Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropic analysis of the role of words in literary texts
Paper and Code
Sep 12, 2001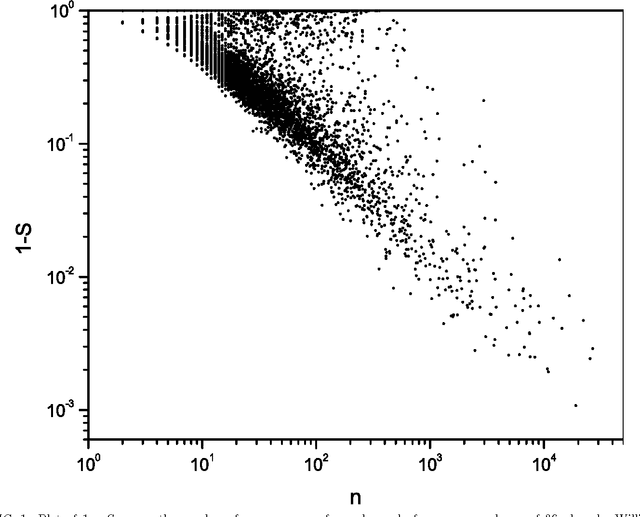
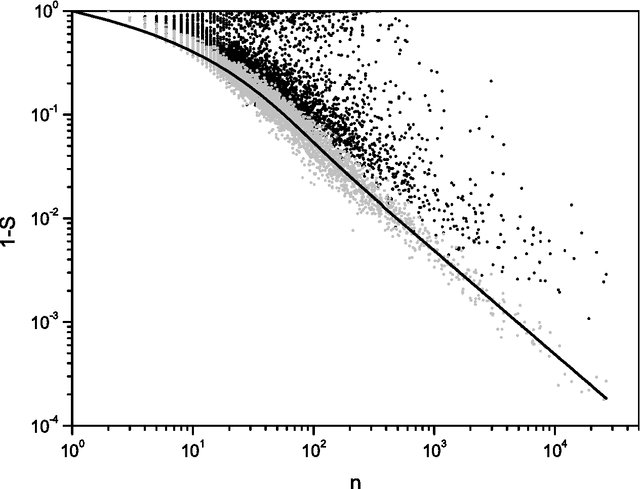
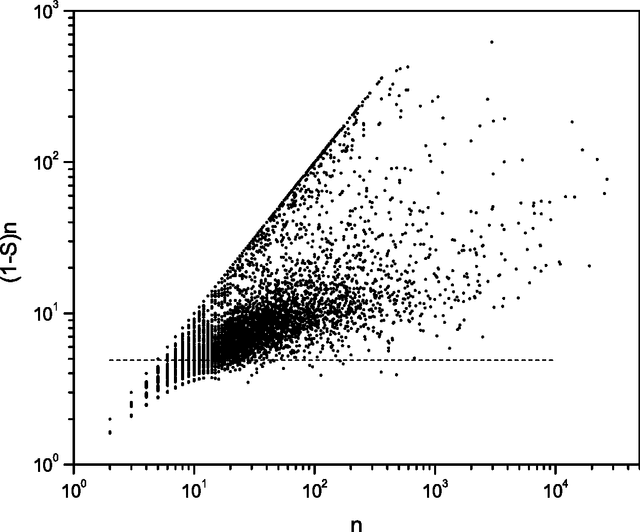
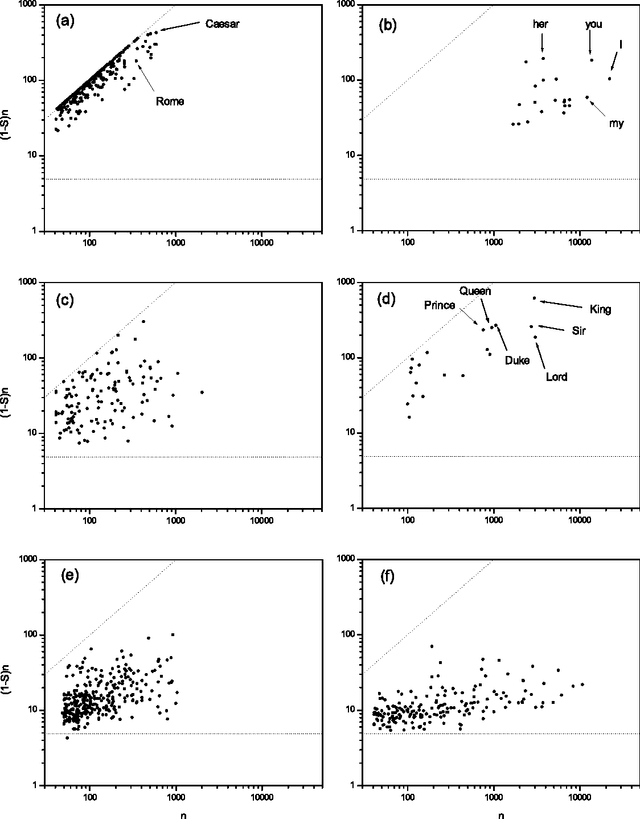
Beyond the local constraints imposed by grammar, words concatenated in long sequences carrying a complex message show statistical regularities that may reflect their linguistic role in the message. In this paper, we perform a systematic statistical analysis of the use of words in literary English corpora. We show that there is a quantitative relation between the role of content words in literary English and the Shannon information entropy defined over an appropriate probability distribution. Without assuming any previous knowledge about the syntactic structure of language, we are able to cluster certain groups of words according to their specific role in the text.
* 9 pages, 5 figures
View paper on