 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Predictive Analytics for Stocks in the Newsvendor Problem
Nov 16, 2025This work addresses a key challenge in inventory management by developing a stochastic model that describes the dynamic distribution of inventory stock over time without assuming a specific demand distribution. Our model provides a flexible and applicable solution for situations with limited historical data and short-term predictions, making it well-suited for the Newsvendor problem. We evaluate our model's performance using real-world data from a large electronic marketplace, demonstrating its effectiveness in a practical forecasting scenario.
Statistical keyword detection in literary corpora
May 30, 2008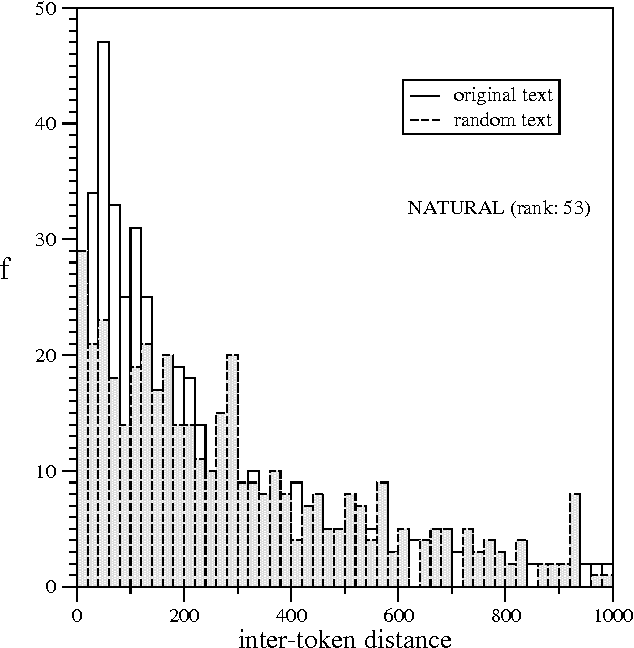
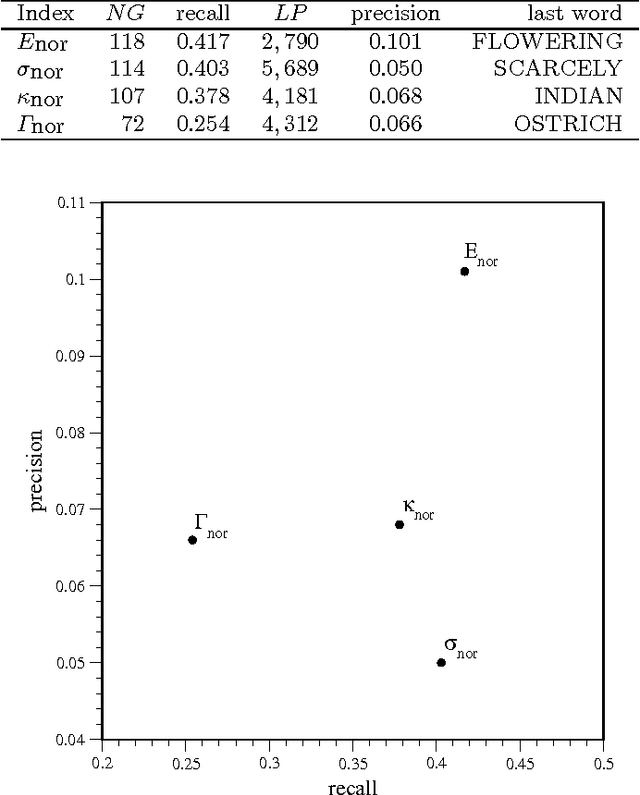

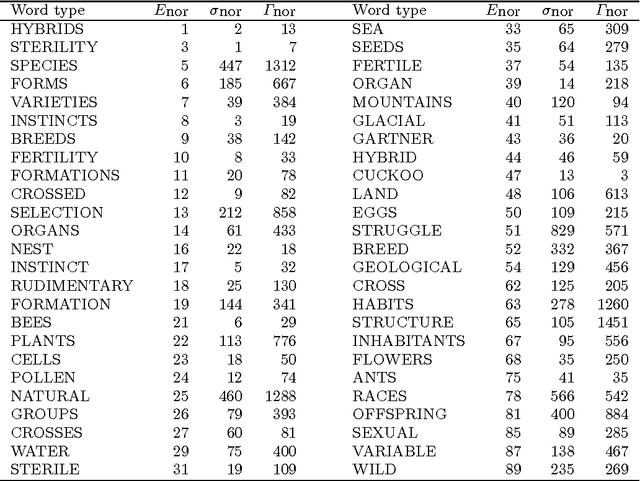
Understanding the complexity of human language requires an appropriate analysis of the statistical distribution of words in texts. We consider the information retrieval problem of detecting and ranking the relevant words of a text by means of statistical information referring to the "spatial" use of the words. Shannon's entropy of information is used as a tool for automatic keyword extraction. By using The Origin of Species by Charles Darwin as a representative text sample, we show the performance of our detector and compare it with another proposals in the literature. The random shuffled text receives special attention as a tool for calibrating the ranking indices.
* Published version. 11 pages, 7 figures. SVJour for LaTeX2e
Long-range fractal correlations in literary corpora
Jan 09, 2002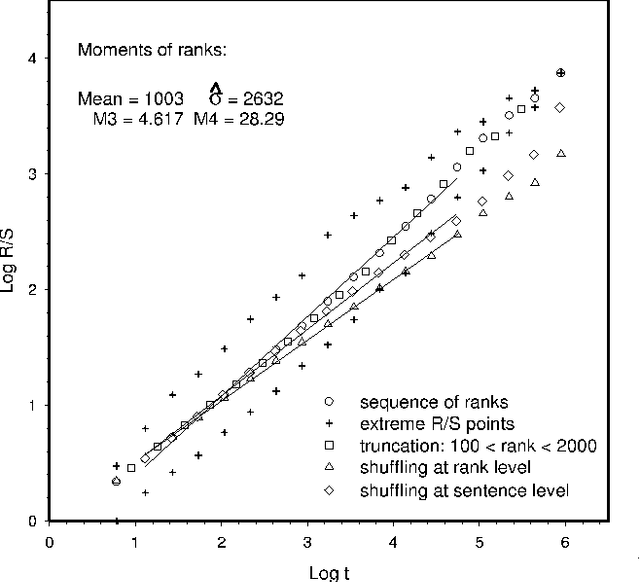
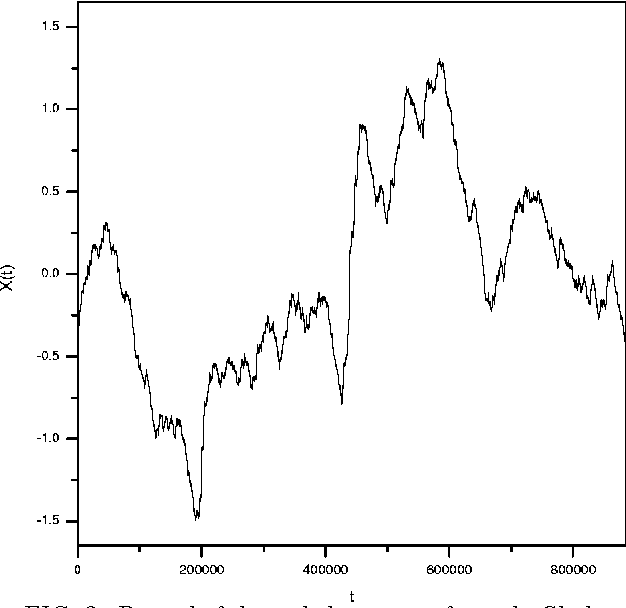
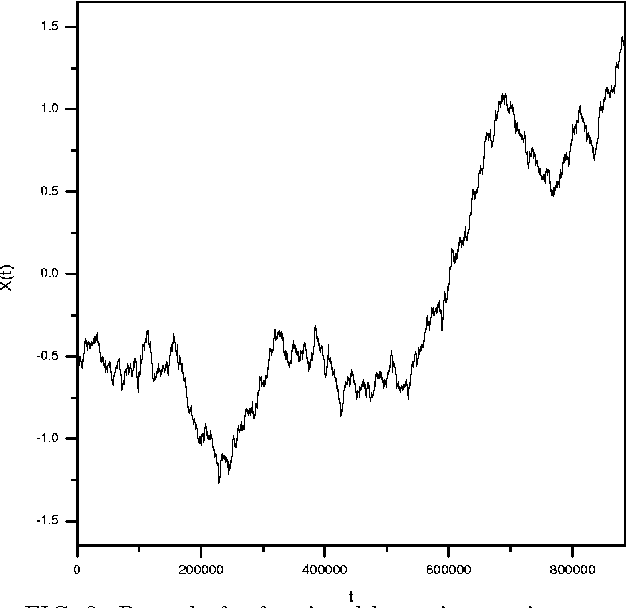
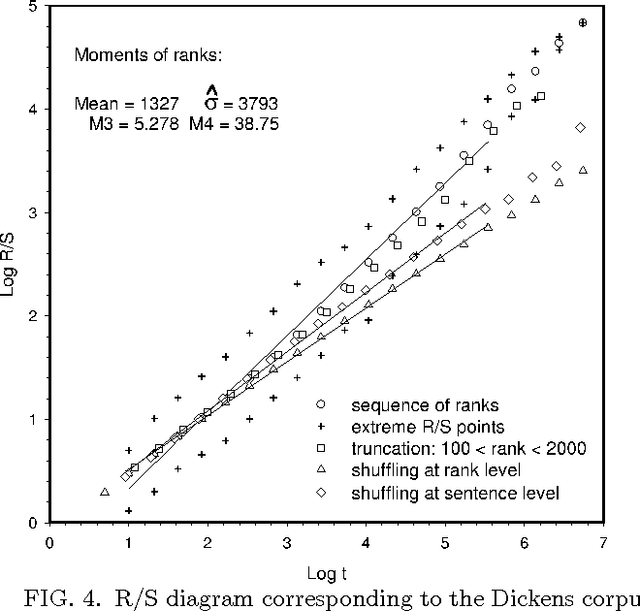
In this paper we analyse the fractal structure of long human-language records by mapping large samples of texts onto time series. The particular mapping set up in this work is inspired on linguistic basis in the sense that is retains {\em the word} as the fundamental unit of communication. The results confirm that beyond the short-range correlations resulting from syntactic rules acting at sentence level, long-range structures emerge in large written language samples that give rise to long-range correlations in the use of words.
* to appear in Fractals