 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgesEMG-based Hand Gesture Recognition with Deep Learning
Jun 19, 2023Hand gesture recognition based on surface electromyographic (sEMG) signals is a promising approach for developing Human-Machine Interfaces (HMIs) with a natural control, such as intuitive robot interfaces or poly-articulated prostheses. However, real-world applications are limited by reliability problems due to motion artefacts, postural and temporal variability, and sensor re-positioning. This master thesis is the first application of deep learning on the Unibo-INAIL dataset, the first public sEMG dataset exploring the variability between subjects, sessions and arm postures by collecting data over 8 sessions of each of 7 able-bodied subjects executing 6 hand gestures in 4 arm postures. Recent studies address variability with strategies based on training set composition, which improve inter-posture and inter-day generalization of non-deep machine learning classifiers, among which the RBF-kernel SVM yields the highest accuracy. The deep architecture realized in this work is a 1d-CNN inspired by a 2d-CNN reported to perform well on other public benchmark databases. On this 1d-CNN, various training strategies based on training set composition were implemented and tested. Multi-session training proves to yield higher inter-session validation accuracies than single-session training. Two-posture training proves the best postural training (proving the benefit of training on more than one posture) and yields 81.2% inter-posture test accuracy. Five-day training proves the best multi-day training, yielding 75.9% inter-day test accuracy. All results are close to the baseline. Moreover, the results of multi-day training highlight the phenomenon of user adaptation, indicating that training should also prioritize recent data. Though not better than the baseline, the achieved classification accuracies rightfully place the 1d-CNN among the candidates for further research.
TCN Mapping Optimization for Ultra-Low Power Time-Series Edge Inference
Mar 24, 2022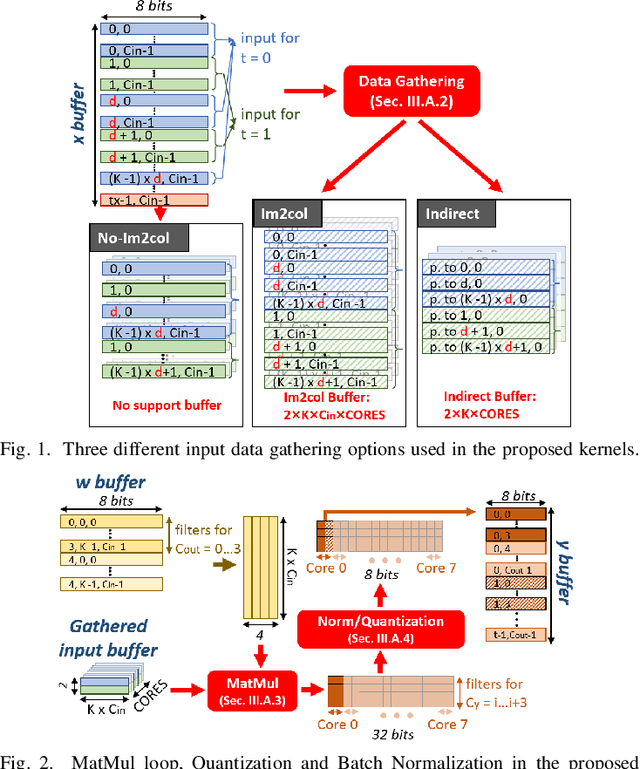
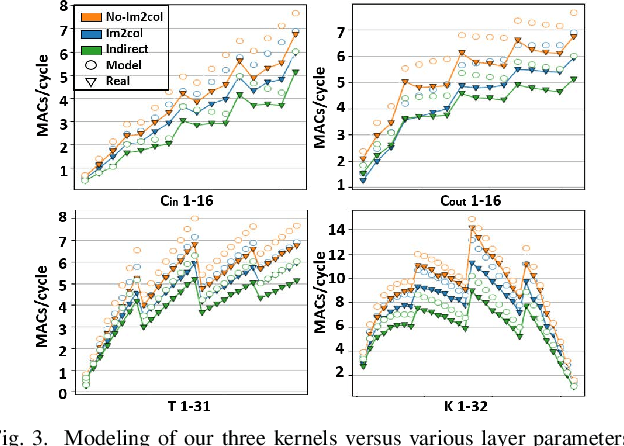
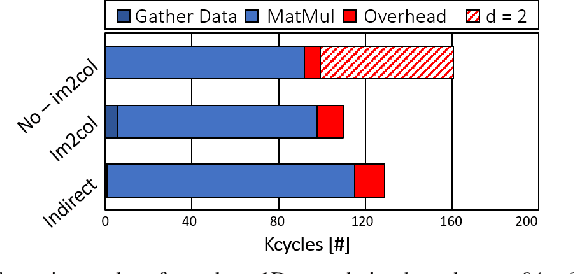
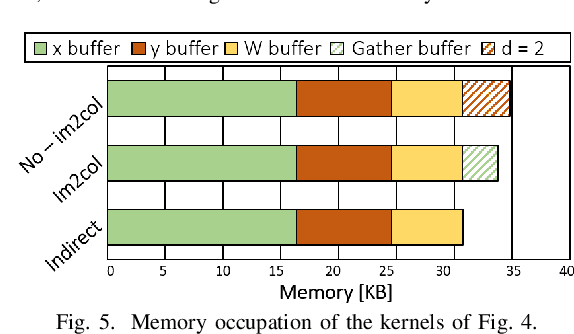
Temporal Convolutional Networks (TCNs) are emerging lightweight Deep Learning models for Time Series analysis. We introduce an automated exploration approach and a library of optimized kernels to map TCNs on Parallel Ultra-Low Power (PULP) microcontrollers. Our approach minimizes latency and energy by exploiting a layer tiling optimizer to jointly find the tiling dimensions and select among alternative implementations of the causal and dilated 1D-convolution operations at the core of TCNs. We benchmark our approach on a commercial PULP device, achieving up to 103X lower latency and 20.3X lower energy than the Cube-AI toolkit executed on the STM32L4 and from 2.9X to 26.6X lower energy compared to commercial closed-source and academic open-source approaches on the same hardware target.