 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-in-the-Loop for Data Collection: a Multi-Target Counter Narrative Dataset to Fight Online Hate Speech
Jul 19, 2021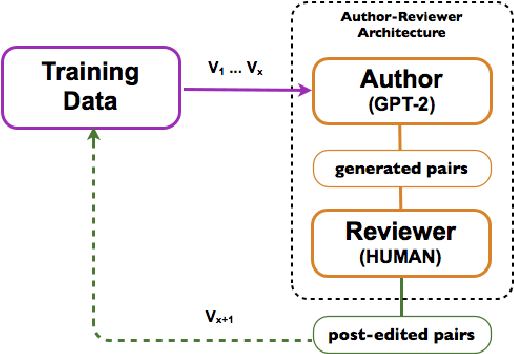
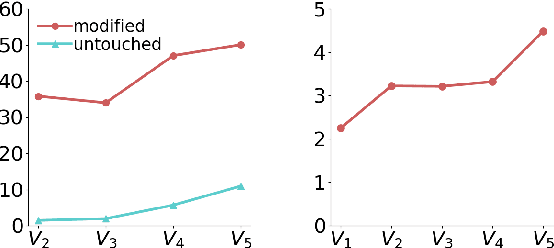
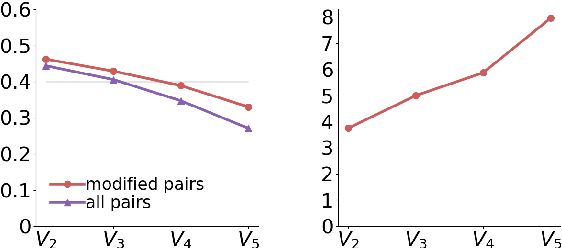
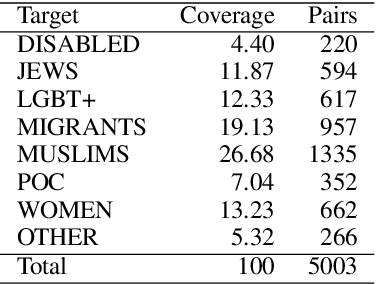
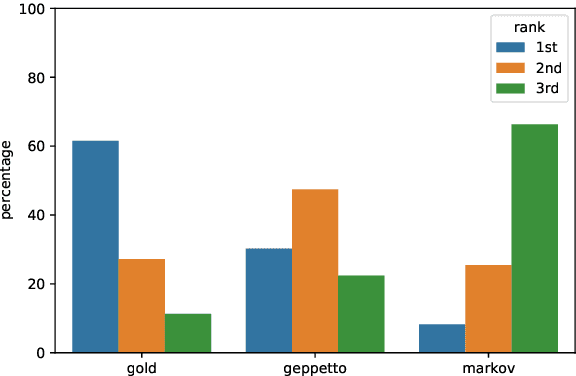
Undermining the impact of hateful content with informed and non-aggressive responses, called counter narratives, has emerged as a possible solution for having healthier online communities. Thus, some NLP studies have started addressing the task of counter narrative generation. Although such studies have made an effort to build hate speech / counter narrative (HS/CN) datasets for neural generation, they fall short in reaching either high-quality and/or high-quantity. In this paper, we propose a novel human-in-the-loop data collection methodology in which a generative language model is refined iteratively by using its own data from the previous loops to generate new training samples that experts review and/or post-edit. Our experiments comprised several loops including dynamic variations. Results show that the methodology is scalable and facilitates diverse, novel, and cost-effective data collection. To our knowledge, the resulting dataset is the only expert-based multi-target HS/CN dataset available to the community.
Empowering NGOs in Countering Online Hate Messages
Jul 06, 2021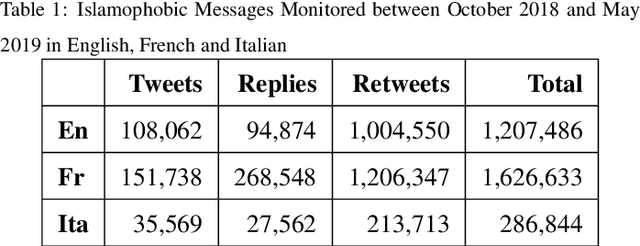
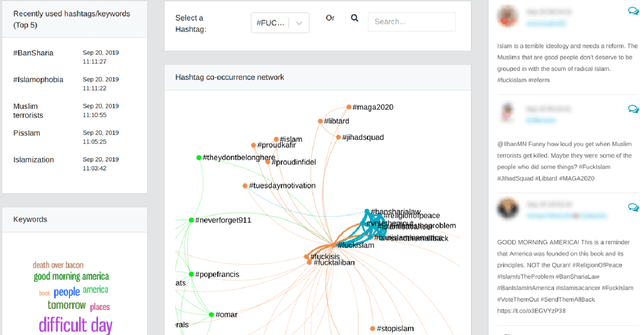
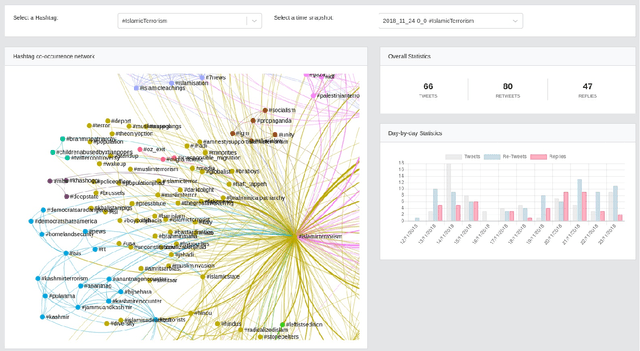
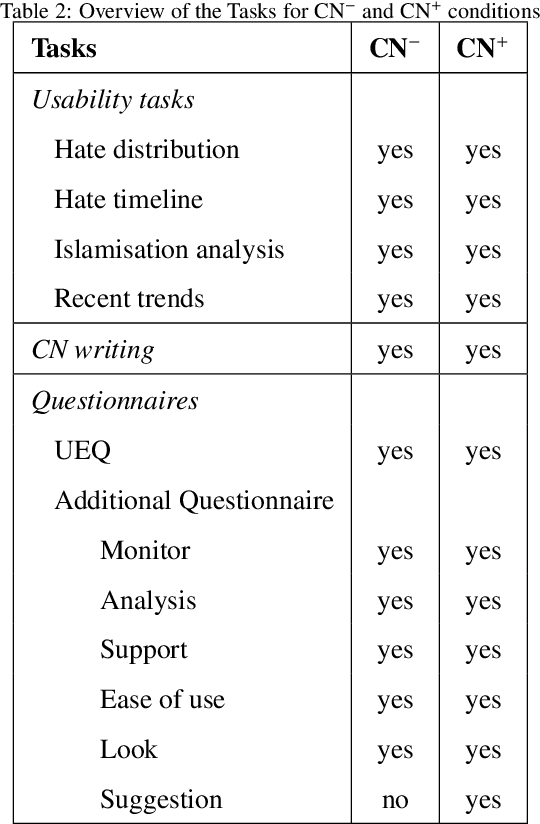
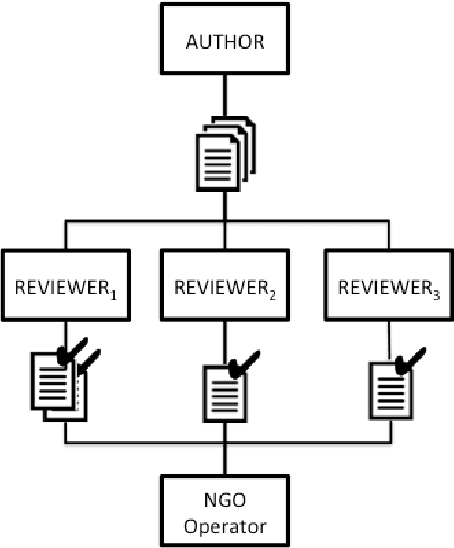
Studies on online hate speech have mostly focused on the automated detection of harmful messages. Little attention has been devoted so far to the development of effective strategies to fight hate speech, in particular through the creation of counter-messages. While existing manual scrutiny and intervention strategies are time-consuming and not scalable, advances in natural language processing have the potential to provide a systematic approach to hatred management. In this paper, we introduce a novel ICT platform that NGO operators can use to monitor and analyze social media data, along with a counter-narrative suggestion tool. Our platform aims at increasing the efficiency and effectiveness of operators' activities against islamophobia. We test the platform with more than one hundred NGO operators in three countries through qualitative and quantitative evaluation. Results show that NGOs favor the platform solution with the suggestion tool, and that the time required to produce counter-narratives significantly decreases.
Towards Knowledge-Grounded Counter Narrative Generation for Hate Speech
Jun 22, 2021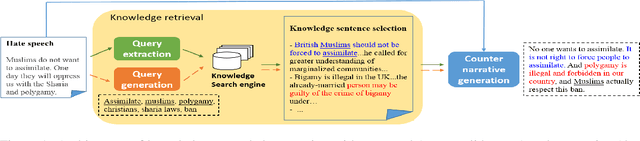
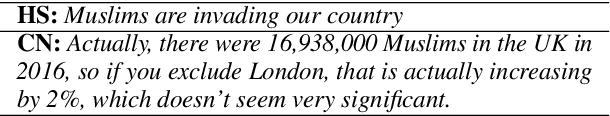

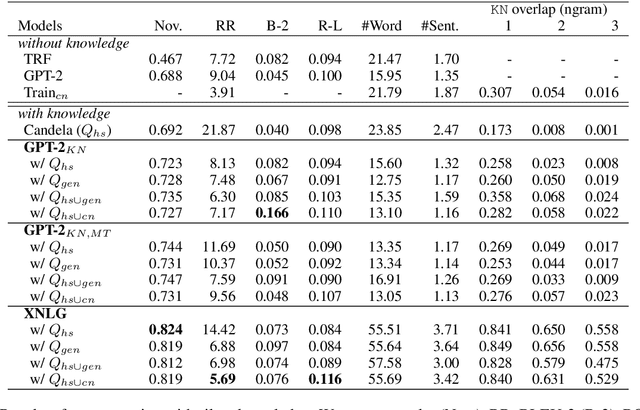
Tackling online hatred using informed textual responses - called counter narratives - has been brought under the spotlight recently. Accordingly, a research line has emerged to automatically generate counter narratives in order to facilitate the direct intervention in the hate discussion and to prevent hate content from further spreading. Still, current neural approaches tend to produce generic/repetitive responses and lack grounded and up-to-date evidence such as facts, statistics, or examples. Moreover, these models can create plausible but not necessarily true arguments. In this paper we present the first complete knowledge-bound counter narrative generation pipeline, grounded in an external knowledge repository that can provide more informative content to fight online hatred. Together with our approach, we present a series of experiments that show its feasibility to produce suitable and informative counter narratives in in-domain and cross-domain settings.
Toward Stance-based Personas for Opinionated Dialogues
Oct 07, 2020


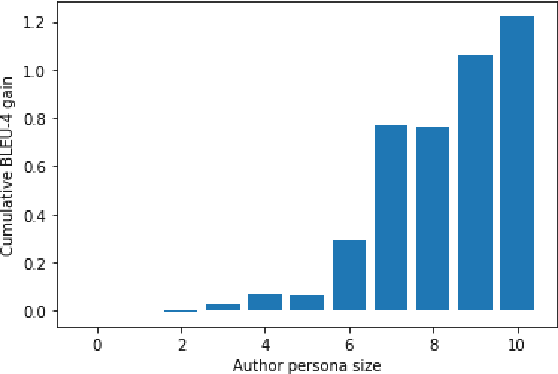
In the context of chit-chat dialogues it has been shown that endowing systems with a persona profile is important to produce more coherent and meaningful conversations. Still, the representation of such personas has thus far been limited to a fact-based representation (e.g. "I have two cats."). We argue that these representations remain superficial w.r.t. the complexity of human personality. In this work, we propose to make a step forward and investigate stance-based persona, trying to grasp more profound characteristics, such as opinions, values, and beliefs to drive language generation. To this end, we introduce a novel dataset allowing to explore different stance-based persona representations and their impact on claim generation, showing that they are able to grasp abstract and profound aspects of the author persona.
GePpeTto Carves Italian into a Language Model
Apr 29, 2020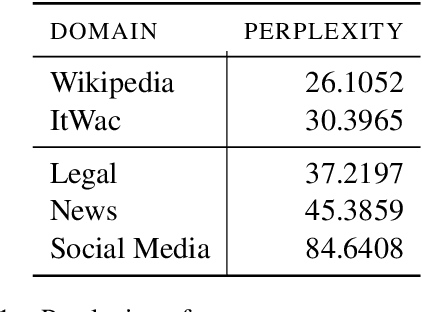
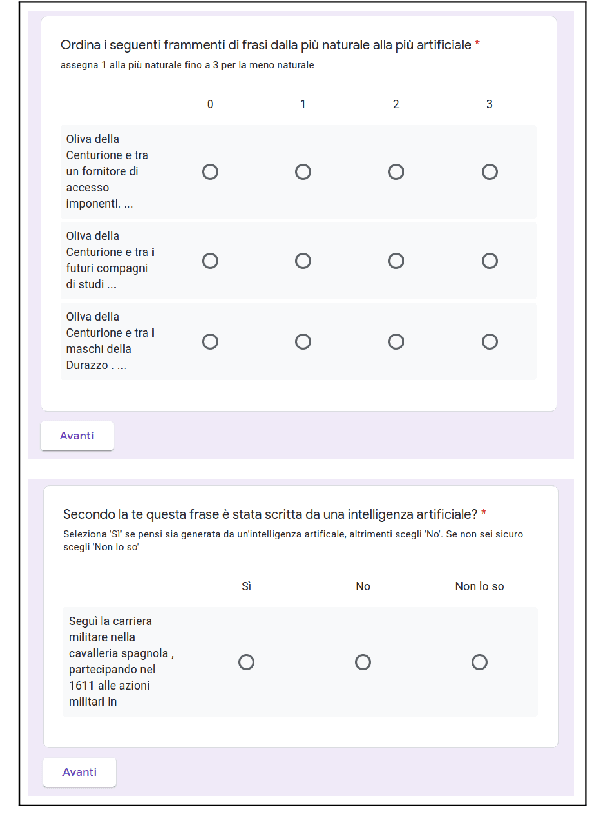
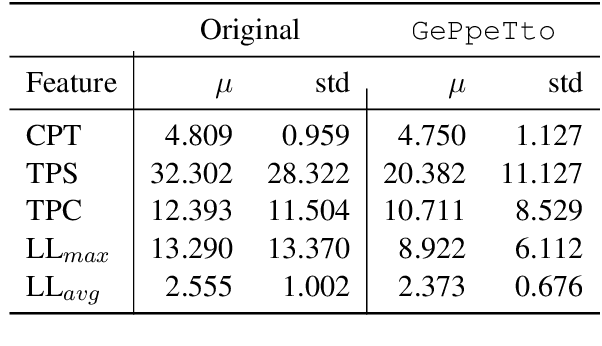
In the last few years, pre-trained neural architectures have provided impressive improvements across several NLP tasks. Still, generative language models are available mainly for English. We develop GePpeTto, the first generative language model for Italian, built using the GPT-2 architecture. We provide a thorough analysis of GePpeTto's quality by means of both an automatic and a human-based evaluation. The automatic assessment consists in (i) calculating perplexity across different genres and (ii) a profiling analysis over GePpeTto's writing characteristics. We find that GePpeTto's production is a sort of bonsai version of human production, with shorter but yet complex sentences. Human evaluation is performed over a sentence completion task, where GePpeTto's output is judged as natural more often than not, and much closer to the original human texts than to a simpler language model which we take as baseline.
Generating Counter Narratives against Online Hate Speech: Data and Strategies
Apr 08, 2020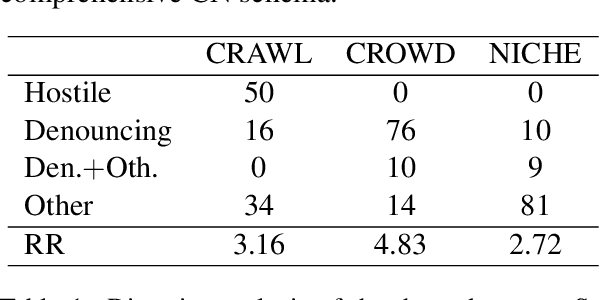

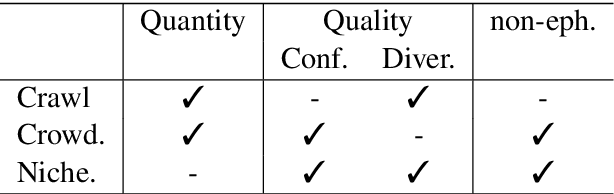
Recently research has started focusing on avoiding undesired effects that come with content moderation, such as censorship and overblocking, when dealing with hatred online. The core idea is to directly intervene in the discussion with textual responses that are meant to counter the hate content and prevent it from further spreading. Accordingly, automation strategies, such as natural language generation, are beginning to be investigated. Still, they suffer from the lack of sufficient amount of quality data and tend to produce generic/repetitive responses. Being aware of the aforementioned limitations, we present a study on how to collect responses to hate effectively, employing large scale unsupervised language models such as GPT-2 for the generation of silver data, and the best annotation strategies/neural architectures that can be used for data filtering before expert validation/post-editing.
Generating Challenge Datasets for Task-Oriented Conversational Agents through Self-Play
Oct 16, 2019



End-to-end neural approaches are becoming increasingly common in conversational scenarios due to their promising performances when provided with sufficient amount of data. In this paper, we present a novel methodology to address the interpretability of neural approaches in such scenarios by creating challenge datasets using dialogue self-play over multiple tasks/intents. Dialogue self-play allows generating large amount of synthetic data; by taking advantage of the complete control over the generation process, we show how neural approaches can be evaluated in terms of unseen dialogue patterns. We propose several out-of-pattern test cases each of which introduces a natural and unexpected user utterance phenomenon. As a proof of concept, we built a single and a multiple memory network, and show that these two architectures have diverse performances depending on the peculiar dialogue patterns.
DepecheMood++: a Bilingual Emotion Lexicon Built Through Simple Yet Powerful Techniques
Oct 08, 2018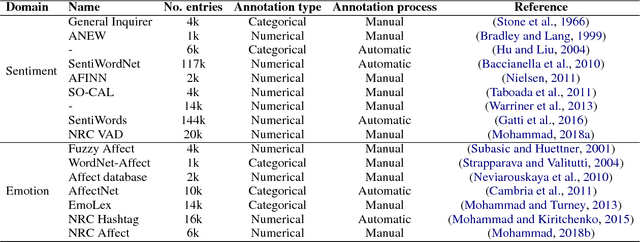
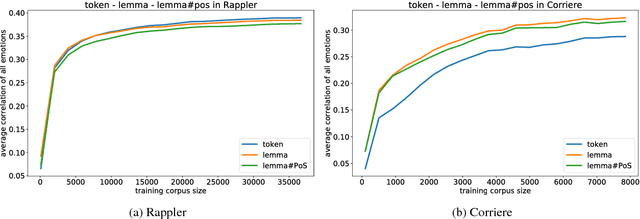
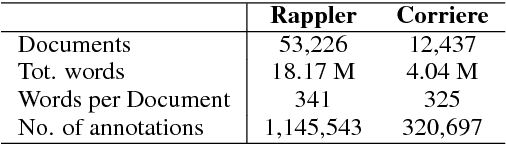
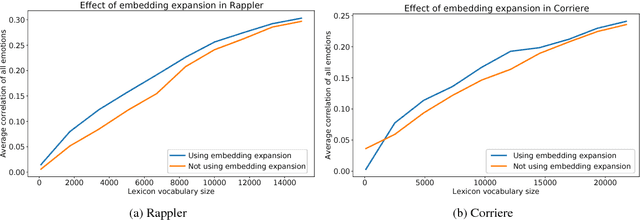
Several lexica for sentiment analysis have been developed and made available in the NLP community. While most of these come with word polarity annotations (e.g. positive/negative), attempts at building lexica for finer-grained emotion analysis (e.g. happiness, sadness) have recently attracted significant attention. Such lexica are often exploited as a building block in the process of developing learning models for which emotion recognition is needed, and/or used as baselines to which compare the performance of the models. In this work, we contribute two new resources to the community: a) an extension of an existing and widely used emotion lexicon for English; and b) a novel version of the lexicon targeting Italian. Furthermore, we show how simple techniques can be used, both in supervised and unsupervised experimental settings, to boost performances on datasets and tasks of varying degree of domain-specificity.
Fortia-FBK at SemEval-2017 Task 5: Bullish or Bearish? Inferring Sentiment towards Brands from Financial News Headlines
Apr 04, 2017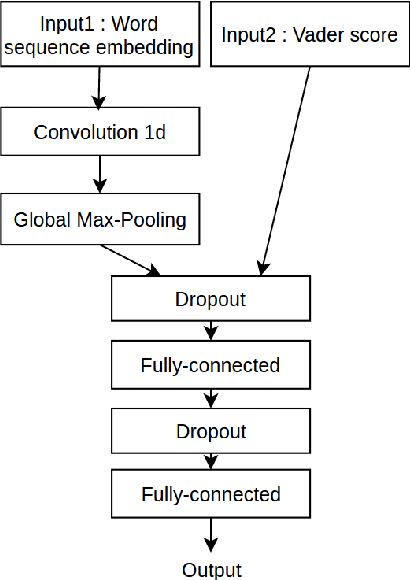


In this paper, we describe a methodology to infer Bullish or Bearish sentiment towards companies/brands. More specifically, our approach leverages affective lexica and word embeddings in combination with convolutional neural networks to infer the sentiment of financial news headlines towards a target company. Such architecture was used and evaluated in the context of the SemEval 2017 challenge (task 5, subtask 2), in which it obtained the best performance.
Why Do Urban Legends Go Viral?
Jan 22, 2016
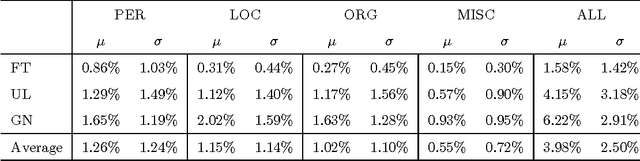
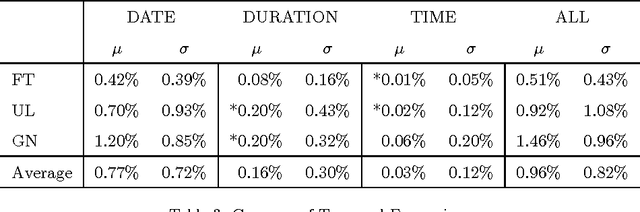
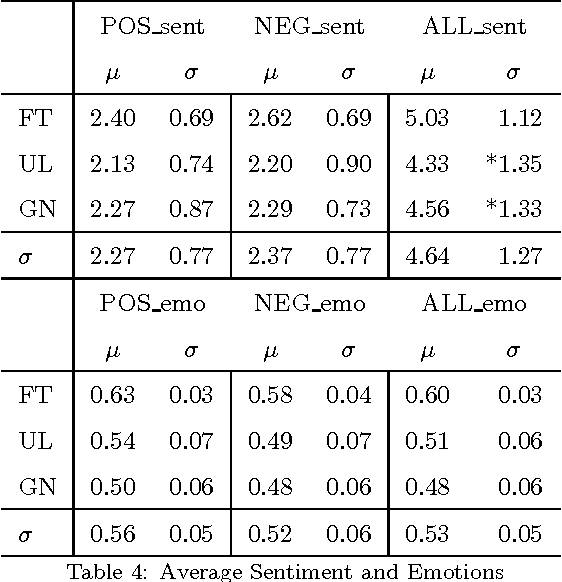
Urban legends are a genre of modern folklore, consisting of stories about rare and exceptional events, just plausible enough to be believed, which tend to propagate inexorably across communities. In our view, while urban legends represent a form of "sticky" deceptive text, they are marked by a tension between the credible and incredible. They should be credible like a news article and incredible like a fairy tale to go viral. In particular we will focus on the idea that urban legends should mimic the details of news (who, where, when) to be credible, while they should be emotional and readable like a fairy tale to be catchy and memorable. Using NLP tools we will provide a quantitative analysis of these prototypical characteristics. We also lay out some machine learning experiments showing that it is possible to recognize an urban legend using just these simple features.