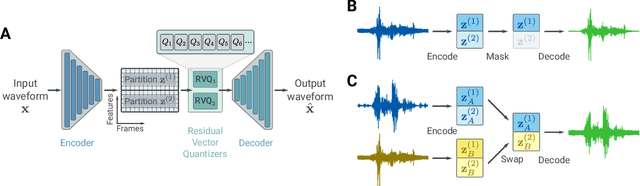
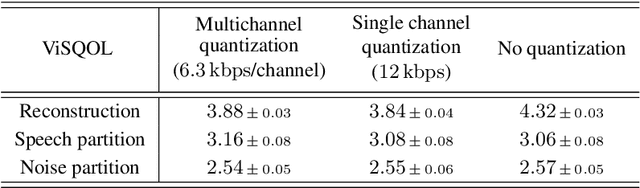
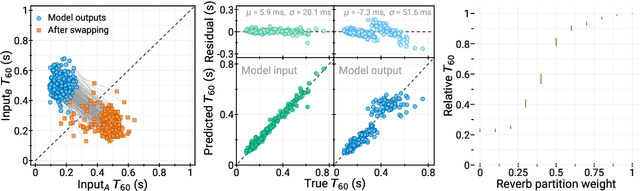
We present a method to separate speech signals from noisy environments in the compressed domain of a neural audio codec. We introduce a new training procedure that allows our model to produce structured encodings of audio waveforms given by embedding vectors, where one part of the embedding vector represents the speech signal, and the rest represents the environment. We achieve this by partitioning the embeddings of different input waveforms and training the model to faithfully reconstruct audio from mixed partitions, thereby ensuring each partition encodes a separate audio attribute. As use cases, we demonstrate the separation of speech from background noise or from reverberation characteristics. Our method also allows for targeted adjustments of the audio output characteristics.
Real time spectrogram inversion on mobile phone
Mar 10, 2022
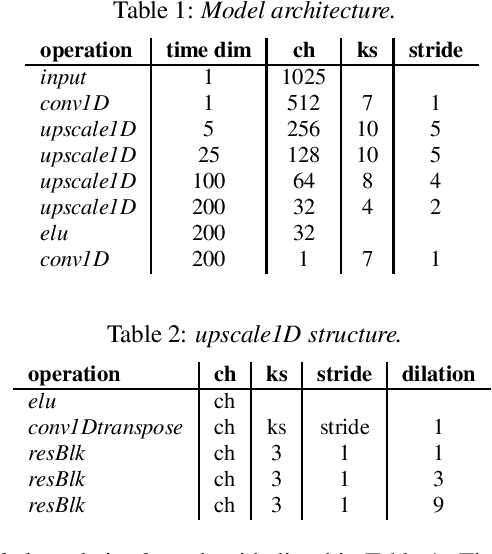

With the growth of computing power on mobile phones and privacy concerns over user's data, on-device real time speech processing has become an important research topic. In this paper, we focus on methods for real time spectrogram inversion, where an algorithm receives a portion of the input signal (e.g., one frame) and processes it incrementally, i.e., operating in streaming mode. We present a real time Griffin Lim(GL) algorithm using a sliding window approach in STFT domain. The proposed algorithm is 2.4x faster than real time on the ARM CPU of a Pixel4. In addition we explore a neural vocoder operating in streaming mode and demonstrate the impact of looking ahead on perceptual quality. As little as one hop size (12.5ms) of lookahead is able to significantly improve perceptual quality in comparison to a causal model. We compare GL with the neural vocoder and show different trade-offs in terms of perceptual quality, on-device latency, algorithmic delay, memory footprint and noise sensitivity. For fair quality assessment of the GL approach, we use input log magnitude spectrogram without mel transformation. We evaluate presented real time spectrogram inversion approaches on clean, noisy and atypical speech.
SpeechPainter: Text-conditioned Speech Inpainting
Feb 15, 2022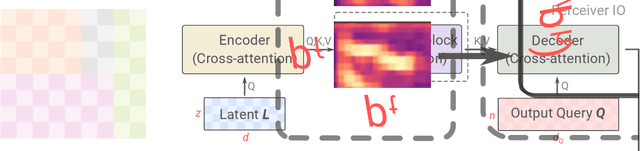
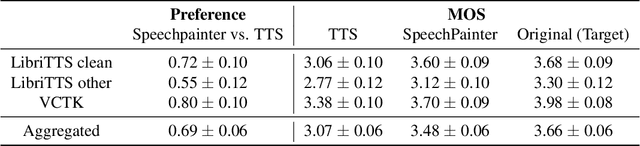
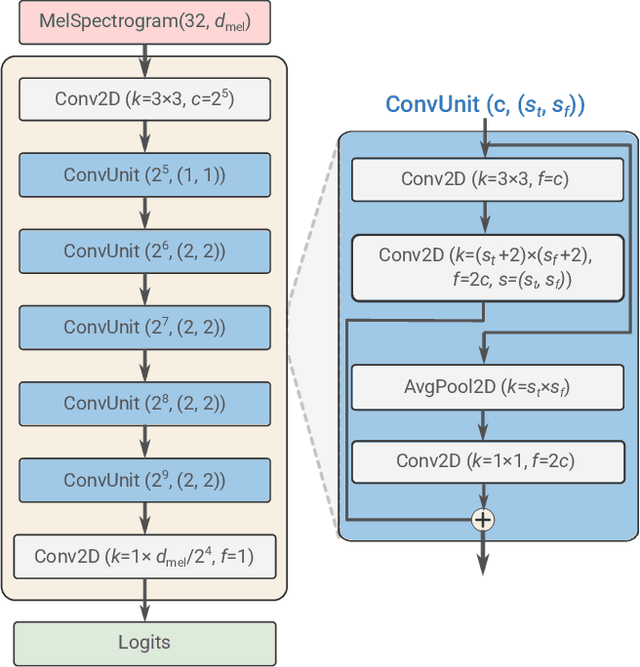
We propose SpeechPainter, a model for filling in gaps of up to one second in speech samples by leveraging an auxiliary textual input. We demonstrate that the model performs speech inpainting with the appropriate content, while maintaining speaker identity, prosody and recording environment conditions, and generalizing to unseen speakers. Our approach significantly outperforms baselines constructed using adaptive TTS, as judged by human raters in side-by-side preference and MOS tests.
Data Summarization via Bilevel Optimization
Sep 26, 2021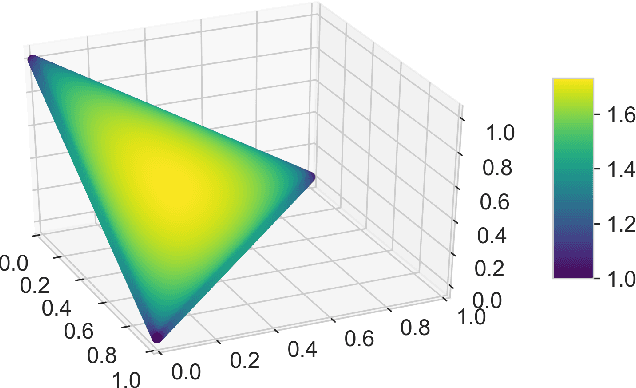
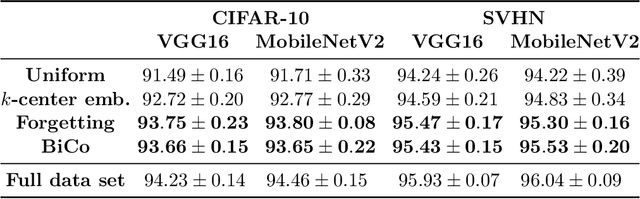

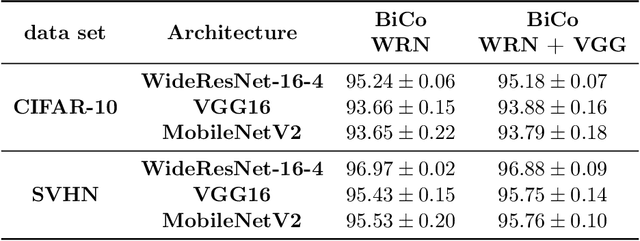
The increasing availability of massive data sets poses a series of challenges for machine learning. Prominent among these is the need to learn models under hardware or human resource constraints. In such resource-constrained settings, a simple yet powerful approach is to operate on small subsets of the data. Coresets are weighted subsets of the data that provide approximation guarantees for the optimization objective. However, existing coreset constructions are highly model-specific and are limited to simple models such as linear regression, logistic regression, and $k$-means. In this work, we propose a generic coreset construction framework that formulates the coreset selection as a cardinality-constrained bilevel optimization problem. In contrast to existing approaches, our framework does not require model-specific adaptations and applies to any twice differentiable model, including neural networks. We show the effectiveness of our framework for a wide range of models in various settings, including training non-convex models online and batch active learning.
SoundStream: An End-to-End Neural Audio Codec
Jul 07, 2021



We present SoundStream, a novel neural audio codec that can efficiently compress speech, music and general audio at bitrates normally targeted by speech-tailored codecs. SoundStream relies on a model architecture composed by a fully convolutional encoder/decoder network and a residual vector quantizer, which are trained jointly end-to-end. Training leverages recent advances in text-to-speech and speech enhancement, which combine adversarial and reconstruction losses to allow the generation of high-quality audio content from quantized embeddings. By training with structured dropout applied to quantizer layers, a single model can operate across variable bitrates from 3kbps to 18kbps, with a negligible quality loss when compared with models trained at fixed bitrates. In addition, the model is amenable to a low latency implementation, which supports streamable inference and runs in real time on a smartphone CPU. In subjective evaluations using audio at 24kHz sampling rate, SoundStream at 3kbps outperforms Opus at 12kbps and approaches EVS at 9.6kbps. Moreover, we are able to perform joint compression and enhancement either at the encoder or at the decoder side with no additional latency, which we demonstrate through background noise suppression for speech.
Self-Supervised Learning from Automatically Separated Sound Scenes
May 05, 2021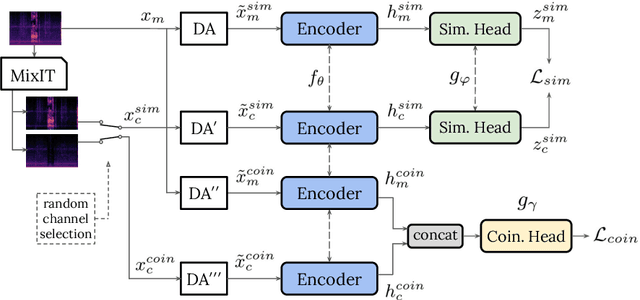
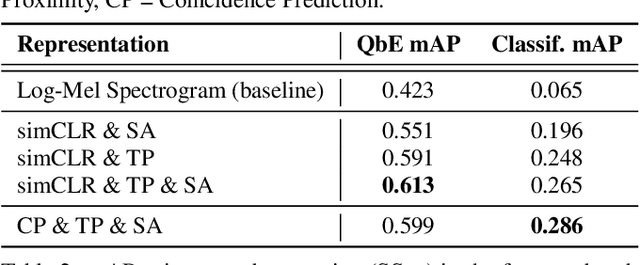

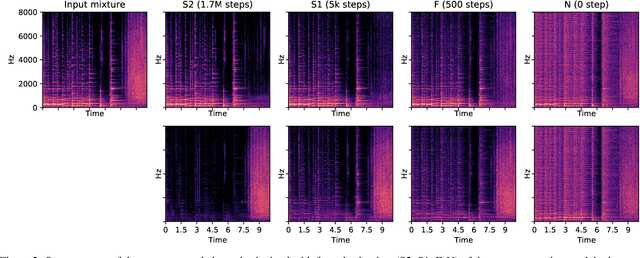
Real-world sound scenes consist of time-varying collections of sound sources, each generating characteristic sound events that are mixed together in audio recordings. The association of these constituent sound events with their mixture and each other is semantically constrained: the sound scene contains the union of source classes and not all classes naturally co-occur. With this motivation, this paper explores the use of unsupervised automatic sound separation to decompose unlabeled sound scenes into multiple semantically-linked views for use in self-supervised contrastive learning. We find that learning to associate input mixtures with their automatically separated outputs yields stronger representations than past approaches that use the mixtures alone. Further, we discover that optimal source separation is not required for successful contrastive learning by demonstrating that a range of separation system convergence states all lead to useful and often complementary example transformations. Our best system incorporates these unsupervised separation models into a single augmentation front-end and jointly optimizes similarity maximization and coincidence prediction objectives across the views. The result is an unsupervised audio representation that rivals state-of-the-art alternatives on the established shallow AudioSet classification benchmark.
LEAF: A Learnable Frontend for Audio Classification
Jan 21, 2021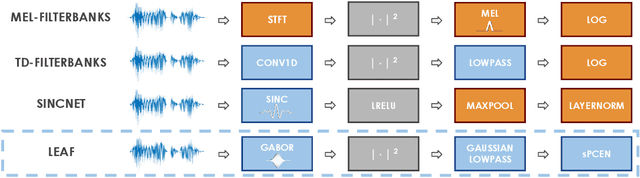
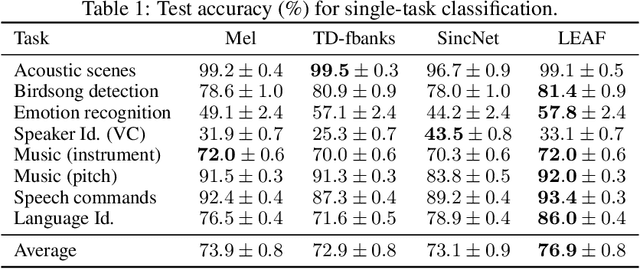
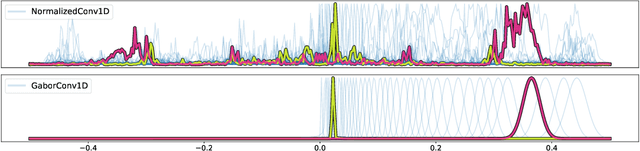

Mel-filterbanks are fixed, engineered audio features which emulate human perception and have been used through the history of audio understanding up to today. However, their undeniable qualities are counterbalanced by the fundamental limitations of handmade representations. In this work we show that we can train a single learnable frontend that outperforms mel-filterbanks on a wide range of audio signals, including speech, music, audio events and animal sounds, providing a general-purpose learned frontend for audio classification. To do so, we introduce a new principled, lightweight, fully learnable architecture that can be used as a drop-in replacement of mel-filterbanks. Our system learns all operations of audio features extraction, from filtering to pooling, compression and normalization, and can be integrated into any neural network at a negligible parameter cost. We perform multi-task training on eight diverse audio classification tasks, and show consistent improvements of our model over mel-filterbanks and previous learnable alternatives. Moreover, our system outperforms the current state-of-the-art learnable frontend on Audioset, with orders of magnitude fewer parameters.
MicAugment: One-shot Microphone Style Transfer
Oct 19, 2020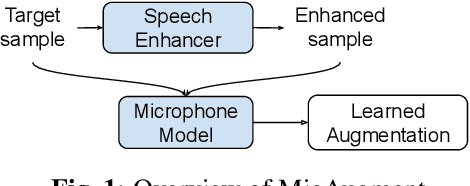
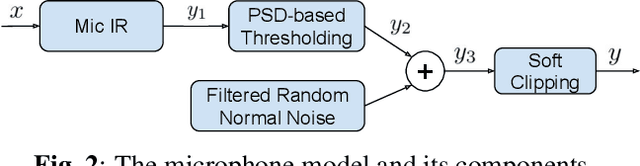

A crucial aspect for the successful deployment of audio-based models "in-the-wild" is the robustness to the transformations introduced by heterogeneous acquisition conditions. In this work, we propose a method to perform one-shot microphone style transfer. Given only a few seconds of audio recorded by a target device, MicAugment identifies the transformations associated to the input acquisition pipeline and uses the learned transformations to synthesize audio as if it were recorded under the same conditions as the target audio. We show that our method can successfully apply the style transfer to real audio and that it significantly increases model robustness when used as data augmentation in the downstream tasks.