 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the quantification of the semantic information encoded in written language
Jul 27, 2009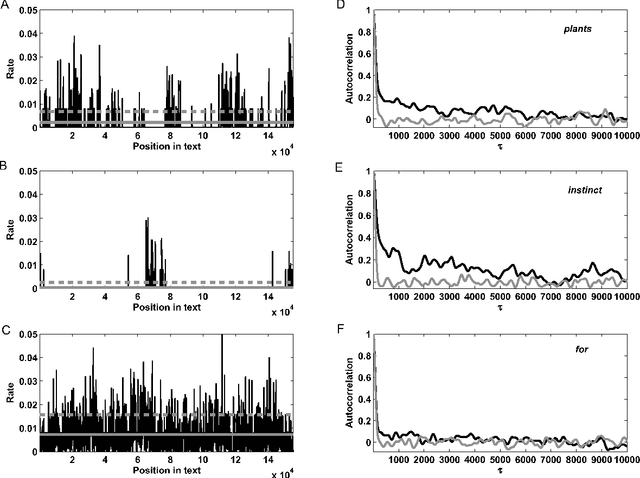


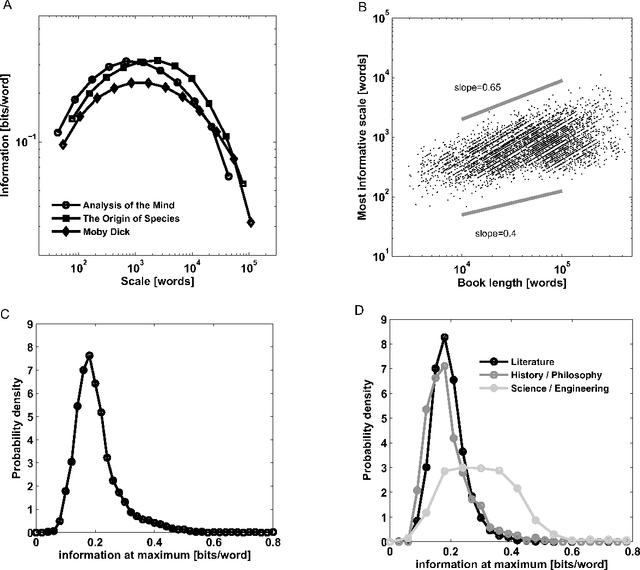
Written language is a complex communication signal capable of conveying information encoded in the form of ordered sequences of words. Beyond the local order ruled by grammar, semantic and thematic structures affect long-range patterns in word usage. Here, we show that a direct application of information theory quantifies the relationship between the statistical distribution of words and the semantic content of the text. We show that there is a characteristic scale, roughly around a few thousand words, which establishes the typical size of the most informative segments in written language. Moreover, we find that the words whose contributions to the overall information is larger, are the ones more closely associated with the main subjects and topics of the text. This scenario can be explained by a model of word usage that assumes that words are distributed along the text in domains of a characteristic size where their frequency is higher than elsewhere. Our conclusions are based on the analysis of a large database of written language, diverse in subjects and styles, and thus are likely to be applicable to general language sequences encoding complex information.
* 19 pages, 4 figures
Long-range fractal correlations in literary corpora
Jan 09, 2002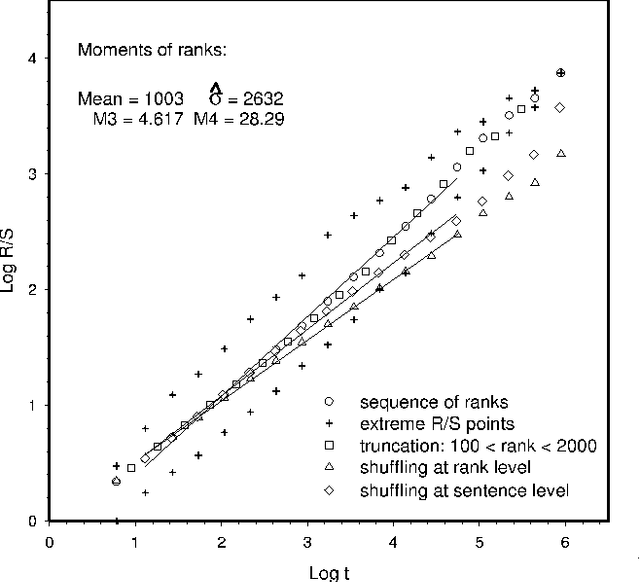
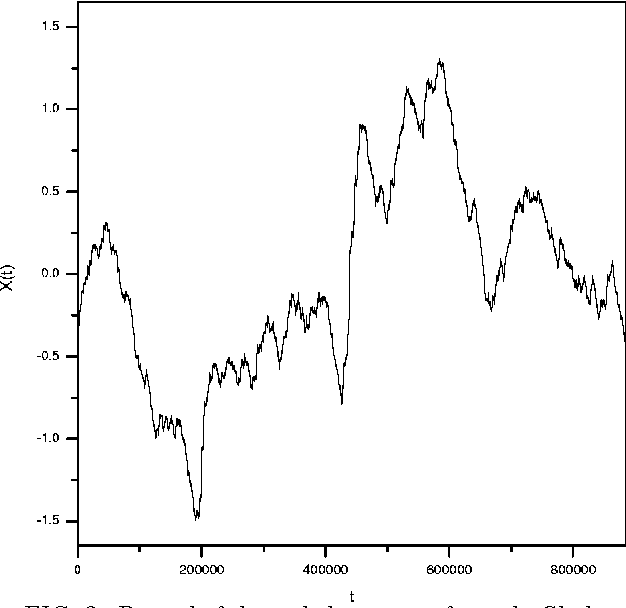
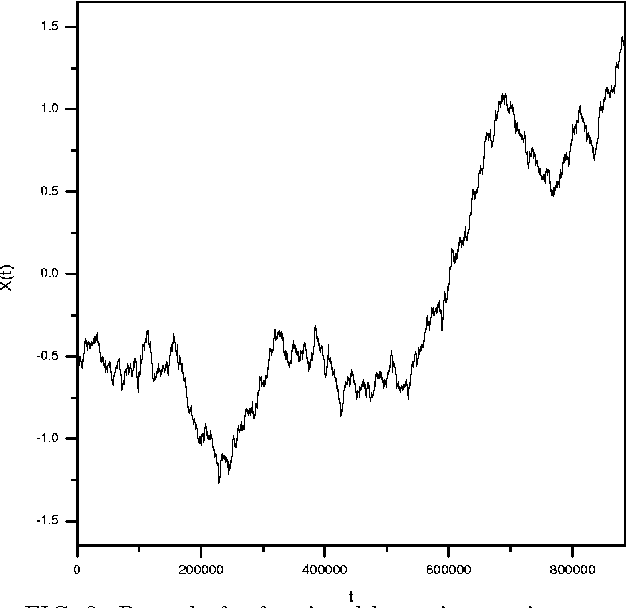
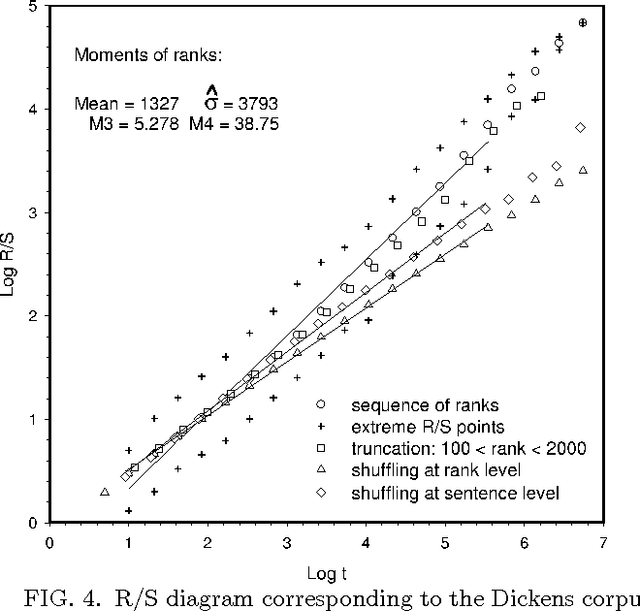
In this paper we analyse the fractal structure of long human-language records by mapping large samples of texts onto time series. The particular mapping set up in this work is inspired on linguistic basis in the sense that is retains {\em the word} as the fundamental unit of communication. The results confirm that beyond the short-range correlations resulting from syntactic rules acting at sentence level, long-range structures emerge in large written language samples that give rise to long-range correlations in the use of words.
* to appear in Fractals
Entropic analysis of the role of words in literary texts
Sep 12, 2001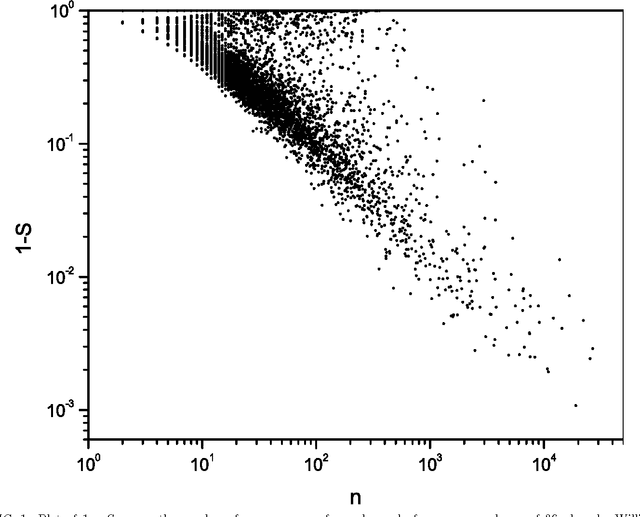
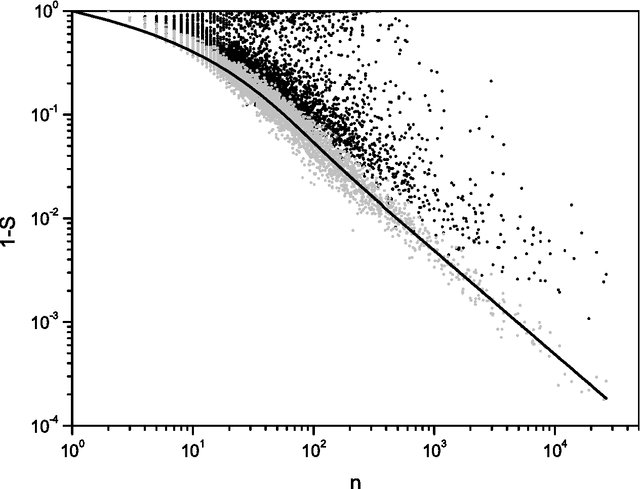
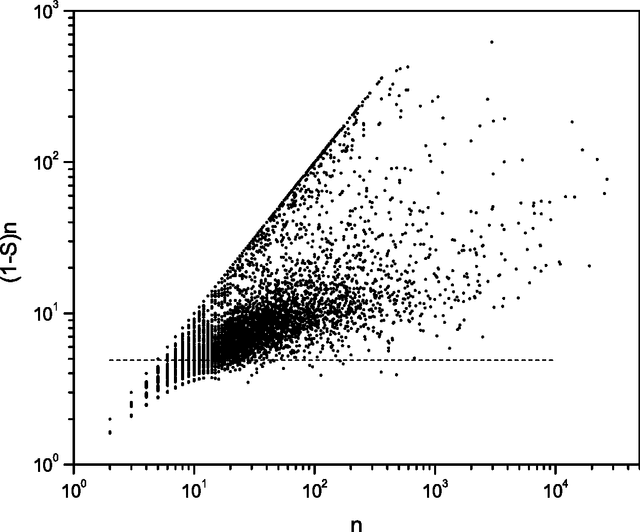
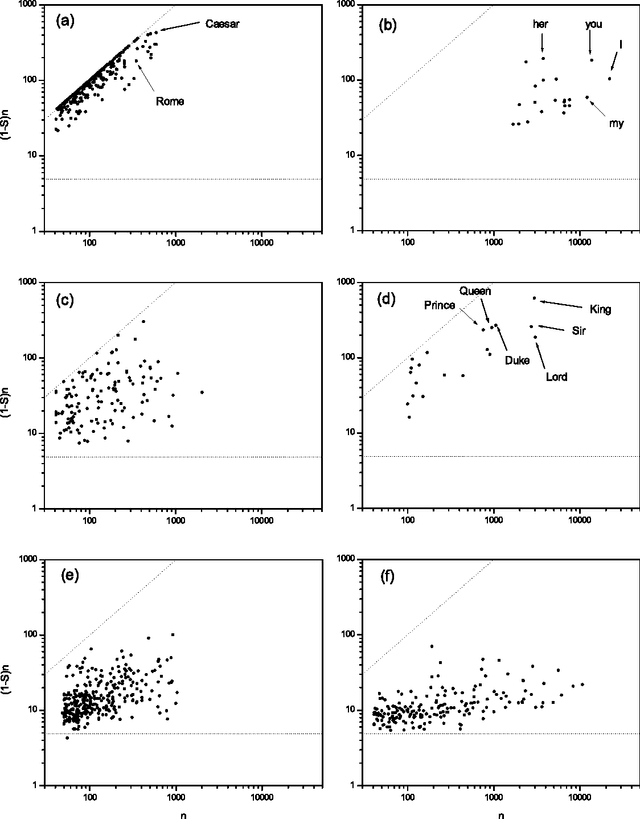
Beyond the local constraints imposed by grammar, words concatenated in long sequences carrying a complex message show statistical regularities that may reflect their linguistic role in the message. In this paper, we perform a systematic statistical analysis of the use of words in literary English corpora. We show that there is a quantitative relation between the role of content words in literary English and the Shannon information entropy defined over an appropriate probability distribution. Without assuming any previous knowledge about the syntactic structure of language, we are able to cluster certain groups of words according to their specific role in the text.
Beyond the Zipf-Mandelbrot law in quantitative linguistics
Jul 09, 2001

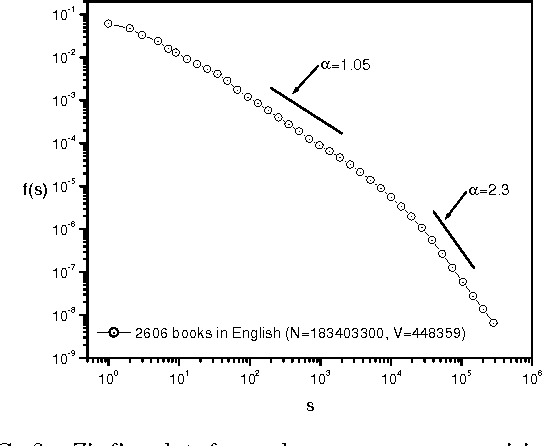
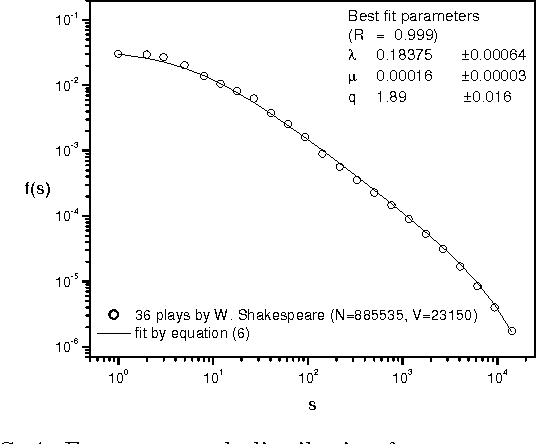
In this paper the Zipf-Mandelbrot law is revisited in the context of linguistics. Despite its widespread popularity the Zipf--Mandelbrot law can only describe the statistical behaviour of a rather restricted fraction of the total number of words contained in some given corpus. In particular, we focus our attention on the important deviations that become statistically relevant as larger corpora are considered and that ultimately could be understood as salient features of the underlying complex process of language generation. Finally, it is shown that all the different observed regimes can be accurately encompassed within a single mathematical framework recently introduced by C. Tsallis.