 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat you can cram into a single vector: Probing sentence embeddings for linguistic properties
Jul 08, 2018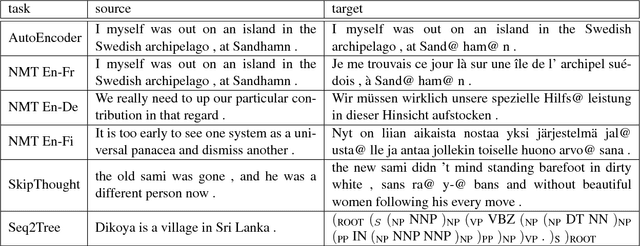
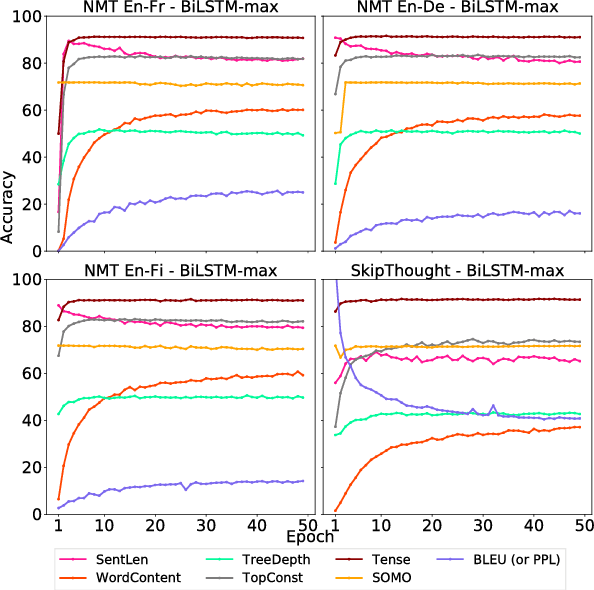
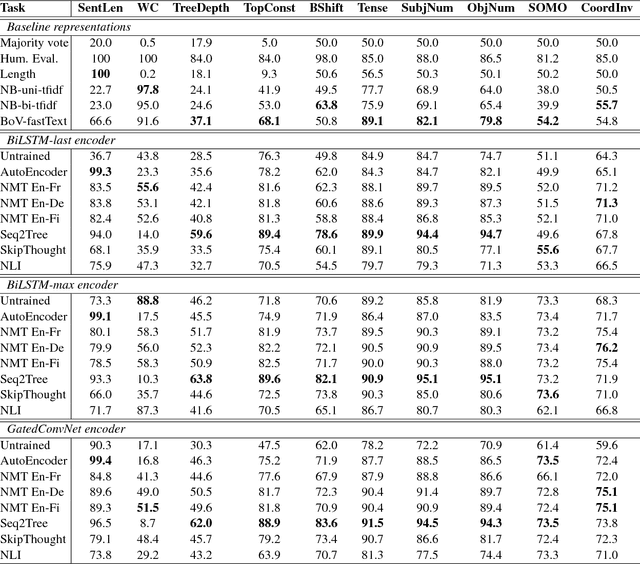
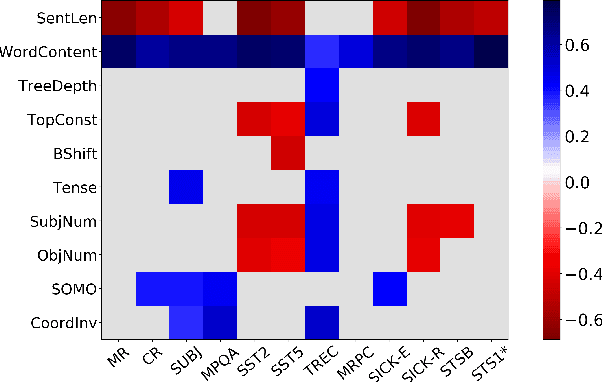
Although much effort has recently been devoted to training high-quality sentence embeddings, we still have a poor understanding of what they are capturing. "Downstream" tasks, often based on sentence classification, are commonly used to evaluate the quality of sentence representations. The complexity of the tasks makes it however difficult to infer what kind of information is present in the representations. We introduce here 10 probing tasks designed to capture simple linguistic features of sentences, and we use them to study embeddings generated by three different encoders trained in eight distinct ways, uncovering intriguing properties of both encoders and training methods.
Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks
Jun 06, 2018

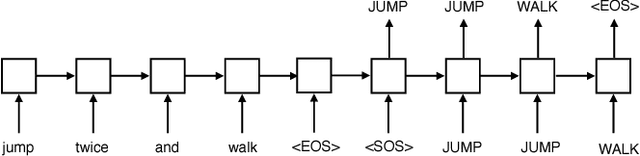
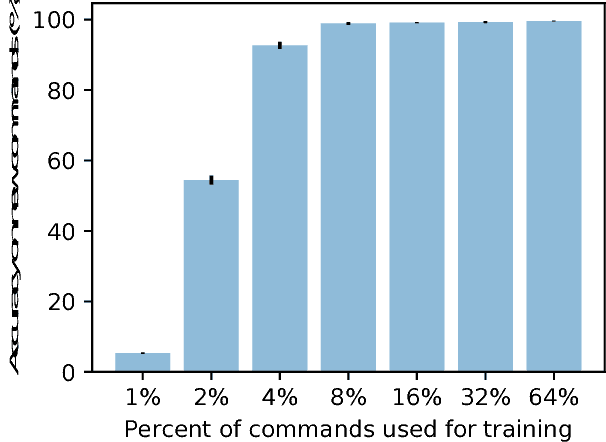
Humans can understand and produce new utterances effortlessly, thanks to their compositional skills. Once a person learns the meaning of a new verb "dax," he or she can immediately understand the meaning of "dax twice" or "sing and dax." In this paper, we introduce the SCAN domain, consisting of a set of simple compositional navigation commands paired with the corresponding action sequences. We then test the zero-shot generalization capabilities of a variety of recurrent neural networks (RNNs) trained on SCAN with sequence-to-sequence methods. We find that RNNs can make successful zero-shot generalizations when the differences between training and test commands are small, so that they can apply "mix-and-match" strategies to solve the task. However, when generalization requires systematic compositional skills (as in the "dax" example above), RNNs fail spectacularly. We conclude with a proof-of-concept experiment in neural machine translation, suggesting that lack of systematicity might be partially responsible for neural networks' notorious training data thirst.
* Published at the 35th International Conference on Machine Learning (ICML 2018)
Colorless green recurrent networks dream hierarchically
Mar 29, 2018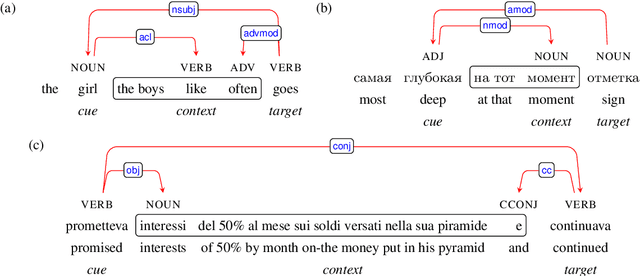
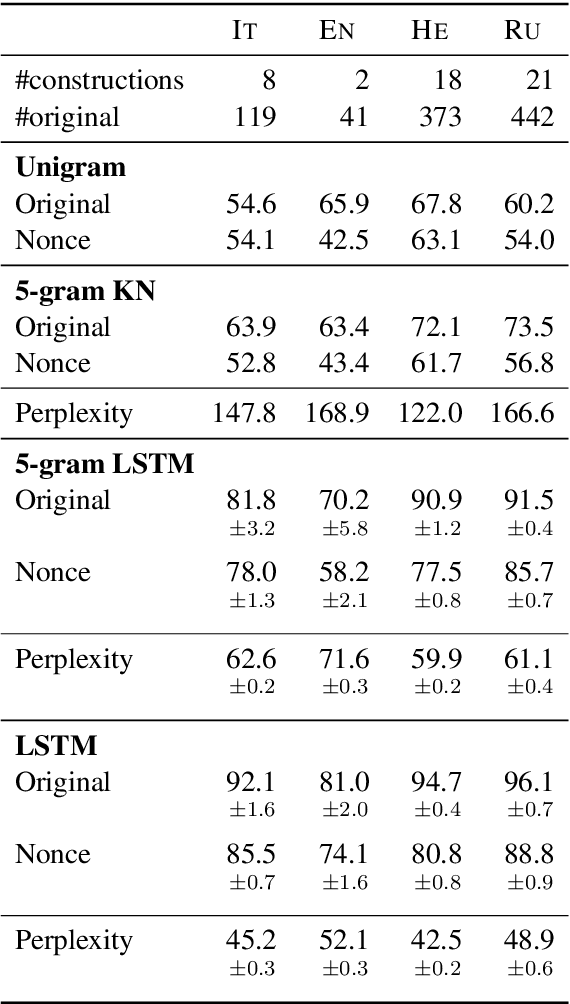
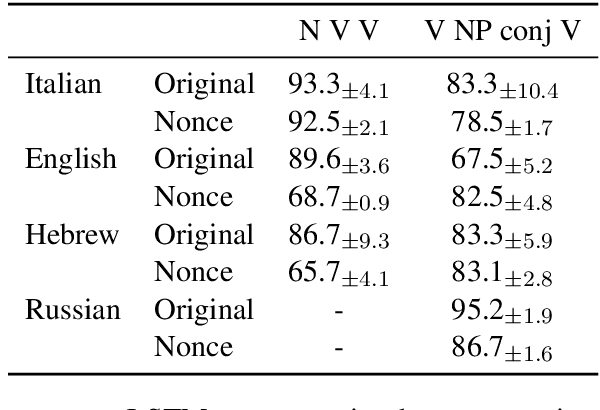
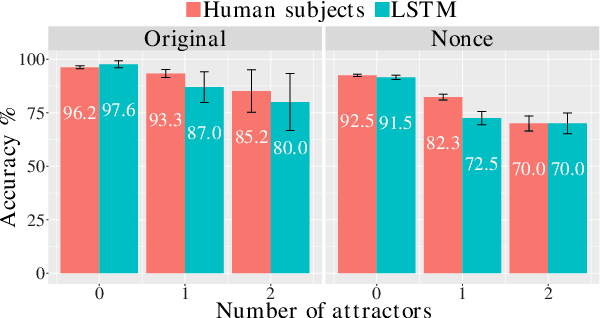
Recurrent neural networks (RNNs) have achieved impressive results in a variety of linguistic processing tasks, suggesting that they can induce non-trivial properties of language. We investigate here to what extent RNNs learn to track abstract hierarchical syntactic structure. We test whether RNNs trained with a generic language modeling objective in four languages (Italian, English, Hebrew, Russian) can predict long-distance number agreement in various constructions. We include in our evaluation nonsensical sentences where RNNs cannot rely on semantic or lexical cues ("The colorless green ideas I ate with the chair sleep furiously"), and, for Italian, we compare model performance to human intuitions. Our language-model-trained RNNs make reliable predictions about long-distance agreement, and do not lag much behind human performance. We thus bring support to the hypothesis that RNNs are not just shallow-pattern extractors, but they also acquire deeper grammatical competence.
Living a discrete life in a continuous world: Reference with distributed representations
Sep 04, 2017
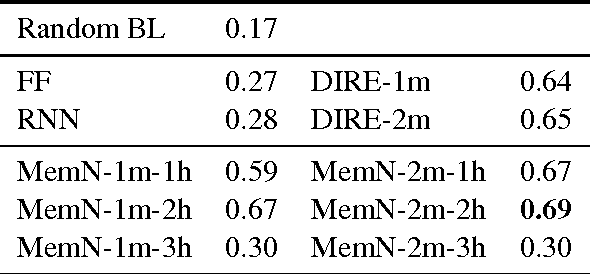
Reference is a crucial property of language that allows us to connect linguistic expressions to the world. Modeling it requires handling both continuous and discrete aspects of meaning. Data-driven models excel at the former, but struggle with the latter, and the reverse is true for symbolic models. This paper (a) introduces a concrete referential task to test both aspects, called cross-modal entity tracking; (b) proposes a neural network architecture that uses external memory to build an entity library inspired in the DRSs of DRT, with a mechanism to dynamically introduce new referents or add information to referents that are already in the library. Our model shows promise: it beats traditional neural network architectures on the task. However, it is still outperformed by Memory Networks, another model with external memory.
High-risk learning: acquiring new word vectors from tiny data
Jul 20, 2017
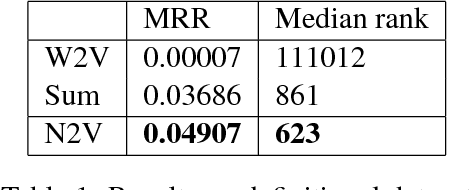
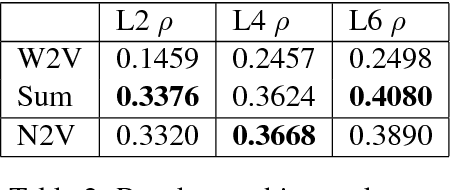
Distributional semantics models are known to struggle with small data. It is generally accepted that in order to learn 'a good vector' for a word, a model must have sufficient examples of its usage. This contradicts the fact that humans can guess the meaning of a word from a few occurrences only. In this paper, we show that a neural language model such as Word2Vec only necessitates minor modifications to its standard architecture to learn new terms from tiny data, using background knowledge from a previously learnt semantic space. We test our model on word definitions and on a nonce task involving 2-6 sentences' worth of context, showing a large increase in performance over state-of-the-art models on the definitional task.
CommAI: Evaluating the first steps towards a useful general AI
Mar 27, 2017With machine learning successfully applied to new daunting problems almost every day, general AI starts looking like an attainable goal. However, most current research focuses instead on important but narrow applications, such as image classification or machine translation. We believe this to be largely due to the lack of objective ways to measure progress towards broad machine intelligence. In order to fill this gap, we propose here a set of concrete desiderata for general AI, together with a platform to test machines on how well they satisfy such desiderata, while keeping all further complexities to a minimum.
Multi-Agent Cooperation and the Emergence of Language
Mar 05, 2017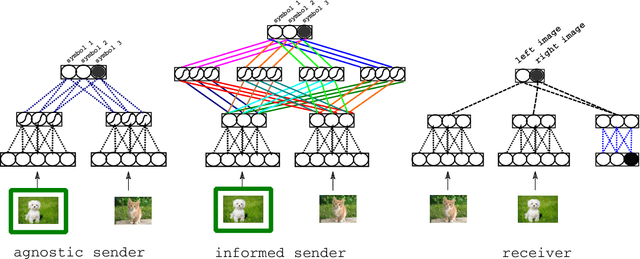
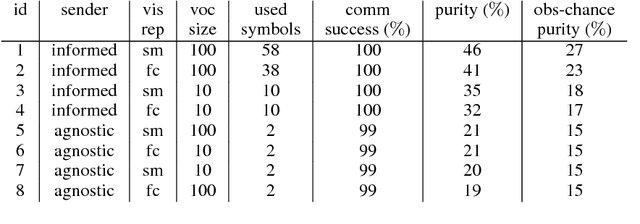
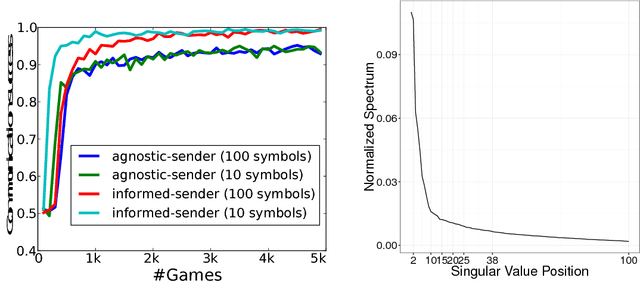
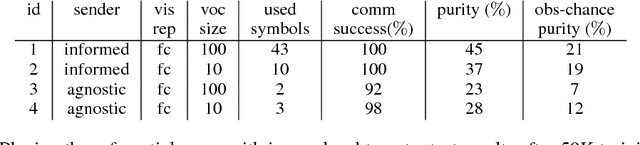
The current mainstream approach to train natural language systems is to expose them to large amounts of text. This passive learning is problematic if we are interested in developing interactive machines, such as conversational agents. We propose a framework for language learning that relies on multi-agent communication. We study this learning in the context of referential games. In these games, a sender and a receiver see a pair of images. The sender is told one of them is the target and is allowed to send a message from a fixed, arbitrary vocabulary to the receiver. The receiver must rely on this message to identify the target. Thus, the agents develop their own language interactively out of the need to communicate. We show that two networks with simple configurations are able to learn to coordinate in the referential game. We further explore how to make changes to the game environment to cause the "word meanings" induced in the game to better reflect intuitive semantic properties of the images. In addition, we present a simple strategy for grounding the agents' code into natural language. Both of these are necessary steps towards developing machines that are able to communicate with humans productively.
Causal Discovery Using Proxy Variables
Feb 23, 2017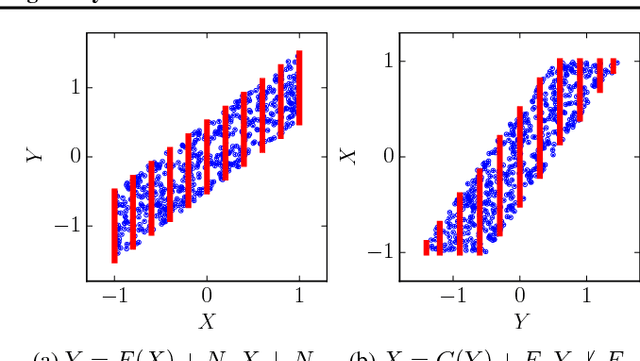
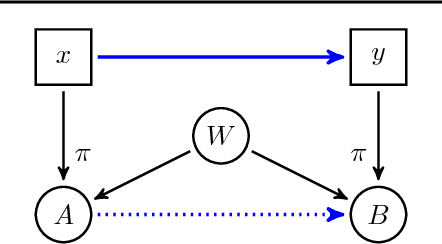
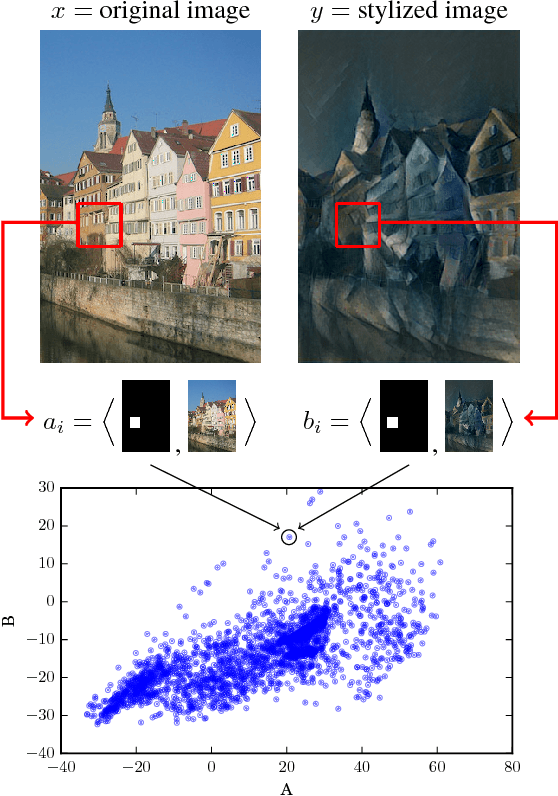

Discovering causal relations is fundamental to reasoning and intelligence. In particular, observational causal discovery algorithms estimate the cause-effect relation between two random entities $X$ and $Y$, given $n$ samples from $P(X,Y)$. In this paper, we develop a framework to estimate the cause-effect relation between two static entities $x$ and $y$: for instance, an art masterpiece $x$ and its fraudulent copy $y$. To this end, we introduce the notion of proxy variables, which allow the construction of a pair of random entities $(A,B)$ from the pair of static entities $(x,y)$. Then, estimating the cause-effect relation between $A$ and $B$ using an observational causal discovery algorithm leads to an estimation of the cause-effect relation between $x$ and $y$. For example, our framework detects the causal relation between unprocessed photographs and their modifications, and orders in time a set of shuffled frames from a video. As our main case study, we introduce a human-elicited dataset of 10,000 pairs of casually-linked pairs of words from natural language. Our methods discover 75% of these causal relations. Finally, we discuss the role of proxy variables in machine learning, as a general tool to incorporate static knowledge into prediction tasks.
"Show me the cup": Reference with Continuous Representations
Jun 28, 2016
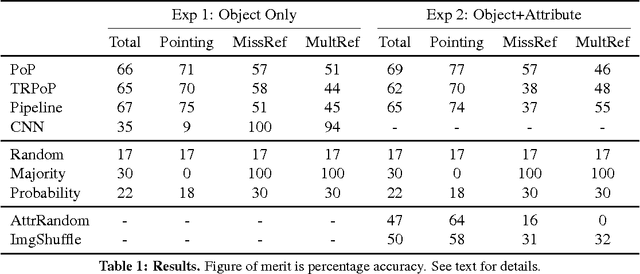

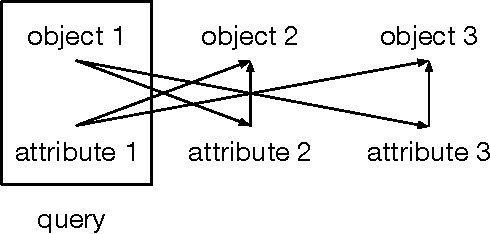
One of the most basic functions of language is to refer to objects in a shared scene. Modeling reference with continuous representations is challenging because it requires individuation, i.e., tracking and distinguishing an arbitrary number of referents. We introduce a neural network model that, given a definite description and a set of objects represented by natural images, points to the intended object if the expression has a unique referent, or indicates a failure, if it does not. The model, directly trained on reference acts, is competitive with a pipeline manually engineered to perform the same task, both when referents are purely visual, and when they are characterized by a combination of visual and linguistic properties.
The LAMBADA dataset: Word prediction requiring a broad discourse context
Jun 20, 2016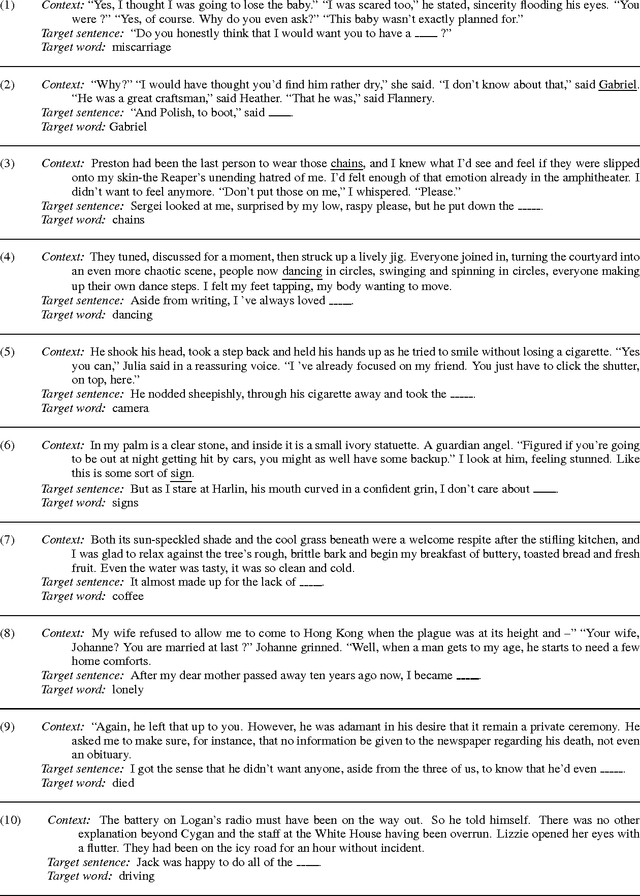
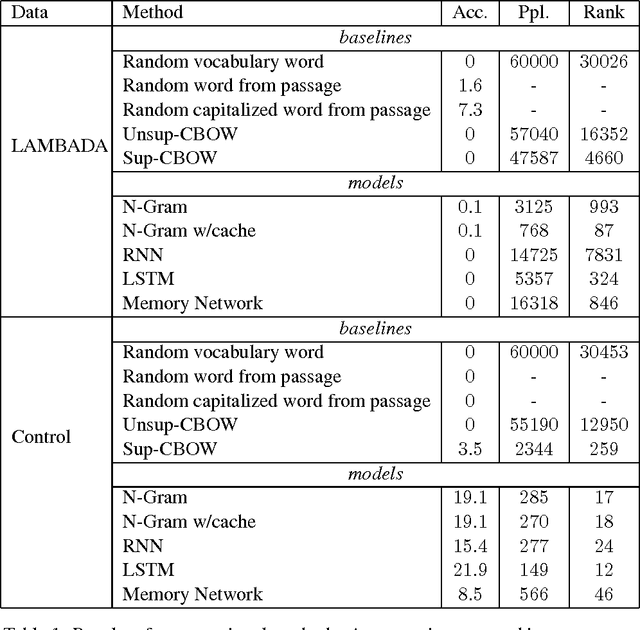
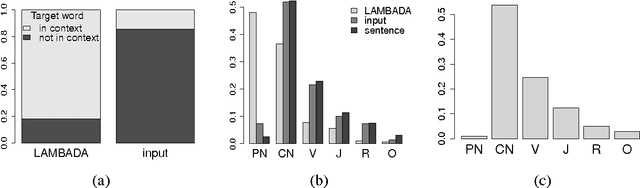
We introduce LAMBADA, a dataset to evaluate the capabilities of computational models for text understanding by means of a word prediction task. LAMBADA is a collection of narrative passages sharing the characteristic that human subjects are able to guess their last word if they are exposed to the whole passage, but not if they only see the last sentence preceding the target word. To succeed on LAMBADA, computational models cannot simply rely on local context, but must be able to keep track of information in the broader discourse. We show that LAMBADA exemplifies a wide range of linguistic phenomena, and that none of several state-of-the-art language models reaches accuracy above 1% on this novel benchmark. We thus propose LAMBADA as a challenging test set, meant to encourage the development of new models capable of genuine understanding of broad context in natural language text.